AI in Data Observability: Trends for 2026
Data observability is evolving rapidly in 2026, driven by AI. Here's what you need to know:
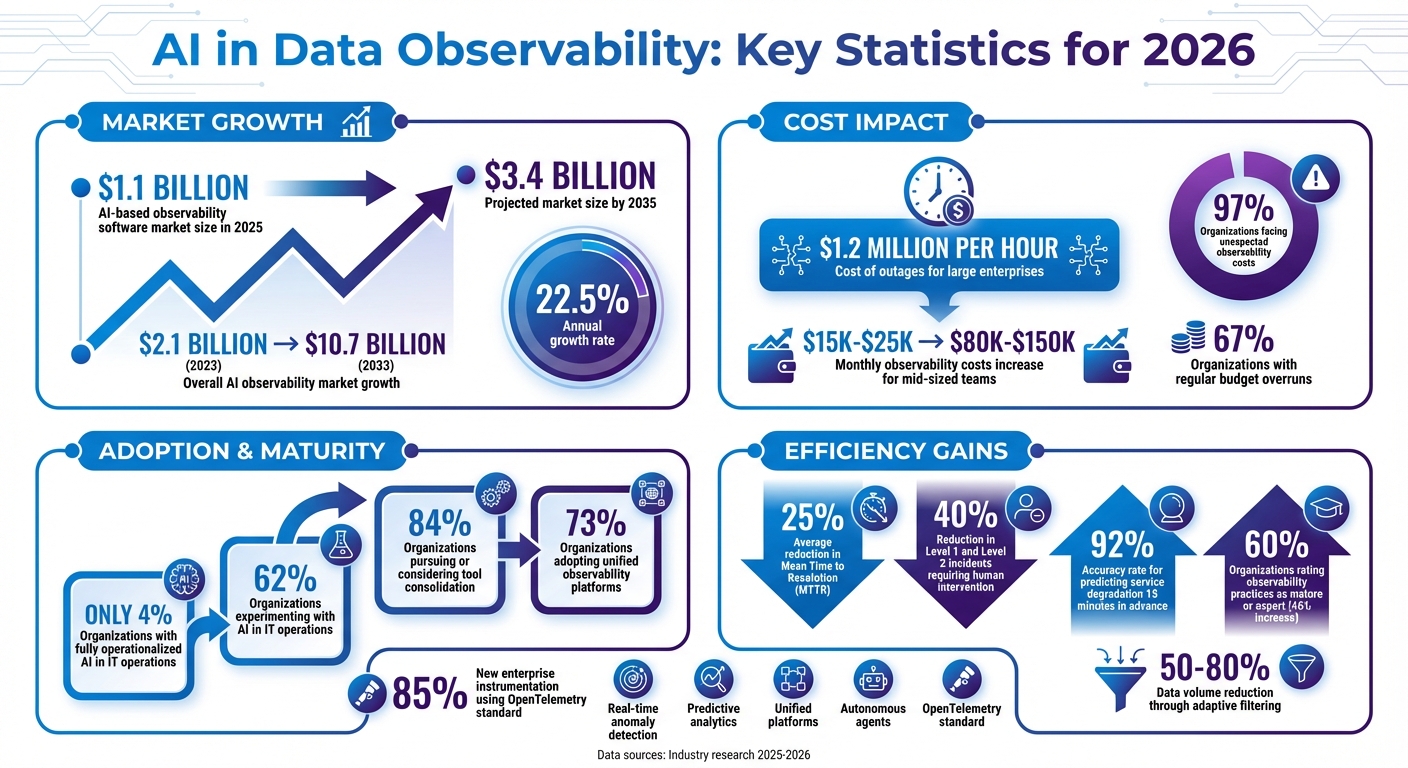
- AI-powered observability tools are now predicting and fixing issues before they happen, reducing costly outages that can exceed $1.2 million per hour for large enterprises.
- The market for AI-based observability software grew to $1.1 billion in 2025 and is expected to reach $3.4 billion by 2035.
- Key advancements include real-time anomaly detection, predictive analytics, and the rise of unified platforms that consolidate metrics, logs, and traces into one system.
- Autonomous agents are transforming monitoring by self-healing systems and reducing human intervention in resolving incidents.
- Open standards like OpenTelemetry are simplifying integrations and improving monitoring across AI systems.
These trends are helping businesses cut costs, improve reliability, and prepare for the growing complexity of AI-driven systems. But only 4% of organizations have fully operationalized AI in IT operations, leaving room for improvement.
This article explores how AI is reshaping observability, with insights on new tools, cost management strategies, and the shift toward automation.
AI Data Observability Market Growth and Key Statistics 2025-2035
2026 Predictions: The Future of AI and Observability | In the Sphere
sbb-itb-903b5f2
Key Trends in AI-Driven Data Observability for 2026
The evolution of observability is unfolding in four stages: visibility, correlation, prediction, and action. With the growing complexity of infrastructure, AI is speeding up this transformation. As organizations adapt, three key trends are shaping how they monitor and manage their data systems in 2026.
Real-Time Anomaly Detection Using AI
Anomaly detection has come a long way from basic threshold-based alerts. Today, transformer-based models are identifying unusual patterns across microservices. A prime example is DataDog's 8.x engine, launched in late 2025, which can predict service degradation up to 15 minutes before it impacts users - with a 92% accuracy rate. This gives teams a crucial window to act before problems escalate.
Modern tools are no longer just passive monitors; they act as "AI observability copilots." Middleware's OpsAI, for instance, not only detects errors but also performs root cause analysis and automates fixes. Similarly, New Relic's Groq AI-powered incident intelligence has reduced Mean Time to Resolution (MTTR) by an average of 25%.
Agent-level tracking is also tackling complex challenges like subtle failures, such as hallucinations or data drift, that traditional alerts might overlook. These systems trace the reasoning, tool calls, and decisions made by autonomous AI agents. To handle the surge in telemetry data, adaptive filtering retains only high-value signals, cutting data volume by 50%–80% while maintaining visibility needed for anomaly detection. These advancements are paving the way for a stronger focus on predictive analytics.
Predictive Analytics and Automated Insights
Building on the foundation of real-time anomaly detection, predictive analytics is enabling IT teams to move from reactive to proactive operations. By analyzing historical data and early warning signals, predictive tools can forecast incidents hours or even days in advance. These tools use linear and seasonal forecasting to distinguish between steady growth and cyclical patterns, helping teams anticipate resource exhaustion more accurately.
While 47% of IT leaders prioritize predictive analytics to preempt issues, only 4% of organizations have fully operationalized AI in IT operations as of 2026. Additionally, 59% of IT leaders are dissatisfied with their platforms' ability to turn raw telemetry into actionable insights.
The most advanced systems are going beyond basic predictions. Tools like Coralogix's Olly now autonomously investigate problems, correlate data across domains, and even suggest or execute fixes before anyone needs to intervene. As Dr. Evelyn Reed from CloudOps Futures puts it:
"In 2026, the question isn't whether you'll automate your ops, but how deeply. The market leaders are already leveraging AI to not just observe, but to predict and self-heal".
The Move to Unified Observability Platforms
To complement these advancements, organizations are shifting toward unified platforms that consolidate data streams for AI-driven insights. The days of juggling multiple dashboards for logs, metrics, and traces are fading, as teams once spent 40% of incident response time navigating between fragmented tools. Now, 84% of organizations are either pursuing or considering tool consolidation, and 73% have adopted or are transitioning to unified observability platforms.
This consolidation isn't just about streamlining workflows - it’s essential for AI systems. Autonomous tools like Coralogix's Olly rely on unified data layers to reason effectively, correlate signals, and make decisions. Fragmented data can lead to errors like AI hallucinations and incomplete workflows. OpenTelemetry (OTel) has been instrumental in this transition, with 85% of new enterprise instrumentation now using the standard to decouple data collection from vendor-specific tools.
Modern platforms are also leveraging high-performance columnar databases, such as ClickHouse, to store logs, metrics, and traces in a unified schema. This approach enables cross-signal analysis with standard SQL and reduces storage overhead by up to 10x compared to traditional solutions. As Dave Russell from Grafana Labs explains:
"Tool consolidation might be a driving force to standardize on observability, but the real shift is organizational: unified data powering unified decisions across the business".
New Technologies in Data Observability
Autonomous Agents and Self-Healing Data Systems
By 2026, data systems have evolved to self-heal before users even notice an issue. Autonomous agents are shifting observability from simple monitoring to proactive problem-solving, transforming how organizations deal with potential disruptions.
These advanced systems follow a tiered recovery approach. Initially, they inject corrective prompts to resolve minor issues. If that fails, they restore from serialized checkpoints using LangGraph. For more severe problems, they escalate to a cold restart, complete with a summary of completed tasks. In critical scenarios, CRIU is utilized to migrate the agent state seamlessly.
To prevent recurring breakdowns, the system identifies common failure patterns like:
- "The Repeater": Repeatedly executing the same tool without altering its state.
- "The Wanderer": Losing connection to its intended goal.
- "The Looper": Alternating between fixed actions without making progress.
When these patterns are detected, the system intervenes automatically, ensuring minimal user impact.
The benefits of such systems are already evident. For instance, PagerDuty's autonomous operations suite has reduced Level 1 and Level 2 incidents requiring human intervention by 40%. However, as Barr Moses, Co-founder and CEO of Monte Carlo, emphasizes:
"If you're deploying agents without a production-grade observability system that monitors context, performance, behavior and outputs, you're flying blind".
Alongside these breakthroughs, open standards are playing a critical role in unifying and enhancing observability practices.
Open Standards for Observability
In 2026, OpenTelemetry (OTel) has emerged as the universal standard for observability. The introduction of GenAI Semantic Conventions has streamlined the process of capturing data from LLM calls, agent actions, and tool executions. This standardization allows organizations to switch vendors without overhauling their instrumentation code.
AI frameworks like LangChain, CrewAI, and AutoGen now natively produce OTel-compliant spans, making it easier to trace decision-making across multi-agent pipelines. Tools like OpenLLMetry further simplify this process by automatically patching LLM SDKs from providers like OpenAI and Anthropic, offering instant observability coverage.
Another game-changer is the Model Context Protocol (MCP), which equips AI agents with essential business context, lineage, and governance metadata. This enables agents to operate autonomously rather than merely assist. As Marylia Gutierrez, a Principal Software Engineer and member of the OpenTelemetry Governance Committee, explains:
"OpenTelemetry didn't just unify formats, it unified the community. We're all solving problems together now instead of reinventing the same instrumentations".
These advancements in open standards are driving a proactive, AI-powered observability ecosystem, making it easier to manage increasingly complex data environments in 2026.
Cost Management and Efficiency in AI Observability
Budget Planning for Observability Tools in 2026
The cost dynamics of AI observability are evolving rapidly. AI systems now generate 10–100 times more telemetry data compared to traditional applications, causing monthly observability expenses for mid-sized teams (managing 10–20 AI features) to skyrocket from $15K–$25K to $80K–$150K. This surge is driven by intricate reasoning loops, frequent tool interactions, and detailed logs that result in massive data flows.
Unexpected costs are a common challenge - 97% of organizations have faced unforeseen observability expenses, and 67% report regular budget overruns. Jamie Mallers from OneUptime captures this shift perfectly:
"Your monitoring costs scale with your AI ambition, not your infrastructure footprint".
To manage these rising costs, organizations are rethinking their strategies. One effective method is model routing, where the majority of traffic (90%) is directed to cost-efficient models like Gemini 3 Flash ($0.50 per 1M input tokens), while reserving premium models like GPT-5.2 ($1.75 per 1M input tokens) for high-complexity tasks. This approach can reduce costs by 10–50 times per request.
Another cost-saving tactic is tool consolidation. By simplifying their tech stacks, organizations have cut vendor fees by roughly 30%. In fact, by 2026, 84% of IT leaders are either consolidating or planning to consolidate their observability tools to eliminate redundant costs.
Pricing models are also adapting. Instead of traditional per-GB ingestion fees - which discourage AI innovation - teams are shifting to "Bring Your Own Cloud" (BYOC) or self-hosted approaches. These models focus on actual compute and storage costs rather than data ingestion. Additionally, intelligent sampling techniques are gaining traction. By capturing all errors and anomalies but sampling just 5–10% of normal interactions, teams can reduce trace volumes by 80–90%.
These strategies not only help stabilize budgets but also streamline engineering workflows, setting the stage for more efficient and scalable operations.
Reducing Engineering Workload
AI observability tools aren't just about cutting costs - they're also transforming how engineers work. Traditionally, senior engineers spent 20–30% of their time maintaining integrations across various tools. On top of that, switching between multiple observability platforms increased incident resolution times by 20–40%. Unified platforms are now eliminating these inefficiencies.
One game-changer is autonomous root cause analysis. AI agents can now trace data lineage, analyze logs, and correlate events to pinpoint failure sources without human input. This automation significantly reduces Mean Time to Resolution (MTTR), allowing engineers to focus on developing new features instead of troubleshooting. It's no surprise that 60% of organizations now rate their observability practices as mature or expert, a sharp increase of 46% from the previous year.
The adoption of OpenTelemetry as a vendor-neutral standard has also simplified workflows. Engineers no longer need to duplicate instrumentation or rely on vendor-specific SDKs. Sean Porter from Grafana Labs sums it up well:
"The future of observability isn't about collecting everything. It's about keeping only the data worthy of attention".
This shift has led to the rise of adaptive telemetry, which filters out 50–80% of low-value data while preserving critical insights.
Another innovation is automated quality evaluation. Teams are using "LLM-as-judge" frameworks to automatically assess the quality, accuracy, and relevance of AI responses. Coupled with self-healing systems - which can rerun failed processes or adjust resources on the fly - these tools are fundamentally reshaping the engineering workload. Engineers are now free to focus on innovation rather than firefighting, making AI observability an essential part of modern development.
Conclusion: What's Next for AI in Data Observability
The AI observability market is set to expand significantly, growing from $2.1 billion in 2023 to an impressive $10.7 billion by 2033, with an annual growth rate of 22.5%. But the real story lies in the shift from reactive monitoring to fully autonomous IT operations. Arthur de Magalhaes, Senior Technical Staff Member for AIOps at IBM, highlights the stakes:
"In 2026 more aspects of the world will be managed by AI systems, which run on infrastructure that can fail in various ways".
The journey from basic AI assistants to autonomous agents capable of investigating, correlating, and resolving issues without human input is already underway. However, while 62% of organizations are experimenting with AI in IT operations, only 4% have achieved full production maturity as of early 2026. This highlights a significant gap that needs addressing.
A critical factor in bridging this gap is ensuring data quality and standardization. As the Coralogix team aptly notes, "In 2026, the organizations that thrive will be those that recognize that autonomy doesn't start with the UI. It starts with the data". OpenTelemetry has become a key enabler in this space, offering a vendor-neutral standard that allows teams to instrument once and integrate across multiple platforms. Meanwhile, 96% of IT leaders anticipate observability spending to either remain steady or increase through 2026-2027, with 62% planning specific budget increases. This trend underscores the importance of investing in observability, even amid economic challenges.
To prepare for this future, organizations need to focus on consolidating tools, enforcing data quality, and implementing guardrails before diving into full automation. These steps, combined with advancements like unified platforms and autonomous agents, are setting the stage for observability to become a strategic advantage. Companies that embrace this evolution will gain a competitive edge, driving faster innovation, reducing costs, and improving reliability.
FAQs
What should we instrument first to make AI observability work?
To ensure effective AI observability, the first step is focusing on the data layer - arguably the backbone of system reliability. By closely monitoring data quality, flow, and detecting anomalies early in the pipeline, you can stop small problems from snowballing into larger issues. This kind of proactive monitoring tackles challenges such as hallucinations or silent regressions head-on. It also aligns with advancements in automated anomaly detection and predictive analytics, helping to sustain trust and keep AI systems stable.
How do autonomous agents self-heal without breaking production?
Autonomous agents are designed to "self-heal" by relying on techniques like detection, diagnosis, and automated recovery. Tools such as heartbeat systems, circuit breakers, checkpointing, and graceful degradation play a key role in this process. These methods enable agents to identify and address challenges like semantic drift or deadlocks early, ensuring these issues don’t escalate and disrupt operations.
What’s the best way to control observability costs as telemetry explodes?
To keep observability costs in check as telemetry data expands, start with cost visibility. Understanding the cost of each request can help pinpoint areas for optimization. Implement machine learning-driven pipelines to filter and compress data, which can significantly reduce the amount of telemetry collected.
Leverage real-time cost analytics to monitor spending, set operational thresholds, and use targeted sampling to eliminate collecting redundant or unnecessary data. Platforms that integrate automation and focus on cost efficiency are key to maintaining control over growing telemetry expenses.