AI Infrastructure: Redundancy vs. High Availability
When building AI systems, reliability is non-negotiable. Downtime can cost businesses millions, especially in industries relying on real-time AI services. Two critical strategies - redundancy and high availability (HA) - help ensure systems stay functional, but they serve different purposes:
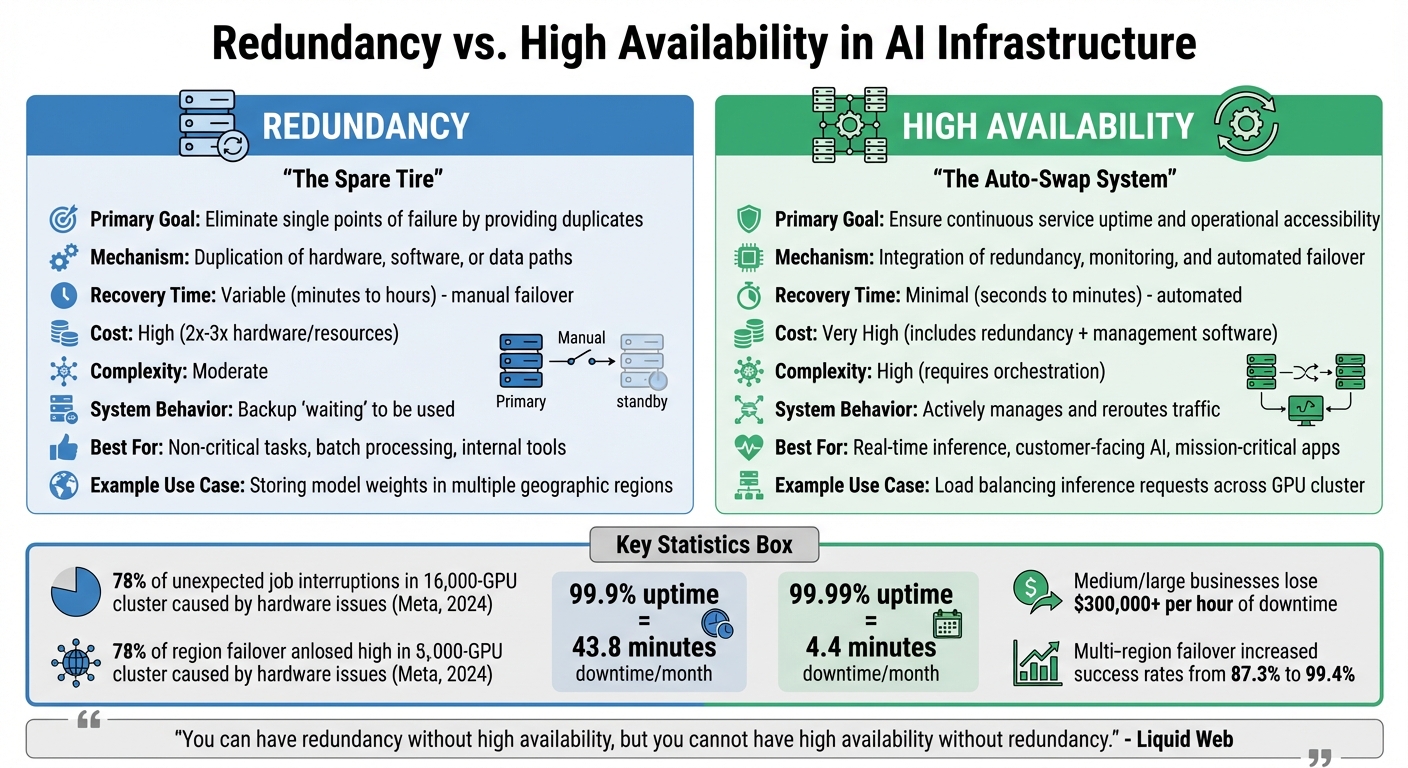
- Redundancy: Provides backups of critical components (e.g., GPUs, datasets) to prevent single points of failure. It's like having spare tires ready to replace a flat.
- High Availability: Automates failovers and ensures continuous service. Think of it as a system that instantly swaps the flat tire for you while driving.
Key points:
- Redundancy focuses on duplication, while HA emphasizes uptime through automated recovery.
- Redundancy is cost-effective but slower to recover. HA is faster but more expensive.
- Combining both approaches creates a more resilient system.
Quick Comparison:
| Feature | Redundancy | High Availability (HA) |
|---|---|---|
| Purpose | Backup for failures | Continuous uptime |
| Recovery Time | Slower (manual or semi-auto) | Fast (automated) |
| Cost | Moderate | High (includes redundancy costs) |
| Use Case | Non-critical tasks | Real-time, critical applications |
The choice depends on your system's tolerance for downtime, budget, and workload importance. For maximum reliability, redundancy and HA should work together.
Redundancy vs High Availability in AI Infrastructure: Key Differences
High Availability and Redundancy | Exclusive Lesson
sbb-itb-903b5f2
What Is Redundancy in AI Infrastructure?
In AI infrastructure, redundancy acts as a safeguard against hardware failures, stepping in before high availability techniques are needed. It involves running multiple identical copies of critical system components to prevent single points of failure. If one component fails, others step in to keep operations running smoothly. This concept applies to GPU-enabled virtual machines, containers, training datasets, model weights, load balancers, and network connections.
For example, when a GPU node crashes during training or an inference server goes offline, redundancy ensures that the failure is contained to that specific component. This prevents the issue from escalating into a full system outage. A study by Meta in 2024 revealed that 78% of unexpected job interruptions in a 16,000-GPU cluster were caused by hardware issues like GPU malfunctions, NVLink errors, and backend network problems.
How Redundancy Works
Redundancy relies on multi-layer replication across various failure domains, such as virtual machines, availability zones, and even geographic regions. Load balancers like HAProxy, NGINX, or Azure Front Door play a key role by distributing traffic across redundant nodes. These load balancers continuously check the health of nodes, automatically rerouting traffic to functional ones when failures are detected.
For training tasks, redundancy often takes the form of checkpointing. This involves saving the model state at regular intervals (every 30–60 minutes), allowing training to resume from the latest checkpoint if a failure occurs. Organizations also maintain "warm spares" - spare capacity ready to replace faulty hardware quickly. Redundant nodes access shared storage systems like NFS, Ceph, or cloud object storage to ensure consistency in model files.
In 2024, Nebius reported that a customer running a 3,000-GPU production cluster achieved 169,800 GPU hours (or 56.6 hours of stable operation) by using automated fault handling combined with a dedicated buffer of spare GPU capacity.
Benefits of Redundancy for AI Systems
Redundancy offers three key benefits. First, it provides fault tolerance, allowing systems to operate in a degraded state rather than failing entirely. Second, it prevents permanent data loss by replicating essential elements like training datasets, model weights, and checkpoints. Third, it enables zero-downtime deployments, making it possible to update one instance while others continue handling traffic.
For non-critical tasks like batch processing or model training, redundancy is particularly effective. These workloads can often tolerate minor interruptions or function with fewer replicas while issues are resolved. That said, there’s a cost-efficiency limit: using more than three spares typically yields diminishing returns in availability improvements. Designing compute layers to be stateless also helps, as it allows individual nodes to be replaced without risking data loss.
Next, we’ll explore high availability, which works alongside redundancy to further reduce downtime through automated monitoring and failover mechanisms.
What Is High Availability in AI Infrastructure?
High availability (HA) is a system design strategy focused on minimizing downtime. Its purpose is to ensure that AI services remain accessible and functional even when individual components fail. While redundancy involves having backup components in place, HA goes a step further by using automated recovery processes to maintain uninterrupted operation. The ultimate goal? Keep AI applications running with as little downtime as possible.
For AI workloads, HA is achieved by distributing models across multiple nodes and geographic regions. This setup helps tackle challenges like hardware failures, network disruptions, or regional quota limits. If a node fails, automated rerouting kicks in, reducing costly downtime - a critical factor, as downtime can have significant financial impacts. Below, we break down how HA systems work to maintain continuous service.
How High Availability Works
HA systems rely on a combination of mechanisms working in sync. Automated failover and continuous heartbeat monitoring are key components, ensuring traffic is redirected immediately when failures occur.
In active-active configurations, traffic is handled simultaneously across multiple nodes. This setup not only supports horizontal scaling but also enables near-instant failover. For example, a 2026 implementation of multi-region failover for Azure OpenAI saw success rates jump from 87.3% to 99.4% by dynamically rerouting traffic around regions experiencing rate limits.
However, AI systems face unique challenges that standard HA methods may not fully resolve. For instance, HTTP 429 errors ("Too Many Requests") often signal quota exhaustion rather than outright service failure. Addressing this requires intelligent API management to shift traffic to regions with available capacity. Similarly, failover during streaming responses (like those delivered via Server-Sent Events) can disrupt the user experience, making swift client-side retries essential.
Benefits of High Availability for AI Systems
These strategies provide clear operational advantages for AI applications.
HA ensures uninterrupted service for real-time inference and API endpoints, where even brief outages can harm user experience. Automation enables faster recovery by detecting failures and switching to healthy nodes in seconds. This is especially crucial in production environments where uptime guarantees are non-negotiable.
The difference in availability levels has tangible business implications. For instance, achieving "Three Nines" (99.9% uptime) translates to about 43.8 minutes of downtime per month. In contrast, "Four Nines" (99.99% uptime) reduces downtime to just 4.4 minutes. As Anisha Padamshi from Couchbase explains:
High availability refers to a system's ability to remain accessible and operational for as close to 100% of the time as possible
. For critical AI applications - especially those powering customer-facing features or essential business operations - this distinction between minutes and hours of downtime can be the difference between maintaining user trust and losing customers.
Next, we’ll explore how HA compares with redundancy to determine the best approach for AI infrastructures.
Key Differences Between Redundancy and High Availability
When it comes to AI infrastructure, redundancy and high availability (HA) tackle different challenges. Redundancy focuses on duplication - think extra GPUs, storage drives, or model files as backups. High availability, on the other hand, is about coordination - it’s the system that ensures smooth operation by monitoring those backups and seamlessly switching to them when something fails.
Here’s an analogy: redundancy is like keeping a spare tire in your trunk, while HA is the automated system that detects a flat and swaps the tire for you. As Nawaz Dhandala from OneUptime puts it:
High availability is not about preventing failures. It is about designing systems that continue serving users when components fail
. This distinction plays a major role in how resilient and cost-effective a system is.
From a cost perspective, redundancy alone - like running dual AI API servers - can double computing expenses. Implementing full HA with automated failover increases costs even further, often tripling them due to the need for load balancers, monitoring tools, and geographically distributed resources. These costs are justified by the stakes: medium and large businesses can lose over $300,000 for every hour of downtime, and losses in the automotive sector soar to $2.3 million per hour.
Recovery time is another key difference. In redundant systems, manual failover can take anywhere from minutes to hours, depending on how quickly engineers can intervene. In contrast, HA systems use automation to cut that downtime to seconds or minutes, meeting strict service level agreements (SLAs). For AI systems managing real-time customer interactions, those seconds are crucial - Fortune 500 companies collectively lose $1.4 trillion annually to unscheduled downtime, which equates to about 11% of their revenue.
Comparison Table: Redundancy vs. High Availability
| Feature | Redundancy | High Availability (HA) |
|---|---|---|
| Primary Goal | Eliminate single points of failure by providing duplicates | Ensure continuous service uptime and operational accessibility |
| Mechanism | Duplication of hardware, software, or data paths | Integration of redundancy, monitoring, and automated failover |
| Recovery Time | Variable; can be slow if failover is manual | Minimal; typically automated to meet strict SLAs |
| Cost | High (requires 2x or 3x the hardware/resources) | Very High (includes redundancy costs plus management software) |
| Complexity | Moderate (managing duplicate assets) | High (requires complex orchestration and synchronization) |
| System Behavior | Provides a backup "waiting" to be used | Actively manages and reroutes traffic to maintain service |
| AI Use Case | Storing model weights in multiple geographic regions | Load balancing inference requests across a GPU cluster |
When to Choose Redundancy or High Availability in AI
Deciding between redundancy and high availability comes down to aligning your infrastructure with your specific needs. The key factors to weigh include how much downtime your system can tolerate, your budget, and how critical your AI workload is to your business. These considerations help shape the right approach for ensuring reliability.
Factors to Consider
Your choice between redundancy and high availability hinges on balancing costs, service level agreements (SLAs), and the criticality of your workload.
Budget Constraints:
Redundancy typically costs less upfront but comes with longer recovery times. On the other hand, implementing high availability with automated failover can be significantly more expensive. For instance, moving from 99.9% uptime to 99.99% can double your costs, while achieving 99.999% uptime might triple them.
Service Level Agreements (SLAs):
SLAs define acceptable downtime. For example:
- 99.9% uptime allows for about 8.76 hours of downtime annually.
- 99.99% uptime reduces that to roughly 52.6 minutes per year.
- 99.999% uptime limits downtime to just 5.3 minutes annually.
Workload Criticality:
The importance of your AI workload plays a significant role. For internal tools, longer recovery times might be manageable. But for production AI services, where downtime directly affects revenue, higher availability is crucial. Consider this: 90% of medium and large businesses report losses exceeding $300,000 per hour of downtime, and in the automotive sector, losses can climb to $2.3 million per hour.
Recovery Time Objective (RTO):
If your system can tolerate minutes of downtime, high availability may suffice. However, for workloads where even a few seconds of interruption are unacceptable, fault-tolerant systems are the better choice.
Comparison Table: Advantages and Disadvantages
Here’s a quick breakdown of the strengths and weaknesses of different approaches:
| Approach | Advantages | Disadvantages | Best Use Cases |
|---|---|---|---|
| Redundancy (Backups/Cold Standby) | Affordable; easy to set up; protects against data loss | Recovery times are longer; often requires manual intervention | Ideal for internal tools, test environments, or non-critical workloads |
| High Availability (Active-Passive) | Moderate cost; automated failover within seconds or minutes; meets most SLAs | Standby resources are idle; more complex than basic backups | Suited for business productivity tools and professional AI services |
| High Availability (Active-Active) | No idle resources; instant failover; supports horizontal scaling | Higher costs; requires intricate synchronization and orchestration | Best for high-traffic AI services, real-time inference, and customer-facing platforms |
| Fault Tolerance | Zero downtime; seamless recovery; instant failover | Extremely expensive; complex to implement; often overkill for most needs | Essential for mission-critical systems like healthcare, financial trading, and autonomous vehicles |
The next section will explore how to combine these approaches effectively.
Implementing Redundancy and High Availability Together
Integrating redundancy with high availability creates a strong foundation for a resilient AI infrastructure. While redundancy ensures backup components are in place, high availability provides the tools to seamlessly switch to these backups if something goes wrong. Together, they eliminate single points of failure. Below are some strategies to combine these approaches effectively across your AI stack.
Strategies for Integration
Creating a dependable AI infrastructure requires layering multiple strategies. By combining global load balancing, regional failover, and multi-provider redundancy, you can build a system capable of handling failures without disrupting operations.
Multi-Region Architecture:
A practical example of this is a multi-region failover setup for Azure OpenAI, handling over 1 million requests daily. This system used Azure Front Door for global routing and Azure API Management for managing rate limits. Resources were deployed primarily in WestUS and SouthIndia, with secondary failover options in EastUS and CentralIndia. This approach boosted success rates during load testing from 87.3% (single-region) to 99.4%.
Multi-Provider Redundancy:
Relying on a single provider creates a vulnerability. A centralized gateway can standardize APIs from multiple AI providers - like OpenAI, Anthropic, and Google - allowing automatic failover. As Grizzly Peak Software highlights:
If your production system depends on a single LLM provider, you have a single point of failure that will eventually take your application down
. Tools like Bifrost can handle routing and failover in under 10 milliseconds.
Circuit Breaker Pattern:
This strategy prevents your system from continuously relying on a failing provider. A circuit breaker removes underperforming providers from the routing pool temporarily, giving them time to recover. Traffic is rerouted to healthier alternatives. Maxim AI underscores this point:
The question is not whether your primary LLM provider will fail. It is whether your system is designed to handle it
.
Shared Storage for Consistency:
To maintain consistency across redundant nodes, centralized storage solutions like NFS or Ceph are essential.
Use Cases for Combined Approaches
These strategies are critical for various real-world applications, where reliability and performance are non-negotiable.
Enterprise AI Services:
For platforms serving thousands of users daily, combining active-active deployments across regions with multi-provider failover ensures high reliability. Even a slight increase in P95 latency is acceptable when downtime costs exceed $300,000 per hour.
Mission-Critical AI Applications:
Industries like healthcare diagnostics, financial trading, and autonomous vehicles demand zero data loss and minimal downtime. These applications depend on fault-tolerant hardware, automated failover, and the 3-2-1 backup rule - maintaining three data copies on two storage types, with one stored off-site - to keep running smoothly.
Production AI Inference:
Real-time AI services benefit from active-active clusters where all instances process traffic simultaneously. Proactive health checks using lightweight prompts, such as "Respond with OK", ensure failures are detected early, enabling instant failover without the delays seen in active-passive setups.
Conclusion
When it comes to reliable AI infrastructure, redundancy and high availability are two sides of the same coin. Redundancy ensures backup systems are in place, while high availability focuses on automated detection and failover to keep things running smoothly. As Liquid Web aptly states:
"You can have redundancy without high availability, but you cannot have high availability without redundancy."
Together, these strategies work to minimize failure points and speed up recovery times, enabling uninterrupted AI operations.
To enhance reliability, aim to increase Mean Time Between Failures (MTBF) and decrease Mean Time to Recovery (MTTR). Redundancy reduces the risk of failure by eliminating single points of failure, while high availability improves recovery times with tools like automated failover and real-time monitoring.
Downtime is expensive - system outages can lead to steep financial losses. For real-time inference services or mission-critical AI applications, the cost of downtime far outweighs the investment in a robust infrastructure. Address vulnerabilities by removing single points of failure and automating recovery processes.
High availability isn’t a one-time setup - it’s an ongoing process of optimization and monitoring. Regularly simulate failures to validate your failover strategies, and implement load balancing to evenly distribute traffic across multiple nodes. For critical systems, consider geographic redundancy by placing backups in separate regions to protect against localized disasters.
While perfection is unattainable, the key is finding the right balance between cost, complexity, and reliability. Tailor your approach to fit the specific demands of your AI workload, ensuring a robust and resilient infrastructure.
FAQs
What uptime level (99.9% vs 99.99%) do I actually need?
When deciding on uptime requirements, it all comes down to what your service needs and how much downtime you can handle. For less critical systems, 99.9% uptime - which translates to roughly 8.76 hours of downtime per year - might be sufficient. On the other hand, 99.99% uptime - just about 52 minutes of downtime annually - is better suited for mission-critical services where even a short outage could lead to serious consequences. Think about how essential your system is, what your users expect, and how much risk you're willing to take to find the right balance between cost and reliability.
How do I set RTO targets for AI inference vs training?
To determine Recovery Time Objective (RTO) targets, it's crucial to address the unique demands of training and inference processes.
For training, longer RTOs - ranging from hours to even days - are generally acceptable. This is because training typically involves scheduled retraining sessions and checkpointing, which provide flexibility in recovery timelines.
On the other hand, inference, particularly in real-time applications, demands extremely short RTOs - often measured in seconds or minutes. Quick recovery is essential here to ensure uninterrupted service availability and maintain user satisfaction.
To meet these differing needs, adopt tailored strategies: leverage redundancy to safeguard inference operations and rely on checkpointing to support efficient recovery during training. Align these approaches with your operational priorities to balance performance and reliability effectively.
What’s the cheapest way to add automated failover to my AI stack?
The most budget-friendly way to integrate automated failover into your AI stack is by using AI-driven disaster recovery tools. These tools handle failover automatically, streamline resource use, and minimize downtime. On top of that, using infrastructure as code to design reusable, redundant templates and adopting multi-provider strategies can boost resilience without inflating costs. Together, these methods combine automation with redundancy, offering a failover system that's both reliable and cost-efficient.