Ultimate Guide to AI Model Robustness Testing
AI model robustness is about how well a system performs when faced with challenges like noisy data, unexpected scenarios, or deliberate attacks. High accuracy in controlled settings doesn't guarantee reliable performance in unpredictable situations. This guide covers how to test and improve robustness for AI models, focusing on areas like:
- Handling unexpected data (out-of-distribution performance)
- Dealing with noisy or corrupted inputs
- Resisting adversarial attacks
- Maintaining consistent performance across varied conditions
Key Takeaways:
- Why it Matters: Failures in critical fields like healthcare or finance can lead to safety risks or financial losses.
- Core Dimensions: Focus on out-of-distribution, corruption, adversarial resilience, and stability.
- Metrics to Use: Robust accuracy, calibration scores, error-handling rates, and resource performance tracking.
- Testing Strategies: Use realistic scenarios, automated tools, and prioritize high-risk failure modes.
- Tools: Platforms like NanoGPT, Foolbox, and Adversarial Robustness Toolbox simplify testing.
Testing ensures AI systems can handle messy, unpredictable environments, reducing risks and improving reliability. The article explores practical methods, tools, and metrics to help you test and refine your AI models effectively.
ATRASS Seminar #4: A unifying approach for performance bias and robustness testing in AI
Core Dimensions and Metrics for Robustness Testing
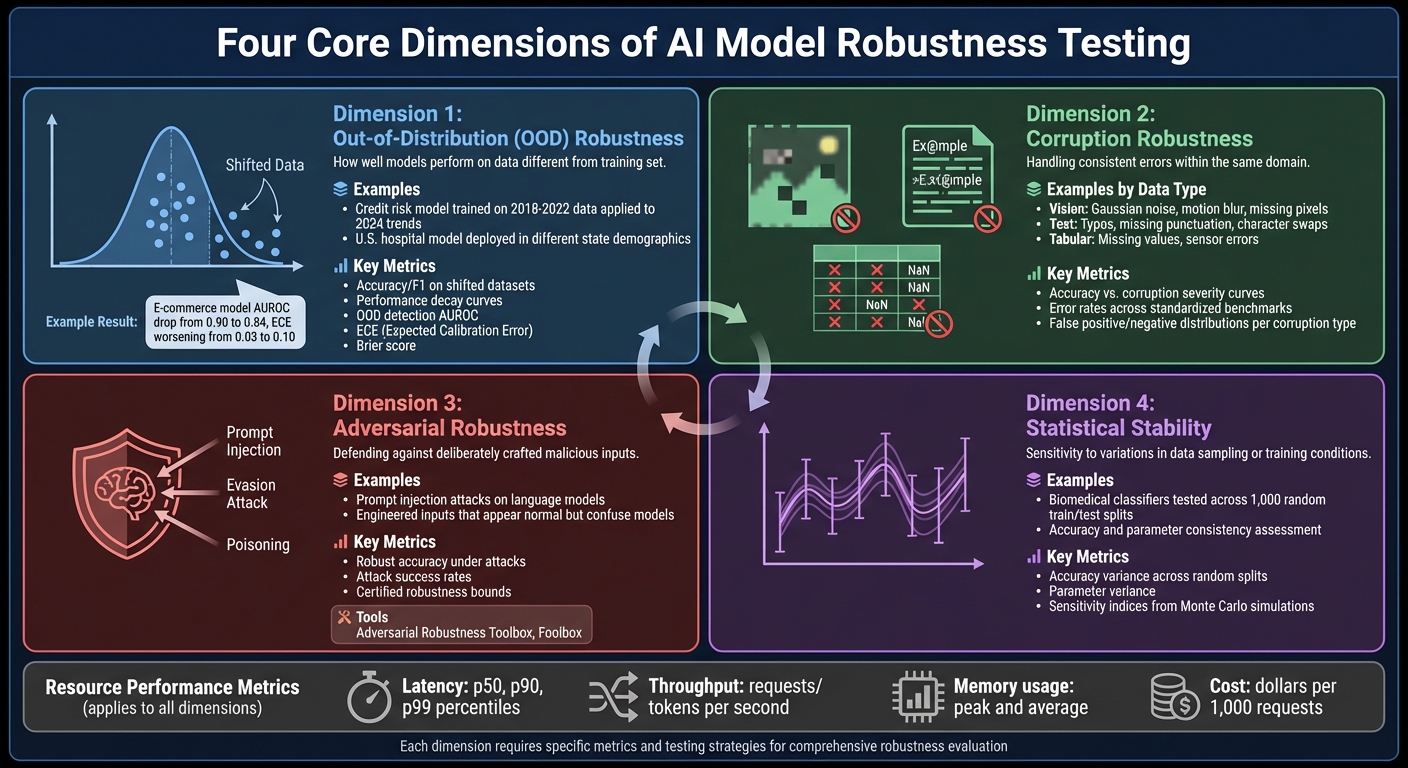
Four Core Dimensions of AI Model Robustness Testing
Key Dimensions of Robustness
When it comes to evaluating robustness, the focus is on identifying areas where real-world performance might falter. To do this effectively, robustness testing zeroes in on four main dimensions, each addressing specific types of failure scenarios.
Out-of-distribution (OOD) robustness evaluates how well a model performs when faced with data that differs from its training set. For instance, a credit risk model trained on economic data from 2018–2022 might struggle when applied to 2024's economic trends. Similarly, a U.S. hospital model deployed in a state with a different patient demographic could encounter challenges. The goal here is for the model to degrade gracefully, provide safe fallback mechanisms, and signal uncertainty when encountering unfamiliar data.
Corruption robustness deals with consistent errors within the same domain. For vision models, this could mean handling issues like Gaussian noise, motion blur, or missing pixels. Text models might face typos, missing punctuation, or character swaps, while tabular data could include missing values or sensor errors. These scenarios mimic real-world data problems, such as a medical imaging system working with poor-quality images or an OCR tool processing blurry documents.
Adversarial robustness focuses on defending against deliberately crafted inputs designed to exploit model weaknesses. These inputs often appear normal but are engineered to confuse the model. For example, language models might face prompt injection attacks. Addressing this requires threat modeling and tools like the Adversarial Robustness Toolbox or Foolbox to simulate and test against such inputs.
Statistical stability examines how sensitive a model's performance is to variations in data sampling or training conditions. For example, a biomedical framework might test classifiers across 1,000 random train/test splits to assess accuracy and parameter consistency. High variance in results could indicate a model that’s unreliable and prone to unpredictable behavior in production.
Metrics for Measuring Robustness
To truly evaluate robustness, you need metrics that go beyond standard accuracy on clean data. Here are some key metrics to consider:
- Robust accuracy: This measures standard performance metrics (like accuracy, F1, AUROC, or BLEU) on shifted or corrupted datasets and tracks the drop compared to clean data performance. For safety-critical systems, worst-case and percentile metrics are crucial - such as minimum accuracy across various corruption types or 5th percentile performance to account for edge cases.
- Calibration metrics: These assess whether a model's confidence scores align with reality. Expected Calibration Error (ECE) calculates the average difference between predicted confidence and actual accuracy across probability bins. A model claiming 90% confidence but being correct only 70% of the time highlights a calibration issue. Other metrics like the Brier score (mean squared error of predicted probabilities) and negative log-likelihood penalize overconfident errors.
- Error-handling metrics: These measure how well a system manages failures. For example, the graceful failure rate tracks the percentage of stressed inputs where the system defers to a human or triggers a fallback. Recovery success rate evaluates systems with retries or model switching. Metrics like exception and timeout rates capture the proportion of requests that fail due to runtime or resource issues.
- Resource performance metrics: These are critical for deployment under constraints. Track latency at the 50th, 90th, and 99th percentiles (p99 latency often determines SLA compliance). Measure throughput in terms of requests or tokens per second under varying loads. Monitor memory usage (peak and average) and calculate costs - for instance, dollars per 1,000 requests - using U.S. cloud GPU pricing.
How Dimensions Map to Metrics
Each robustness dimension requires specific metrics to assess its performance effectively. For OOD robustness, you’ll want to measure accuracy and F1 scores on shifted datasets, analyze performance decay curves, and evaluate OOD detection using metrics like AUROC. Calibration metrics, such as ECE and the Brier score, are also essential before and after techniques like temperature scaling. For example, an e-commerce returns model might show an AUROC drop from 0.90 to 0.84 on new data, with ECE worsening from 0.03 to 0.10 - clear indicators of performance and calibration issues.
Corruption robustness relies on accuracy versus corruption severity curves, error rates across standardized benchmarks, and false positive/negative distributions for each corruption type. Adversarial robustness focuses on metrics like robust accuracy under attacks, attack success rates, and certified robustness bounds where applicable.
Statistical stability emphasizes metrics like accuracy variance across random splits, parameter variance, and sensitivity indices derived from Monte Carlo simulations. Meanwhile, resource robustness links directly to operational metrics such as latency, throughput, and cost per prediction at target accuracy levels.
For systems using model orchestration platforms like NanoGPT, robustness should also be measured at the system level. Key metrics include how often the router detects unfamiliar inputs and switches to a safer or more cost-effective model, as well as how this impacts overall latency and cost.
Designing Test Plans Under Resource Constraints
Setting Objectives and Constraints
When creating test plans, start by defining what "robustness" means for your specific use case. This involves setting clear performance thresholds that align with real business risks. For instance, a medical imaging system might require near-perfect accuracy even in challenging conditions, while a content recommendation engine could accept some performance dips during heavy traffic. The key is to tie your objectives to the potential impact of model failures and establish acceptable performance levels accordingly.
It's also important to set limits for response time, memory usage, and costs to ensure your system performs well within resource constraints. For example, platforms like NanoGPT, which route between multiple models, may have varying throughput and cost considerations. Defining these limits upfront helps maintain a balance between performance and resource efficiency.
Focus your testing efforts on failure modes that pose the greatest risk to your system's reliability. For example, a fraud detection system might prioritize tests for adversarial attacks, while a customer service chatbot could concentrate on handling unexpected or out-of-scope queries. Use these priorities to design test scenarios that reflect real-world conditions.
Creating Test Scenarios
Your test scenarios should closely mimic the conditions your system will face in production. For instance, if you're testing for data shifts, use datasets that reflect changing conditions - like evaluating a loan model against a range of economic data. For corruption scenarios, apply standard transformations at different severity levels, such as adding noise to audio signals or altering image compression quality.
Adversarial scenarios should align with realistic threat models. For example, when testing a content moderation system, you might assess vulnerabilities like prompt injection attacks. Additionally, simulate infrastructure stress by gradually increasing the load, introducing realistic delays, and replicating issues like API timeouts or rate limit errors.
High-quality test data is essential for accurate results. Use diverse datasets to prevent caching mechanisms from skewing outcomes, varying input phrasing and formats to ensure comprehensive coverage. Synthetic test cases can also be valuable for exploring edge cases, especially when developed with input from domain experts or large language models. Just make sure these cases are grounded in real-world conditions.
Once you've defined realistic scenarios, the next step is to organize them into a structured, automated test plan.
Building a Test Plan Step by Step
Start testing early by benchmarking individual model components. This modular approach helps you identify bottlenecks like latency or throughput issues before integrating backend services and routing logic. Testing components separately ensures smoother integration later.
To balance thoroughness with efficiency, automate as much of the testing process as possible. Incorporate load tests and failover scenarios into your CI/CD pipeline to maintain consistent performance checks. For evaluating results, prioritize automated grading methods such as exact matches, string matches, or LLM-based grading with clear rubrics. Reserve manual reviews for complex cases where automation might fall short.
When planning test execution, use realistic usage models. Estimate expected throughput based on metrics like user activity, session counts, and interactions per session, then adjust your testing load accordingly. Gradually increase the load to identify safety margins. Monitor both client-side metrics (e.g., response times or token delivery speed for streaming responses) and server-side metrics (e.g., CPU usage, memory, and model utilization) to pinpoint resource bottlenecks as the load scales.
Finally, adopt an iterative approach to testing. Use feedback from previous cycles to refine test scenarios, update thresholds, and adapt to new functionalities. This continuous improvement process ensures that your testing evolves alongside your system, keeping it robust and reliable over time.
Testing Techniques for Limited Resources
Stress Testing Methods
When working with limited resources, scaling batch sizes is a simple yet effective way to test performance limits. Start small and gradually increase the load until you notice slower response times or reduced accuracy. This method helps you identify the exact point where your model starts to struggle, all without needing costly infrastructure.
Another approach is using quantized models, which convert models to lower precision formats like INT8. These models use less memory and process data faster, making them perfect for edge devices. For instance, RIME recently stress-tested a model trained on the Adult Census Income dataset, demonstrating how adaptable stress testing can be when applied to both models and prediction logs across different scenarios.
"Stress testing is essential for understanding how models perform under real-world constraints, especially in edge computing scenarios." - RIME Documentation
Simulating edge deployments is another critical step. This involves testing your model in environments that mimic real-world constraints, such as mobile devices, IoT systems, or low-power hardware. These tests can uncover bottlenecks that might go unnoticed in server-based environments but could become major issues in production.
From here, you can dive into methods that challenge your model further, like simulating adversarial threats.
Adversarial and Fault Testing
For resource-efficient adversarial testing, methods like FGSM (Fast Gradient Sign Method) are invaluable. FGSM introduces small, calculated perturbations to test your model's resilience, helping identify weak spots along decision boundaries. This is especially useful for systems like content moderation or fraud detection, where adversarial threats are a real concern. Plus, this method keeps computational demands low, which is critical during defense testing.
In March 2025, OpenAI researchers showcased a technique called budget forcing, which improved reasoning performance by 27% on complex tasks. It works by dynamically adjusting computational resources during inference, enhancing accuracy without adding latency. This is particularly important for applications that require quick responses.
"Test-time scaling can significantly enhance the problem-solving capabilities of large language models, especially in low-latency environments." - Qiyuan Zhang, Researcher, OpenAI
Once adversarial testing is complete, it's essential to evaluate how well your model handles errors and maintains resilience under pressure.
Error-Handling and Resilience Tests
Testing how your model reacts to incomplete or malformed inputs is a crucial step in preparing for production. Your tests should ensure that the model rejects empty inputs, handles incorrect data types properly, and avoids crashing when exposed to extreme values. The goal is to make sure the system degrades gracefully instead of failing outright.
To catch problematic inputs, implement robust data validation. This includes verifying data types, checking for null values, and ensuring inputs fall within expected ranges.
The National Institute of Standards and Technology (NIST) has developed a modular testbed called Dioptra, which allows for thorough evaluations of machine learning algorithms under various conditions, including low-latency scenarios. Tools like this make it easier to systematically assess how well your model handles errors under resource constraints.
Finally, performance benchmarking during error-handling tests is key. Monitor metrics like inference speed, memory usage, and GPU utilization when processing edge cases. This ensures that your error-handling mechanisms don't consume excessive resources. By integrating these checks into your CI/CD pipeline, you can continuously validate your model's robustness as it evolves.
sbb-itb-903b5f2
Tools and Platforms for Robustness Testing
Using NanoGPT for Robustness Testing

NanoGPT makes robustness testing straightforward by offering access to multiple AI models through a simple pay-as-you-go system. With no subscription fees and a low starting balance of just $0.10, you can experiment with models like ChatGPT, Deepseek, Gemini, Dall-E, and Stable Diffusion without committing to monthly charges. This setup is especially useful for comparing how different models perform under stress or in adversarial scenarios.
One standout feature is its local data storage approach, which tackles privacy concerns head-on. Your test data stays on your device, rather than being uploaded to external servers. This makes NanoGPT a reliable choice for testing with sensitive or proprietary datasets - critical when working with real-world data that might include confidential information.
The platform's pay-per-question model ensures you only spend money when you're actively testing. This allows for targeted evaluations of specific failure modes without wasting resources on idle time. Additionally, you can use NanoGPT without creating an account, making it easy to dive into testing. However, creating an account ensures your balance carries over between sessions. This flexibility showcases how NanoGPT fits seamlessly into broader testing workflows.
Testing Tool Comparison
While NanoGPT is a strong option, there are many other tools that can enhance robustness testing. When choosing a tool, it’s essential to focus on features that match your needs and constraints. Effective tools should support a wide range of testing, including stress tests, continuous monitoring, and checks for bias and fairness. They should also handle diverse data formats like model files, prediction logs, CSV, and Parquet files.
In environments with limited resources, automation becomes a game-changer. Look for tools that offer automated evaluations, bulk testing, and continuous monitoring to streamline your workload. Cost is another key factor - pay attention to API pricing and whether the tool includes features like hardware accelerators to cut down on latency and energy use. For instance, the Google Coral USB Accelerator can perform 4 trillion operations per second while consuming just 0.5 watts.
Other must-have features include qualitative tools for annotation and coding, quantitative metrics, and options for prompt optimization and synthetic data generation. Tools that cache test results can save you time and computational resources by avoiding redundant evaluations. For edge deployments, prioritize platforms that can test lightweight models on devices like Raspberry Pi, especially when paired with accelerators.
Interpreting Results and Implementing Robustness
Analyzing Failures and Bottlenecks
Once testing is complete, the next step is identifying where things go wrong. For example, in October 2025, OpenAI examined an apartment leasing assistant by using open coding to label errors, such as scheduling mishaps or poorly formatted outputs. They then applied axial coding to group these issues into categories, discovering that 35% of failures were tied to tour scheduling problems.
It's also important to evaluate factors like calibration, fairness, bias, toxicity, and efficiency. Pay close attention to significant performance drops, which might occur when handling typos or switching between dialects - these often expose critical weaknesses. Additionally, benchmark your model's inference speed, memory usage, and GPU demands to identify where efficiency can be improved. Don't forget to ensure the model can handle invalid inputs gracefully.
These findings help establish clear benchmarks for deployment readiness.
Setting Deployment Thresholds
Deployment thresholds should address key criteria like accuracy, bias, robustness under stress, security, privacy, and regulatory compliance. When resources are limited, finding the right balance between model intelligence and factors like cost, speed, latency, and power consumption becomes critical.
For instance, the Google Coral USB Accelerator offers a practical example: it reduced NanoGPT's average latency from 200ms to 45ms, increased throughput from 15 to 60 queries per second, and lowered power consumption from 5.2W to 3.8W on a Raspberry Pi. These specific improvements can guide realistic threshold-setting.
Validate your model using statistical measures across development, validation, and separate testing datasets to ensure it's ready for practical use. Tools like Robust Intelligence (RIME) can provide detailed performance metrics, including bias and fairness checks, to inform your decisions. Keep in mind that higher-performing models often come with increased costs, but not all follow the same price-to-quality ratio. Weigh the trade-offs between intelligence, cost, and speed carefully when setting your thresholds.
Once thresholds are defined, focus on maintaining performance through continuous monitoring.
Continuous Monitoring and Updates
AI models aren’t static; they require ongoing oversight as data evolves, which can lead to performance degradation over time. Regular robustness testing, supported by MLOps automation, helps address issues caused by data drift.
Develop a continuous feedback loop where testing results directly shape the next development cycle. As your system improves, new and more subtle failure modes are likely to appear, so treat analysis as an ongoing effort rather than a one-time task. Automated tools, such as Python scripts or evaluators powered by large language models (LLMs), can quickly assess specific performance aspects at scale, reducing the need for manual reviews. This iterative process ensures your model remains reliable as user behavior shifts and new challenges emerge.
Conclusion
Ensuring AI models are robust is essential for their success in unpredictable, real-world scenarios where data can be messy, inputs may vary, and adversarial attacks are a constant threat. As highlighted in this guide, a model might perform exceptionally well in a controlled lab environment but fall apart when exposed to noisy data, shifting distributions, or deliberate manipulation. For instance, in 2024, medical machine learning models tested during emergencies failed to detect 66% of test cases involving serious injuries for in-hospital mortality prediction. This stark example underscores how vulnerable models can be without rigorous robustness testing.
Allocating resources wisely is key to addressing these challenges. Building custom evaluation pipelines, conducting regular adversarial testing, and maintaining continuous monitoring are vital steps to identify and mitigate model drift before it impacts end users. OpenAI’s GPT-4, for example, improved its ability to refuse unsafe requests and reduced harmful outputs through extensive "red teaming" efforts involving over 100 experts.
"Robustness ensures that a model can generalize well to new unseen data, a key aspect of AI robustness in real-world applications." – Fiddler AI
To deploy reliable models, it’s crucial to establish clear thresholds for accuracy, bias, security, and performance under stress. Leveraging MLOps practices can automate testing and monitoring processes, saving time and reducing manual intervention. When faced with limited data, techniques like data augmentation and synthetic data generation can strengthen a model’s resilience without requiring vast resources. Incorporating these strategies into ongoing MLOps workflows ensures the long-term reliability of your AI systems.
Taking these proactive measures results in models that can withstand the demands of production environments. By focusing on robustness during development, you can reduce costs tied to retraining, downtime, and performance degradation in the future. While there may be trade-offs in terms of computational resources or training time, these investments ultimately ensure your AI systems perform reliably when it matters most.
FAQs
What are the main aspects to consider when testing AI model robustness?
AI model robustness testing is all about ensuring a model performs reliably, even when faced with real-world conditions that differ from its training environment. This step is critical for maintaining user trust, ensuring safety, and delivering consistent performance, especially when dealing with unpredictable inputs, hardware limitations, or unique user interactions.
Here are the main areas to focus on during robustness testing:
- Dealing with distribution shifts: Checking how the model handles data that’s different or unexpected compared to what it was trained on.
- Adversarial resistance: Evaluating whether the model can withstand intentional manipulations or errors designed to exploit weaknesses.
- Performance in low-resource settings: Measuring speed, memory usage, and efficiency on devices with limited resources, like smartphones.
- Error management: Ensuring the model can gracefully handle invalid inputs or system failures without crashing or producing harmful outputs.
- Fairness and bias checks: Confirming that the model delivers equitable outcomes across diverse groups, even when data is noisy or shifted.
With tools like NanoGPT, you can tackle these tests efficiently while keeping your data secure on your device. Plus, its pay-as-you-go pricing means you can prepare for real-world challenges without committing to long-term subscriptions.
What’s the best way to test AI models for adversarial robustness?
Testing AI models for adversarial robustness means evaluating how they perform when faced with deliberately tricky inputs designed to expose vulnerabilities. The first step is to define your threat model. This includes specifying the type of input (like text or images), the permissible alterations (such as slight edits or pixel tweaks), and the adversary’s level of access or knowledge (e.g., white-box or black-box attacks).
Next, generate adversarial examples using established techniques. For image-based models, methods like FGSM (Fast Gradient Sign Method) or PGD (Projected Gradient Descent) are commonly used. For language models, you might use text-based perturbations, which involve small but impactful changes to the input text.
Once you have these examples, stress-test your model to evaluate key performance metrics. These include clean accuracy (performance on unaltered inputs), adversarial accuracy (performance on adversarial examples), and how the model’s performance shifts as the intensity of adversarial inputs increases. It’s also worth experimenting with compute budgets - giving the model extra processing time can sometimes improve its ability to handle adversarial attacks.
By systematically creating adversarial examples, running tests under various conditions, and fine-tuning the model, you can work toward making it more resilient to these challenges.
What are the best metrics to evaluate the robustness of an AI model?
Evaluating the robustness of an AI model means examining how well it performs when faced with tough conditions like noisy data, limited resources, or unexpected glitches. To get a clear picture of its reliability, you’ll want to focus on a few key metrics:
- Accuracy under stress: This checks how much quality drops when the model handles distorted or out-of-the-ordinary test data.
- Adversarial resilience: Tracks how well the model stands up to adversarial attacks or measures its overall vulnerability.
- Resource efficiency: Looks at latency, throughput, and memory usage, especially when running on hardware with tight constraints.
- Error-handling: Assesses how often failures occur and how quickly the system can recover when things go wrong.
Consistently monitoring these metrics helps pinpoint areas where the model might struggle, ensuring it stays reliable even in demanding, real-world conditions. Tools like NanoGPT’s pay-as-you-go model make it easier to keep an eye on critical factors like latency and error rates, giving you the insights needed to fine-tune your AI for steady, dependable performance.