AI-Powered Healthcare: Real-Time Data Integration Explained
If AI gets patient data too late, it can miss the moment to help. In healthcare, the main issue is simple: data has to move from EHRs, labs, monitors, and home devices to an AI system in seconds or minutes, not hours. When that happens, teams can spot sepsis sooner, send bedside alerts in under 60 seconds, and support ICU and remote monitoring with current data instead of old updates.
Here’s the short version:
- Batch feeds are too slow for time-sensitive care. They often take 12 to 24 hours.
- Polling-based setups are faster, but still often take 5 to 15 minutes.
- Streaming pipelines can deliver data in sub-seconds to seconds.
- FHIR, HL7 v2, Kafka, edge gateways, and MPI each play a different part in the flow.
- Patient matching, event order, validation, encryption, and audit logs matter just as much as speed.
- Best-fit use cases include sepsis alerts, ICU monitoring, medication checks, tele-ICU, and chronic care monitoring from wearables.
What I take from this article is clear: real-time AI in healthcare is not just about fast data. It depends on clean data, correct patient identity, low delay, and HIPAA-aware controls working together. If one piece fails, the alert may reach the wrong chart, arrive too late, or use bad inputs.
Improving Hospital Operations with Streaming Data and Real Time AI/ML
sbb-itb-903b5f2
Quick comparison
| Model | How it works | Typical delay | Best use |
|---|---|---|---|
| Batch | Scheduled transfers | 12–24 hours | Reporting, billing, population health |
| Near-real-time | Repeated polling or subscriptions | 5–15 minutes or seconds to minutes | Care coordination, simple alerts |
| Real-time streaming | Event-driven push | Sub-second to seconds | ICU alerts, sepsis detection, bedside monitoring |
I’d sum it up like this: the article explains how live healthcare data moves from source systems to AI-driven action, what tools make that possible, where it helps most, and what controls keep it safe.
How Healthcare Data Moves From Clinical Sources to AI Decisions
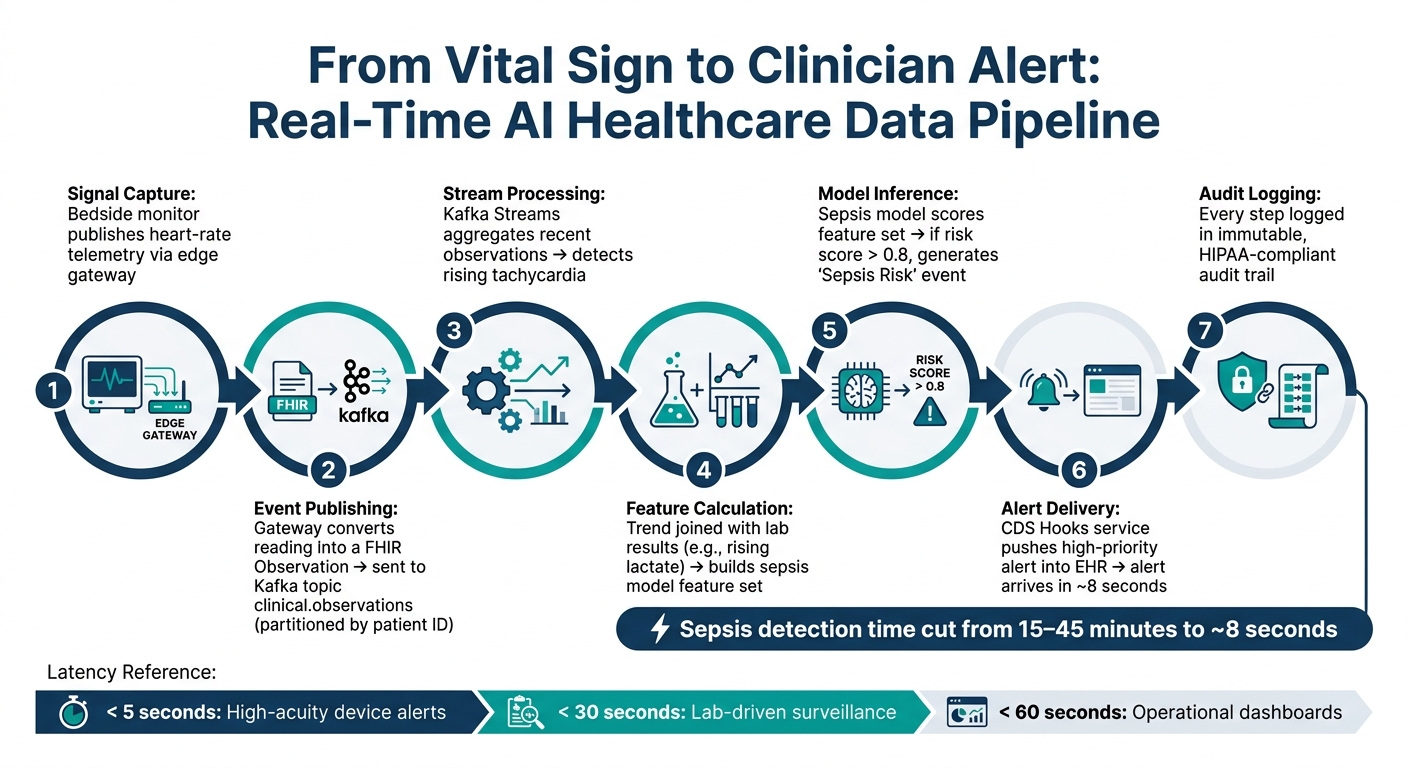
From Vital Sign to Clinician Alert: Real-Time AI Healthcare Data Pipeline
Where Real-Time Healthcare Data Comes From
Once data starts moving, the pipeline needs to pull it in from every clinical source without losing context. That includes EHRs, lab systems, imaging systems, and IoMT devices like monitors, pulse oximeters, and ventilators.
It doesn’t stop at the hospital. Telemedicine platforms, wearables, home monitoring devices, and mobile health apps add even more signals. These data sources come in through HL7 v2, FHIR APIs, MQTT, and custom interfaces.
Ingestion, Normalization, and Patient Matching in Streaming Pipelines
After data leaves a source system, it moves into an ingestion layer, usually an interface engine or edge gateway. That layer parses each incoming message format and converts it into a canonical model. A smart move here is to normalize to FHIR at ingestion so downstream models can work from one schema.
Next, events are published to a message broker such as Kafka or RabbitMQ. In Kafka-based setups, topics are grouped by resource type and partitioned by patient ID to preserve per-patient order. That detail matters. If events arrive out of sequence, the model can get a warped view of the care timeline.
Before an event gets to the model, the pipeline matches the patient through a Master Patient Index (MPI) and runs validation checks. A bad patient match can lead to a wrong-chart alert, so identity resolution is a patient-safety step, not just back-end plumbing. If the match is uncertain, the event should be held for review. That clean handoff is what helps the model score the right patient at the right time.
Step-by-Step: From One Vital Sign Reading to One Clinician Alert
Here’s what that looks like in practice when one bedside reading turns into a clinician-facing alert.
- Signal capture: A bedside monitor publishes heart-rate telemetry through an edge gateway.
- Event publishing: The gateway converts the reading into a FHIR
Observationand sends it to aclinical.observationsKafka topic, partitioned by patient ID. - Stream processing: Kafka Streams pulls together recent observations and spots rising tachycardia.
- Feature calculation: That trend is joined with recent lab results, such as rising lactate, to build a feature set for a sepsis prediction model.
- Model inference: The model scores the feature set. If the risk score goes above
0.8, it generates aSepsis Riskevent. - Alert delivery: A CDS Hooks service receives the event and pushes a high-priority alert into the EHR. In one event-driven example, sepsis alerts arrived in around 8 seconds.
- Audit logging: Every step is logged in an immutable, HIPAA-compliant audit trail.
"A critical potassium level triggers an alert on the nurse station dashboard before the physician has finished reviewing the order in the EHR." - Nirmitee.io, Streaming Healthcare Data with Kafka and FHIR
Those handoffs rely on the standards, streaming tools, and security controls covered next.
The Technologies and Standards Behind Real-Time Healthcare Data Integration
HL7 v2, FHIR, and Streaming Platforms: What Each One Does
Once data comes in, it has to become usable, fast, and safe for AI. In a modern healthcare pipeline, three separate layers handle that job. Each one does something different.
HL7 v2 handles real-time clinical messaging, including admissions, discharges, transfers (ADT), lab orders (ORM), and results (ORU). It uses a pipe-delimited format, which means teams usually need to do a lot of parsing before downstream AI models and rules engines can work with the data. Over 90% of Health Information Exchange (HIE) networks still use HL7 v2 ADT messages as their main exchange method.
FHIR gives teams structured, API-ready data. It exposes healthcare data as JSON/XML resources through an API, which makes life much easier for AI apps. That said, FHIR exposes structured data through APIs; it does not replace the integration layer.
Streaming platforms like Apache Kafka serve as the shared event layer. They separate source systems from consumers, so clinical systems can publish events without hardwired point-to-point links. Kafka can deliver producer-to-consumer latency of under 10 ms, versus roughly 500 ms for older integration hubs.
| Capability | HL7 v2 | FHIR | Streaming (Kafka) |
|---|---|---|---|
| Primary Purpose | Legacy clinical messaging (ADT, labs) | Modern API-based data exchange | Low-latency event distribution |
| Data Format | Pipe-delimited (non-standardized) | JSON/XML (resource-based) | Binary/Avro/JSON |
| AI Fit | Poor (requires heavy parsing) | Excellent (structured features) | Excellent (feature streaming) |
| Flexibility | Low (rigid segments) | High (extensions/profiles) | High (decoupled pub/sub) |
In practice, an integration engine such as Mirth Connect converts HL7 v2 or DICOM into FHIR resources, then publishes them to Kafka for downstream AI models and rules engines.
These standards matter because they feed the streaming layer that powers AI action in real time.
Stream Processing and Edge Computing for Low-Latency Health Data
Once events land on the Kafka bus, stream processors like Apache Flink or Spark Streaming take over. They compute features on live event streams all the time. For example, they can join a patient's latest vitals with recent lab trends and trigger model inference without waiting for a batch window. A well-tuned pipeline can process every lab result in under 100 milliseconds.
For bedside monitors and wearables, edge gateways handle the first round of normalization. Edge computing normalizes high-frequency telemetry before it reaches the streaming pipeline. If connectivity fails, the gateway stops forwarding data and alerts clinical engineering.
Latency targets tie straight to clinical risk. The recommended thresholds are under 5 seconds for high-acuity device alerts, under 30 seconds for lab-driven surveillance, and under 60 seconds for operational dashboards.
That kind of speed only holds up if controls stay built into every hop.
Security and HIPAA Controls Built Into the Pipeline
Compliance shapes the architecture from day one. The controls below protect the same real-time pipeline described above. PHI moves through each hop, and each hop needs its own safeguard.
| Control Category | Technical Implementation | HIPAA/Compliance Purpose |
|---|---|---|
| Transmission Security | TLS 1.2+, TLS-wrapped MLLP (MLLP/S), HTTPS, SASL/SSL | Encryption in transit (§164.312(e)(1)) |
| Access Control | RBAC, OAuth 2.0, mTLS, ACLs | Authorized access only (§164.312(a)(1)) |
| Integrity | Schema Registry, Exactly-Once Semantics | Protect data from improper alteration (§164.312(c)(1)) |
| Audit | SIEM integration, audit logs | Record and examine activity in systems (§164.312(b)) |
| Retention | Cold storage (S3/archive) | Regulatory data retention (typically 6+ years) |
Exactly-Once Semantics (EOS) in Kafka prevents a medication order from being recorded twice or dropped entirely. In healthcare, either mistake can become a patient-safety failure, not just a data quality problem. Schema Registries using Avro or Protobuf enforce data contracts, so a malformed lab result with no patient reference cannot slip into a downstream AI model.
On the identity side, system-to-system connections should use Mutual TLS (mTLS) or SMART on FHIR (OAuth 2.0). Before any protected health information (PHI) moves through a cloud provider's infrastructure, a Business Associate Agreement (BAA) must be signed. Teams should also minimize PHI when the use case does not need full patient identity. If full PHI is not needed, identifiers should be tokenized.
With standards, processing, and controls in place, the next step is figuring out where this architecture delivers clinical value.
Where Real-Time AI Data Integration Delivers Clinical Value
Once the pipeline is up and running, the next step is simple: figure out where real-time AI can change care in a way that matters.
ICU Monitoring, Sepsis Alerts, and Tele-ICU Workflows
With the live Kafka/FHIR pipeline described above, ICU monitors can feed AI deterioration models as data comes in. Bedside monitors stream respiratory rate, SpO2, blood pressure, and heart rate nonstop. When those streams are combined with lab results like lactate, creatinine, and white blood cell count, an AI model can score sepsis risk from vitals and labs, using qSOFA or SIRS as inputs, and send an alert before a code event happens.
Sepsis can progress to septic shock in under 6 hours. That delay means clinicians may be working from old data.
A live pipeline can cut sepsis detection from 15–45 minutes to 8 seconds. For windowed scoring, teams can use Redis for fast lookups and automatic expiration of stale criteria.
In June 2024, CMUH used HL7 FHIR and Kafka in its respiratory ICU to combine ventilator, monitor, and blood gas data. That setup improved ARDS diagnosis and reduced mortality.
The same pattern applies outside the ICU too. The only thing that changes is the clock: in critical care, seconds matter; in home monitoring, the window is often minutes.
Telemedicine and Wearable-Based Chronic Care Monitoring
Outside the hospital, the same integration approach works at a different pace. Wearables and home devices, such as blood pressure cuffs and glucose sensors, produce readings that can trigger triage and risk updates. If glucose moves outside the target range, the pipeline can refresh risk assessments to help prevent readmissions.
These devices often connect through edge gateways that filter noisy or spotty readings before sending them on. For chronic care workflows, time-to-insight is usually measured in minutes.
"If the insight arrives fast enough to change the next clinical decision, it's real-time for that use case. If it arrives after the decision, it's just reporting with better marketing." - Abhishek Patel, Healthcare Data Expert
Use Case Comparison: Data Source, AI Task, and Required Speed
The latency target depends on the workflow. Some use cases need an answer almost at once. Others can wait a few minutes and still affect care.
| Use Case | Primary Data Sources | AI Task | Required Time-to-Insight |
|---|---|---|---|
| High-Acuity Alerts | Bedside monitors, Telemetry | Deterioration/Arrhythmia detection | < 5 seconds |
| Sepsis Surveillance | Vitals, Labs (CBC, Lactate), EHR | qSOFA/Sepsis risk scoring | < 30 seconds |
| Medication Safety | Orders, Labs (eGFR), Pharmacy system | Interaction/Dose adjustment check | Seconds (Pre-administration) |
| Chronic Care (RPM) | Wearables (Glucose, BP), Home sensors | Risk trend assessment | Minutes |
(Source:)
One practical note: for systems processing fewer than 1,000 events per second, FHIR Subscriptions are often simpler and more standards-compliant than setting up a full Kafka cluster. The heavier setup makes more sense for high-acuity workflows, where throughput and guaranteed message ordering are non-negotiable.
Architecture Patterns, Governance, and Key Takeaways
Architecture Patterns: Batch, Near-Real-Time, and Fully Event-Driven
Clinical systems usually don’t run on one pattern alone. Most teams use batch jobs for reporting and add streaming paths for cases where timing affects care. After you define the pipeline and the use cases, the next step is picking the right operating model for each workflow. ICU alerts, sepsis detection, and wearable monitoring don’t need the same latency, and they definitely don’t need the same spend.
| Pattern | Latency | Complexity | Best Fit |
|---|---|---|---|
| Batch | Hours to days | Low | Population health, billing, retrospective analytics |
| Near-Real-Time (FHIR Subscriptions) | Seconds to minutes | Moderate | Simple alerts, care coordination |
| Fully Event-Driven (Kafka/Streaming) | Low milliseconds to seconds | High | ICU monitoring, sepsis detection, real-time CDS |
The tradeoff is pretty simple: event-driven pipelines cost more, so they make the most sense when lower latency can change a care decision.
Once that pattern is in place, the next issue is reliability. If the pipeline can’t stay correct under pressure, it shouldn’t support clinical decisions.
Data Quality, Reliability, and Governance in Live Healthcare Pipelines
In live healthcare pipelines, small data problems can turn into clinical problems fast. That’s why teams partition by patient ID, deduplicate events, and use exactly-once semantics to stop out-of-order or duplicated clinical data .
Schema checks should happen at write time so malformed records never make it into downstream AI systems. When data fails validation, send it to a review queue instead of letting it slip through.
Reliability controls matter just as much. Circuit breakers at the ingestion layer help protect the processing layer from event storms. Offsets should be committed only after processing, which lets failed messages replay cleanly. For observability, monitor consumer lag and trigger alerts if it goes past 5 minutes, along with broker replication health.
Governance is what makes real-time AI safe, auditable, and usable in clinical settings. HIPAA compliance calls for TLS encryption in transit, disk encryption at rest, and strict RBAC for topic access . Audit logs should record who accessed which data and when, especially when an AI alert affects a care decision .
That’s the heart of it: architecture works only when speed, correctness, and governance move together.
Conclusion: Key Points to Remember
Real-time healthcare AI depends on interoperable standards, correct patient matching, strict data quality, and HIPAA-aware controls. Speed matters only when the data can be trusted. Real-time AI works when data moves from the source system to the alert without losing identity, order, or trust.
FAQs
How is real-time different from near-real-time in healthcare AI?
Real-time healthcare AI reacts to clinical signals - like new vital signs or lab results - with sub-second or one-second latency. The goal is simple: support immediate decisions at the point of care.
Near-real-time systems usually refresh every few minutes, up to 15 minutes, through periodic polling. That can work well for dashboards and trend monitoring. But when a patient's condition changes fast, those update gaps can cause teams to miss moments that call for instant action.
Why is patient matching so important in live AI alerts?
Patient matching matters because it makes sure incoming clinical data - like wearable vitals or diagnostic reports - gets tied to the right patient.
If that data lands in the wrong record, the risk to patient safety is serious. That’s why systems check identity again with every reading and quarantine mismatched data so it doesn’t trigger the wrong alerts.
When should a hospital use FHIR Subscriptions instead of Kafka?
Use FHIR Subscriptions when a hospital needs standards-based, event-driven notifications for specific clinical resource changes. That fits use cases like care alerts, downstream system sync, or kicking off AI agents.
Use Kafka for high-volume, enterprise-wide streaming. FHIR Subscriptions make more sense when you need direct integration with EHR workflows and a standards-compliant, resource-aware setup.