Batch vs. Layer Normalization in RNNs
Layer Normalization (LN) is better suited for Recurrent Neural Networks (RNNs) than Batch Normalization (BN). Why? Because LN normalizes across features for each sample, making it consistent and effective even with variable-length sequences and small batch sizes. BN, on the other hand, relies on batch-wide statistics, which can create challenges like instability with small batches or variable sequence lengths.
Key Takeaways:
- BN works well for large, fixed batch sizes (e.g., CNNs) but struggles with sequential data.
- LN excels in RNNs, LSTMs, and Transformers, offering stable training and consistent behavior during both training and inference.
- LN avoids issues like padding distortion and train-test discrepancies, making it the preferred choice for sequence-based tasks.
Quick Comparison:
| Factor | Batch Normalization (BN) | Layer Normalization (LN) |
|---|---|---|
| Normalization Axis | Across batch (per feature) | Across features (per sample) |
| Batch Size Dependency | High; needs large batches | None; works with small batches |
| RNN Suitability | Low | High |
| Inference Consistency | Relies on running averages | Matches training behavior |
| Primary Use Case | CNNs, feed-forward networks | RNNs, Transformers, NLP tasks |
If you're working with RNNs or sequence models, choose LN for better stability and performance. Use BN for tasks involving large, fixed-size batches like CNNs.
Batch Normalization vs Layer Normalization in RNNs: Key Differences
Batch Normalization in RNNs
How Batch Normalization Works
Batch Normalization (BN) helps stabilize the training process by normalizing the inputs to each layer. It calculates the mean (μ_B) and variance (σ_B²) for a mini-batch of data, then adjusts the activations to have a mean of zero and a variance of one. To maintain flexibility, BN introduces two learnable parameters - γ (scale) and β (shift) - that allow the model to adjust or even undo the normalization if necessary. During training, BN uses the statistics from the current mini-batch, but during inference, it relies on running averages collected throughout training.
In feedforward and convolutional networks, BN allows for higher learning rates, reduces sensitivity to weight initialization, and makes the optimization process smoother. However, when it comes to sequential models like RNNs, BN faces several hurdles.
Challenges in RNNs
Applying BN to RNNs is tricky due to the unique characteristics of sequential data. One of the biggest challenges is time-step dependency. BN requires separate statistics for each time step, which complicates training and inference in RNNs. As Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton explained:
"But when we apply batch normalization to an RNN in the obvious way, we need to compute and store separate statistics for each time step in a sequence. This is problematic if a test sequence is longer than any training sequences".
This means that during inference, if the model encounters sequences longer than those seen during training, BN struggles to normalize effectively due to missing statistics.
Another issue is batch size sensitivity. BN typically requires batch sizes of at least 16 to 32 samples to compute reliable statistics. However, RNNs often work with smaller batch sizes because processing long sequences demands significant memory. This limitation can degrade BN's performance. Furthermore, in deeper networks, BN can worsen gradient problems at initialization, potentially making the model untrainable unless residual connections are used. Studies have shown that in networks with L layers, the gradient norm can grow as c·λ^L (where λ > 1), complicating training.
Variable-length sequences pose yet another challenge. When mini-batches include sequences of different lengths, padding tokens are often used to align them. These padding tokens can distort the mean and variance calculations unless explicitly excluded, adding complexity to the process. These challenges have led researchers to explore alternative normalization techniques better suited for RNNs.
sbb-itb-903b5f2
Layer Normalization in RNNs
How Layer Normalization Works
Layer Normalization (LN) operates differently from Batch Normalization. Instead of relying on batch-wide statistics, LN computes the mean and variance across the feature dimension for each individual data instance. For every instance, LN calculates the feature-wise mean, subtracts it, and divides by the standard deviation (adding a small epsilon to prevent division by zero). Additionally, LN includes learnable parameters for scale (γ) and shift (β), allowing the network to fine-tune the normalized output.
In the context of RNNs, LN is applied at each time step to the combined inputs of the recurrent unit, whether it's an LSTM or GRU, ensuring that activations remain stable throughout long sequences. Unlike Batch Normalization, LN performs the exact same computations during both training and inference, removing the need for maintaining running averages of statistics. As Michael Brenndoerfer put it:
"The key intuition is that... it makes sense, then, to normalize each representation individually, based on its own statistics, rather than blending its statistics with those of other samples in the batch".
This individualized approach is particularly effective for handling variable sequence lengths in RNNs. By normalizing each instance independently, LN helps stabilize activations across time steps, improving the overall performance of recurrent networks.
Advantages for RNNs
LN resolves many of the challenges that make Batch Normalization unsuitable for RNNs. Its per-instance normalization makes it independent of batch size, meaning it works well for both large batches and single sequences. This is especially important in RNN applications, where small batch sizes are common.
Another major advantage is that LN avoids complications caused by padding or varying sequence lengths. By normalizing each sample consistently, it stabilizes the hidden state dynamics across all time steps.
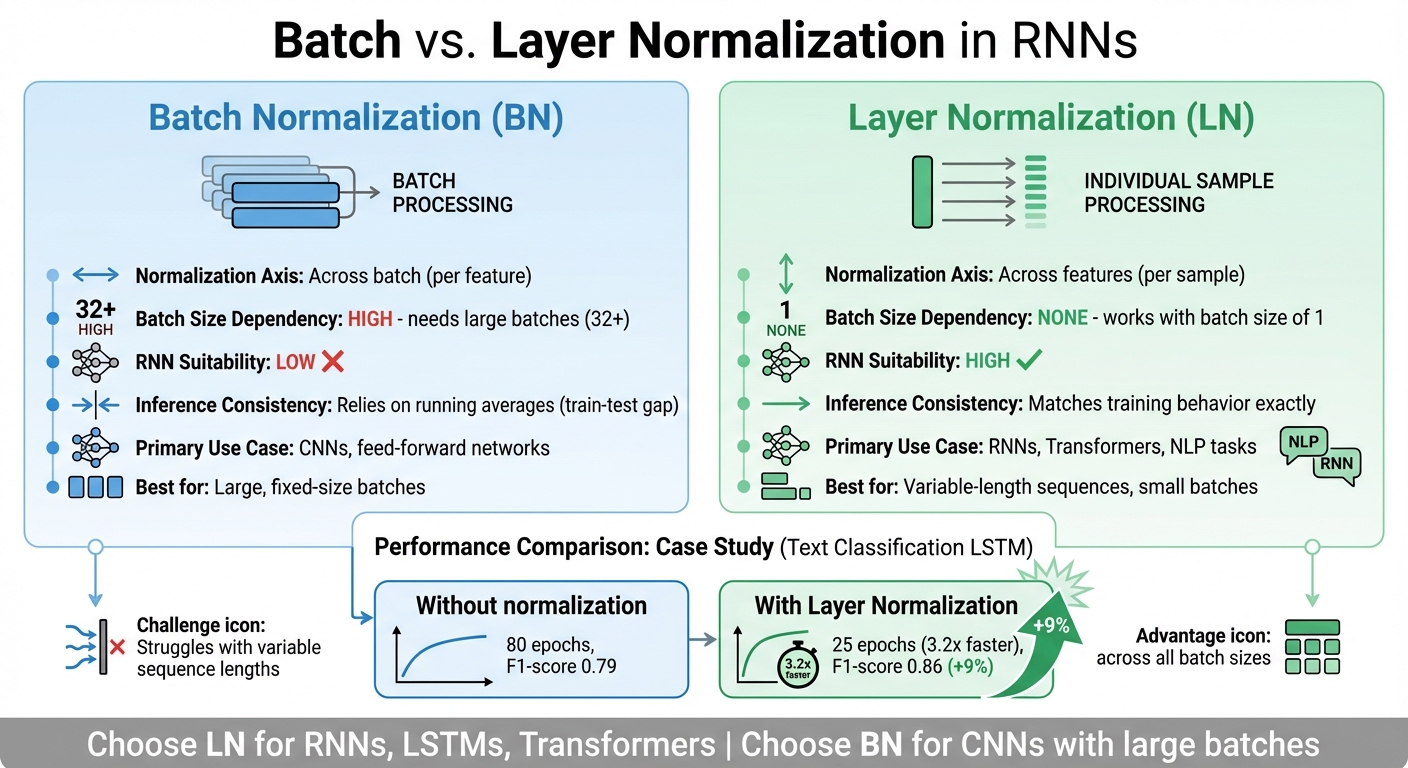
In December 2025, researcher Marwan Eslam Ouda shared findings from a text classification project using an LSTM model. Without normalization, the model took 80 epochs to converge, achieving an F1-score of 0.79, while frequently encountering gradient instability. After applying layer normalization, the model converged 3.2 times faster, requiring just 25 epochs, and achieved a 9% higher F1-score (0.86) while avoiding gradient issues altogether.
Layer Normalization was first introduced in 2016 by Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton at the University of Toronto to address Batch Normalization's limitations in recurrent networks. Today, LN has become a standard method for normalizing sequential architectures like LSTMs, GRUs, and Transformers.
Recurrent Neural Networks, Batch/Layer Norm (Winter 2025)
Key Differences Between Batch and Layer Normalization in RNNs
This section breaks down the main distinctions between Batch Normalization (BN) and Layer Normalization (LN) when applied to Recurrent Neural Networks (RNNs), building on their individual functions.
Normalization Approach
BN and LN differ significantly in how they normalize data. BN works across samples, calculating feature statistics like mean and variance across an entire batch of samples. LN, on the other hand, normalizes features within each individual sample, treating each sequence independently. This independence ensures that the gradient calculations for one sample are unaffected by others. As a result, BN inherently links samples together during training, while LN keeps them isolated.
Impact of Batch Size
Batch size plays a critical role in BN's effectiveness. Since BN depends on batch-wide statistics, small batches can lead to unstable estimates of mean and variance, which can disrupt training. Typically, BN works best with batch sizes of 32 or more. When batch sizes are too small, the variability in statistics can cause training to diverge or stall altogether.
LN, however, is not affected by batch size. It remains consistent whether processing a single sequence or hundreds. This makes LN particularly valuable for applications like modern Large Language Models, where memory limitations often restrict batch sizes to as few as 1 to 8 sequences per device.
Training and Inference Behavior
BN introduces a notable "train-test gap." During training, it uses statistics from the current mini-batch, but during inference, it switches to pre-computed running averages. This difference can lead to inconsistencies, especially in sequential models like RNNs, where inputs are processed one at a time.
LN avoids this issue by using the same normalization method - based on the current sample - during both training and inference. This ensures consistent behavior. As Yiqing Liang notes:
"In transformers, each position in a sequence computes context-dependent representations through self-attention. LayerNorm normalizes these representations at each position independently, which aligns perfectly with the position-wise nature of transformer computations".
This consistency is particularly beneficial for RNNs, where varying sequence lengths can make it challenging for BN to maintain accurate mini-batch statistics.
Use Cases and Performance Impacts in RNNs
These examples highlight how Batch Normalization (BN) and Layer Normalization (LN) differ in their practical applications and performance.
When to Use Batch Normalization
Batch Normalization shines when you're working with large, fixed batch sizes - typically 32 or more. However, it struggles with smaller batch sizes because it can't reliably estimate the necessary statistics. This makes BN less suitable for most RNN tasks, where memory limits and variable sequence lengths often require smaller batches.
That said, BN can still excel in certain scenarios. For example, in hybrid architectures combining convolutional layers with RNNs, BN performs well in the convolutional components, where spatial invariance is a key factor. In 2016, researchers Tim Cooijmans and Nicolas Ballas demonstrated the effectiveness of BN in LSTMs (referred to as BN-LSTM). By applying BN to both input-to-hidden and hidden-to-hidden transformations and initializing the gamma parameter to 0.1, they improved performance on the Penn Treebank dataset, achieving 1.32 bits-per-character (BPC) compared to the baseline LSTM's 1.38 BPC. Similarly, on the text8 dataset, BN-LSTM reached 1.36 BPC, outperforming the baseline's 1.43 BPC.
However, in scenarios where batch size constraints are critical, Layer Normalization emerges as the better option.
When to Use Layer Normalization
Layer Normalization is the go-to choice for RNNs and sequential models. It naturally accommodates variable sequence lengths and performs well even with batch sizes as small as 1. This makes LN particularly effective for real-time inference and online learning. Additionally, LN eliminates the train-test discrepancies that can arise with BN, ensuring consistent behavior during both training and inference.
Performance Comparisons
The practical differences between BN and LN become even more pronounced when comparing performance. LN offers greater training stability by normalizing each sample independently, which results in more predictable gradients. In contrast, BN ties samples together within a batch, leading to higher gradient variance and instability when batch sizes are small.
For distributed training, LN has another edge: it doesn't require cross-device synchronization. BN, on the other hand, needs to synchronize batch statistics across GPUs, which adds computational overhead.
"The transition from BatchNorm to LayerNorm mirrors the broader shift from convolutional architectures processing fixed grids to transformer architectures processing variable-length sequences with position-wise operations." - Yiqing Liang
In recent years, the trend has shifted decisively toward LN in modern sequential architectures. Many newer models also incorporate RMSNorm - a simplified version of LN - and "Pre-Norm" setups for improved gradient flow in deeper networks. These advancements further underline LN's growing prominence.
Comparison Table: Batch vs. Layer Normalization in RNNs
Batch Normalization and Layer Normalization share the goal of stabilizing training by addressing internal covariate shift. However, the way they compute normalization statistics sets them apart, especially in the context of recurrent neural networks. This table highlights the key differences, making it easier to see why Layer Normalization is often the go-to choice for sequential models.
Markdown Table
| Factor | Batch Normalization (BN) | Layer Normalization (LN) |
|---|---|---|
| Normalization Axis | Across the batch (for each feature) | Across the features (for each sample) |
| Batch Size Dependency | High; works best with large batches (typically >16) | None; effective even with a batch size of one |
| RNN Suitability | Low; struggles with variable sequence lengths | High; naturally handles variable lengths |
| Computational Stability | Unstable with small batches or varying sequences | Stable across different batch sizes and sequence lengths |
| Inference Behavior | Relies on running averages, which can cause discrepancies between training and testing | Matches training behavior exactly (no discrepancies) |
| Primary Use Case | CNNs and feed-forward networks | RNNs, Transformers, and NLP tasks |
| Learnable Parameters | Gamma (scale) and Beta (shift) per feature | Gamma (scale) and Beta (shift) per feature |
Conclusion
The choice between normalization techniques depends heavily on the specific task and the architecture's requirements. As ML Engineer Priya Singh aptly notes:
"BatchNorm is not 'bad.' It's context-dependent. LayerNorm isn't 'better.' It's aligned with how modern AI systems actually work".
For models like RNNs, LSTMs, and Transformers, Layer Normalization often proves to be the better fit. Its ability to handle variable-length sequences naturally, maintain consistent behavior during both training and inference, and remain stable with batch sizes as small as 1 makes it ideal for sequence-based tasks. These features are particularly valuable for online learning and streaming applications. As highlighted earlier, these benefits lead to faster convergence and better performance on sequential tasks.
On the other hand, Batch Normalization shines in tasks involving fixed, large-scale batches. It remains a go-to choice for pure CNN architectures in computer vision, where stable, large batches (typically 32 or more) and fixed-size inputs are common. For example, in a 2025 medical image classification project, BatchNorm reduced training time from 6 hours to 1.5 hours and increased accuracy from 84% to 91%. However, its reliance on batch statistics makes it unsuitable for sequential tasks involving variable-length inputs, such as those tackled by RNNs.
The takeaway is simple: use Layer Normalization for sequence models, especially when dealing with small batches, variable-length sequences, or online inference. Batch Normalization is better suited for convolutional architectures with large, consistent batches. For hybrid models that combine convolutional and recurrent elements, apply BatchNorm to CNN layers and LayerNorm to sequential components.
FAQs
Where should I add LayerNorm inside an LSTM or GRU?
LayerNorm is commonly applied after linear transformations and before activation functions in architectures like LSTMs or GRUs. Its role is to normalize features within each time step, which helps stabilize the hidden state dynamics and ensures smoother training. Unlike BatchNorm, which relies on the batch size, LayerNorm operates consistently across time steps. This makes it an ideal choice for recurrent models such as RNNs, LSTMs, and GRUs.
Can BatchNorm work in RNNs with very small batches?
Batch Normalization (BatchNorm) tends to fall short in Recurrent Neural Networks (RNNs) when batch sizes are very small. Here's why: it depends heavily on mini-batch statistics to normalize data. With smaller batches, these statistics become less reliable, leading to noisy estimates and making the training process unstable.
Instead, Layer Normalization is often the go-to choice for RNNs. It works by normalizing across features within a single sample, rather than relying on batch-level statistics. This approach not only stabilizes the training process but also ensures consistent performance, regardless of the batch size.
How does LayerNorm handle padding and variable-length sequences?
LayerNorm works by normalizing the features of each sequence element individually, rather than normalizing across the entire batch. This approach makes it particularly effective for handling variable-length sequences since the presence of padding doesn't affect the normalization process. Unlike BatchNorm, which relies on batch statistics and can be influenced by factors like padding or batch size, LayerNorm operates on a per-sample basis. This makes it especially suited for tasks like natural language processing (NLP), where padding is frequently used.