Cache Hierarchy: Role in AI Model Inference
Cache hierarchy is a key factor in AI model performance. It speeds up data retrieval for processors, reducing delays caused by slow memory access. This layered system - comprising L1, L2, and L3 caches - helps bridge the gap between fast processors and slower main memory. For AI inference, where data movement often outweighs computation, efficient caching is critical.
Here’s why it matters:
- AI models are memory-bound: Tasks like token generation depend heavily on moving data, not just processing it.
- Cache levels reduce latency: L1 is the fastest and smallest, while L3 is larger but slower and shared across cores.
- KV cache in transformers: Models like Llama 2 require large memory for storing intermediate states during inference. Optimizing this usage can drastically improve speed.
- Local AI execution benefits: Tools like NanoGPT rely on cache management to run efficiently on personal devices, ensuring privacy and reducing reliance on cloud APIs.
For example, dynamic memory techniques like KV cache compression or quantization can cut memory usage by up to 8×, while methods like speculative retrieval can boost decode speed by 13×. Whether you're using a laptop or a high-end workstation, understanding cache behavior is essential for running AI models smoothly and cost-effectively.
LLM inference optimization: Architecture, KV cache and Flash attention
Cache Hierarchy Basics
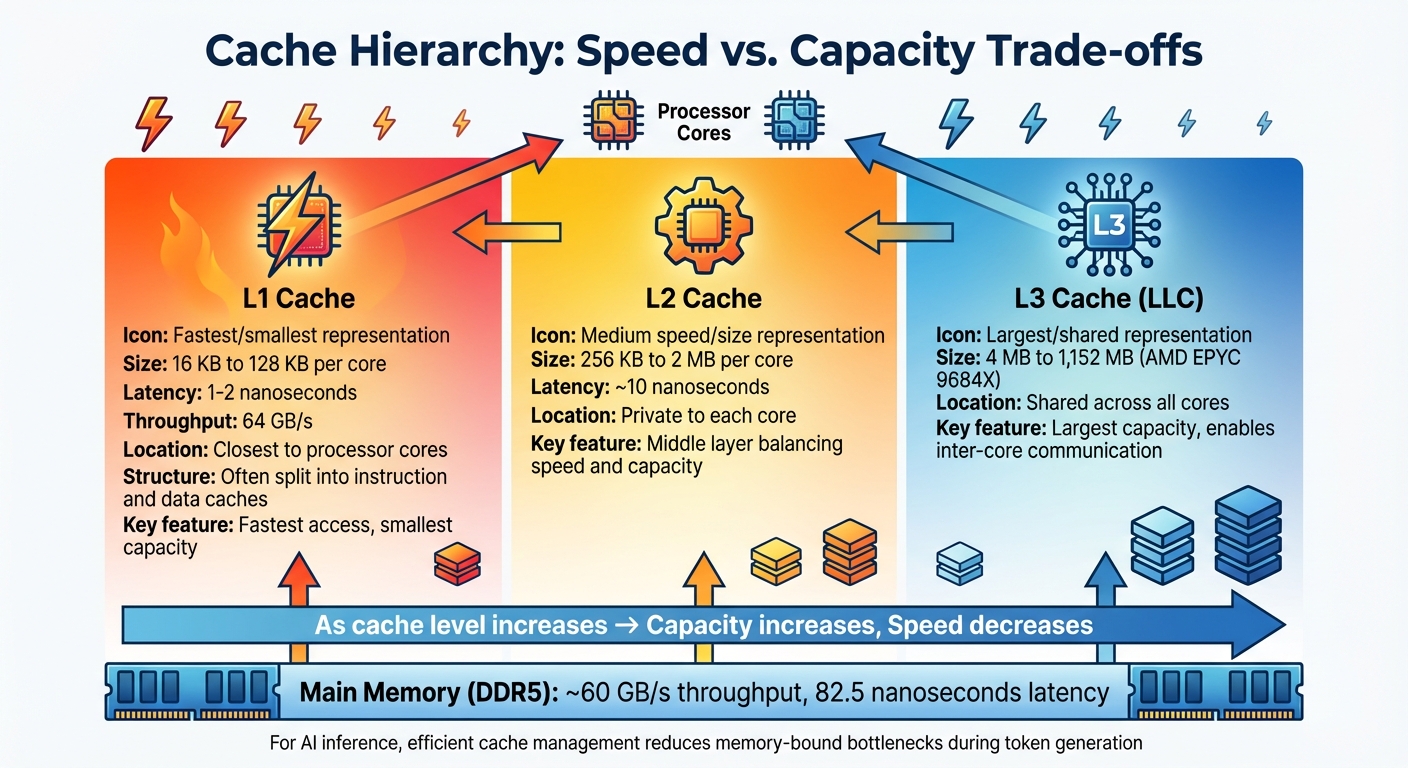
Cache Hierarchy Levels: Speed, Size, and Latency Comparison for AI Inference
Grasping the basics of cache hierarchy is essential for improving how AI models run efficiently.
Cache Levels and Structure
Modern processors rely on a three-tier cache system that balances speed and storage capacity. At the top is the L1 cache, which is closest to the processor cores. This cache usually ranges from 16 KB to 128 KB per core and delivers data incredibly fast - within 1–2 nanoseconds. To further boost efficiency, L1 cache is often divided into separate instruction and data caches, allowing simultaneous access.
Next, the L2 cache acts as a middle layer, typically offering 256 KB to 2 MB per core with a latency of about 10 nanoseconds. In most modern multicore setups, the L2 cache is private to each core, ensuring localized performance. Finally, the L3 cache, also known as the Last-Level Cache (LLC), is shared across all cores. Its size varies widely - from around 4 MB in consumer-grade processors to a massive 1,152 MB in AMD's EPYC 9684X server processors. This shared cache facilitates inter-core communication and minimizes data duplication. Together, the L1–L3 hierarchy significantly reduces the time needed to access data compared to relying solely on main memory.
Core Cache Concepts
To understand how cache structures enable efficient data handling, it’s important to grasp a few key ideas.
Locality of reference is a cornerstone of cache efficiency. This principle suggests that data recently accessed or located near other accessed data is more likely to be reused. When a processor looks for data, it checks each cache level in sequence. A "hit" means the data is found in the cache, allowing instant access. A "miss", however, means the processor must search lower cache levels or even main memory, which introduces delays. Cache misses are categorized into three types: cold misses (first-time access), capacity misses (when the cache is too small to hold all needed data), and conflict misses (when multiple data points compete for the same cache space). To maintain data consistency, systems use specific write policies to decide when cache updates are synchronized with main memory.
Cache Impact on Compute vs Memory-Bound Workloads
The efficiency of cache management plays a critical role in determining the performance of AI inference tasks, particularly when distinguishing between compute-bound and memory-bound workloads.
In compute-bound tasks, such as the prefill phase of large language model inference, the processor is primarily engaged in heavy-duty matrix-matrix calculations, pushing the processor's computational limits. On the other hand, memory-bound tasks are constrained by the speed of data transfers. These tasks often involve moving weights, keys, values, and activations through the memory hierarchy, where data transfer becomes the main bottleneck instead of computation.
During the decode phase of AI inference, frequent access to the key-value (KV) cache is needed for matrix-vector operations. If the working set of data exceeds the cache's capacity, performance slows down as the bottleneck shifts from processing power to data movement. In November 2025, researchers Zhongchun Zhou, Chengtao Lai, and Wei Zhang introduced LLaMCAT, a method designed to optimize the LLC for large language model inference. Their approach led to a 1.26× speedup in scenarios where throughput was limited and a 1.58× speedup when cache size was a restricting factor.
How Cache Hierarchy Affects AI Model Inference
Building on the fundamentals of caching, this section explores how AI models interact with cache systems and how these interactions influence inference performance.
Cache Usage Patterns in Common AI Models
AI models rely heavily on cache systems, but their demands vary based on architecture. For instance, transformer models like Llama 2 function in two key phases. During the prefill phase, the model performs compute-intensive matrix–matrix operations. In contrast, the decode phase generates tokens one at a time, creating memory-bound workloads that frequently access the Key-Value (KV) cache.
The KV cache is crucial for storing intermediate attention states, which prevents unnecessary recomputation of previously generated tokens. However, its size scales with both the model's depth and the sequence length. For example, a Llama 2 7B model running at 16-bit precision with a sequence length of 4,096 tokens and a batch size of 1 requires about 2 GB of memory for its KV cache.
Modern attention mechanisms aim to ease memory demands. Here’s a quick breakdown:
- Multi-Head Attention (MHA): Each attention head has its own key and value projections, consuming the most memory but delivering high-quality results.
- Multi-Query Attention (MQA): A single key–value head is shared across all query heads, reducing memory usage but potentially sacrificing accuracy.
- Grouped-Query Attention (GQA): Used in models like Llama 2 70B, this approach groups query heads to share fewer KV heads, balancing memory efficiency and performance.
For convolutional neural networks (CNNs), caching intermediate feature maps and preprocessing outputs helps minimize latency during cold starts. On the other hand, recommendation models with sparse embeddings often cause irregular memory access patterns. This can lead to cache thrashing when embedding tables exceed cache capacity, significantly impacting performance.
These diverse patterns highlight the specific challenges faced during the decode phase, where memory access becomes a critical bottleneck.
Decode-Phase Inference and KV Cache
The decode phase of transformer models is particularly demanding due to its reliance on the KV cache. Each step of autoregressive token generation requires the model to retrieve the entire KV cache from memory to compute attention for the next token. While the prefill phase writes key–value pairs to the cache, the decode phase is read-intensive, repeatedly accessing these pairs.
Where the KV cache is stored has a direct impact on throughput. Modern systems use a mix of high-bandwidth memory (HBM) on GPUs, off-package DRAM, and NVMe storage. Dynamic strategies that prioritize frequently accessed tokens for HBM while offloading less-used data to DRAM can improve throughput by up to 5.87× compared to static placement methods.
In October 2025, Character.AI introduced an inter-turn caching system that organizes KV attention in host memory using a Least Recently Used (LRU) tree structure. This approach enables adjacent model layers to share KV cache entries, achieving a 95% cache hit rate and cutting inference costs by over 20× for multi-turn customer support dialogues.
Performance Challenges and Optimization Options
Cache limitations can create significant bottlenecks, particularly during long-context inference. As sequence lengths grow, the KV cache expands linearly, increasing the likelihood of cache thrashing, where data is constantly evicted and reloaded. While the decode phase benefits from temporal locality (repeated access to the same KV pairs), spatial locality often suffers due to noncontiguous memory access across layers and heads.
Larger batch sizes and longer sequences exacerbate these issues by increasing the KV cache footprint and the number of memory accesses required. To address this, techniques like lower precision formats (e.g., FP8 or INT8) can reduce memory and bandwidth demands, though higher precision may still be needed for specific activations to handle outliers.
In June 2025, researchers improved the Qwen-R1 32B model using Dynamic Memory Sparsification (DMS). This method compressed the KV cache by 8× with just 1,000 training steps. The freed-up memory allowed the model to allocate more resources to reasoning tokens, resulting in performance gains of 9.1 points on AIME 24 and 9.6 points on LiveCodeBench.
Other advanced techniques include:
- PagedAttention: This method splits the KV cache into noncontiguous blocks, reducing memory fragmentation and supporting larger batch sizes.
- KVPR (Key-Value Partial Recomputation): By selectively recomputing cached values instead of retrieving them, this approach reduces latency by up to 35.8% and boosts throughput by 46.2% during decoding.
These strategies demonstrate how thoughtful memory management can overcome cache-induced challenges, paving the way for more efficient AI model inference.
Processor Architectures and Cache Behavior
Cache Design in CPUs, GPUs, and AI Accelerators
The way processors handle cache design plays a huge role in determining how efficiently AI inference tasks are performed. CPUs, for instance, are built with a multi-level cache system - L1, L2, and L3 - that's designed to reduce memory latency for tasks involving sequential operations and branching logic. This layered structure allows CPUs to quickly access frequently used data, making them an excellent choice for single-sample inference tasks, especially when working with small models where low latency is critical.
On the other hand, GPUs focus more on parallelism than cache capacity. Their design dedicates more transistors to computation rather than caching. For example, GPUs like the NVIDIA A100 and H100 offer memory bandwidths of up to 2,039 GB/s and 3.35 TB/s, respectively. This high bandwidth helps GPUs compensate for memory latency by executing tasks in parallel. While GPUs rely on smaller L1 caches per Streaming Multiprocessor and shared L2 caches across the chip, their ability to handle large-scale parallel tasks makes them ideal for batch processing.
AI accelerators, such as NPUs and TPUs, take an even more specialized approach. These chips are tailored for neural network workloads, utilizing systolic arrays and high-bandwidth on-chip memory to reduce the need for frequent access to main memory during matrix multiplications. This design allows AI accelerators to achieve energy efficiency levels that are 100 to 1,000 times better than general-purpose GPUs. However, this specialization comes at the cost of flexibility - these accelerators excel at specific AI tasks but may not perform as well with varied workloads.
For instance, when running a MobileNet v2 model, a modern CPU achieved 8 ms latency compared to 11 ms on a GPU, once data transfer times were factored in. This highlights how a CPU's cache hierarchy eliminates overhead caused by moving data between host and device memory, making it better suited for small models with tight latency demands. Meanwhile, GPUs shine in batch processing scenarios, with the NVIDIA H100 delivering a staggering 989 TFLOPS of TF32 Tensor Core performance, making it perfect for workloads where throughput takes precedence over individual latency.
| Feature | CPU | GPU | AI Accelerator (NPU/TPU) |
|---|---|---|---|
| Core Focus | Complex logic & sequential tasks | Massive parallel throughput | Specialized tensor/neural dataflow |
| Cache Structure | Deep L1/L2/L3 hierarchy | Small L1 per SM; shared L2 | High-bandwidth on-chip memory |
| Best Inference Use Case | Single-sample, small models, edge | Batch processing, large models | Real-time edge AI, cloud-scale LLMs |
| Memory Handling | Direct access to large system RAM | Limited VRAM (12GB–80GB) | Highly specialized/proprietary |
Next, let’s dive into how unified and separate cache designs further influence AI workload efficiency.
Unified vs Separate Instruction and Data Caches
The choice between unified and separate caches plays a critical role in AI workloads. At the L1 level, CPUs typically use separate instruction and data caches, a design inspired by the Harvard architecture. This separation allows the processor to fetch kernel instructions and load weights or activations simultaneously, avoiding bottlenecks. For workloads with diverse kernel sets and frequent instruction fetches, this approach minimizes contention.
At the L2 and L3 levels, however, processors often adopt a unified cache design. This setup provides flexibility, dynamically allocating space based on real-time needs. For example, transformer models can demand gigabytes of memory for key-value (KV) caches while requiring minimal space for kernel code. A unified cache can dedicate most of its capacity to data, ensuring efficient use of resources.
During the decode phase of large language model (LLM) inference, data cache efficiency becomes far more important than instruction cache performance. Kernel instructions often remain in the cache due to repeated execution, while the KV cache undergoes continuous updates and sequential access, putting significant pressure on the data side of the hierarchy. Techniques like FlashAttention combine multiple layers into a single kernel, reducing instruction fetch frequency while increasing the demand for effective data cache management.
This balance between instruction and data cache efficiency directly affects how well AI inference tasks are handled, as explored in the following hardware comparisons.
Cache Behavior Across Different Devices
Understanding how cache behaves across various devices is key to optimizing local AI inference. Platforms like NanoGPT demonstrate how cache performance can vary significantly between laptops, desktops, and workstations, creating challenges for running AI models on diverse hardware. For edge CPUs, performance can drop when workloads don’t align with cache boundaries or NUMA domains. For instance, a July 2025 benchmark on an AMD Ryzen 9 7845HX running LLaMA 3B and 8B models showed throughput hitting a limit beyond 16 threads due to synchronization overhead. In this case, the stock llama.cpp scheduler maxed out at 16 threads, while a custom dynamic scheduler smoothed out performance gains by reducing thread contention.
Memory bandwidth is another significant factor affecting performance on consumer devices. According to OpenInfer:
"LLM inference is not primarily compute-bound - it is memory and scheduling bound on CPUs."
Consumer hardware varies widely in memory bandwidth - laptops with LPDDR5X can offer around 100 GB/s, while desktops with DDR5 may reach up to 150 GB/s. This difference directly impacts throughput during the decode phase, even with optimized cache usage.
For NanoGPT users running models locally, these hardware differences can greatly influence the user experience. A desktop with ample L3 cache and higher memory bandwidth will handle longer context windows more smoothly than a laptop with more limited resources. Optimizations like quantizing models to INT8 can effectively double throughput by reducing memory traffic. Additionally, techniques such as thread pinning and core isolation can reduce tail latency by easing cache pressure from competing processes. Balancing cache performance across a range of hardware setups is critical for ensuring consistent and efficient AI inference on local devices.
sbb-itb-903b5f2
Optimizing AI Inference for Cache Efficiency
Hardware-Aware Optimization Strategies
Improving cache efficiency often starts with hardware-aware techniques. A standout method is operator fusion, which combines multiple computation steps into a single kernel. This keeps data in high-speed on-chip memory, avoiding the need to transfer it back and forth to slower main memory. For instance, FlashInfer has demonstrated impressive results, cutting inter-token latency by 29–69% and long-context latency by 28–30%.
Another effective approach is tiling, which breaks down large matrix operations into smaller, cache-friendly chunks. By dividing operations into blocks that fit neatly into the cache, tiling ensures compute units remain active and efficient.
Cache-targeted quantization further reduces memory bandwidth demands by shrinking the data size. Lowering precision (e.g., from FP16 to INT8 or FP4) allows more data to fit into the cache, easing bandwidth pressure. For example, a 70B-parameter model that would typically require 140 GB can be compressed to just 40 GB with aggressive quantization. Tools like LLM.int8() offer 2–4× model compression with minimal accuracy trade-offs, making local inference on consumer-grade hardware more feasible.
Building on these hardware-level strategies, specialized optimizations for the KV cache tackle the unique challenges of data growth during inference.
KV Cache-Specific Optimizations
The KV cache grows with every token generated, presenting unique hurdles. PagedAttention addresses this by dividing the cache into fixed-size blocks, similar to how operating systems manage virtual memory. This eliminates fragmentation and supports larger batch sizes without wasting GPU memory.
Another approach, Grouped-Query Attention (GQA), reduces the KV cache size by sharing keys and values across multiple attention heads. For example, in a 7B-parameter model with a 4,096-token context window, the KV cache can consume around 2 GB per batch. GQA significantly reduces this requirement, freeing up resources.
KV cache quantization compresses the cache into lower-precision formats like FP8 or NVFP4, targeting the memory footprint of stored key-value pairs. When combined with techniques like prefix caching, which reuses KV caches for frequently used prompt segments, redundant computations can drop by as much as 90%. Additionally, systems that implement intelligent KV cache routing have achieved dramatic improvements, such as reducing Time To First Token from 2,850 ms to just 340 ms for warm cache hits - an 88% improvement.
While these methods focus on hardware and KV-specific solutions, software-level strategies can also play a significant role in optimizing cache management.
Software Techniques for Cache Management
Software-level strategies enhance cache efficiency by improving resource utilization and ensuring smooth execution. One such method, continuous batching (also called in-flight batching), dynamically adds new requests to a batch as soon as others complete. This keeps GPU pipelines busy and maximizes utilization, particularly during the memory-bound decode phase when compute units often sit idle waiting for data.
Speculative retrieval is another game-changer, moving KV retrieval out of the critical path by reusing adjacent KV pages. By overlapping KV retrieval with other computations, this approach can achieve up to a 13× speedup compared to traditional methods. As Clarifai explains:
"Decode latency is fundamentally memory-bound; compute units often idle due to KV cache fetches."
For applications running on diverse hardware, tools like LMCache provide practical solutions. LMCache offloads KV caches from GPU memory to CPU DRAM or local storage, enabling cache reuse across different queries and inference engines. This method has delivered up to a 15× throughput improvement for tasks like multi-round question answering. It’s particularly beneficial for long context windows; for example, a Llama-3-70B model with a 128K context requires 40 GB of memory just for the KV cache of a single request. By offloading and reusing cache, LMCache makes such workloads far more manageable.
Cache Hierarchy Considerations for NanoGPT

NanoGPT takes a thoughtful approach to the challenges of cache hierarchies, adapting its strategies to meet the diverse needs of users across a wide range of devices.
Challenges of Different User Devices
User devices come with vastly different memory setups. For instance, a high-end gaming laptop might have 16 GB of GPU memory with high-bandwidth memory (HBM), while a typical consumer laptop relies on shared system RAM, which has lower bandwidth. On the other hand, mobile devices often use LPDDR5X memory, which brings its own unique cache hierarchy challenges.
Token generation highlights these memory limitations. NVIDIA researchers Michael Davies and Neal Crago reported that running a single user on Llama-405B with a 64K context uses 15.75 GB of KV cache. When scaled to a 32-user batch, this requirement skyrockets to 504 GB. Even smaller models face similar hurdles. For example, Llama 3 70B with a 128K context needs around 40 GB just for the KV cache.
Cache and memory bottlenecks are further underscored by performance metrics. For instance, an L1 cache can deliver 64 GB/s throughput with a latency of just 1 nanosecond, while DDR5 memory offers roughly 60 GB/s but with a much higher latency of 82.5 nanoseconds. NanoGPT addresses these disparities by dynamically managing data flow between on-chip memory and DDR5, ensuring efficient token generation even on hardware with limited resources.
Optimizing Models for Local Inference
NanoGPT tackles device variability with cache-aware configurations. One key method is dynamic input pruning, which reduces memory usage by 46% and boosts throughput by 40%. This technique adjusts to the current cache state and activation magnitude, ensuring high cache hit rates, especially on devices with limited resources.
For systems with unified memory architectures, NanoGPT employs strategies similar to those used by NVIDIA engineers in 2025. They successfully loaded a Llama 3 70B model - requiring about 140 GB in FP16 format - onto a system with only 96 GB of dedicated memory. This was achieved using unified memory management and a 900 GB/s NVLink-C2C interconnect, which provided seamless access to 480 GB of system memory, avoiding out-of-memory errors. NanoGPT mirrors this approach, using managed memory allocators to efficiently move data between GPU and CPU memory.
Additionally, the platform employs minimalist caching strategies, such as storing only the model topology and loading weights as needed. For browser-based inference, NanoGPT uses the Cache API to directly store model data, ensuring it remains accessible even after a browser reload.
Practical Benefits for Users
These optimizations directly benefit NanoGPT users in several ways. Its pay-as-you-go pricing model (starting at $0.10) ensures that every efficiency improvement translates into lower query costs. Better cache utilization speeds up token generation, reducing both the time and cost of interactions.
NanoGPT also prioritizes privacy. By enabling high-performance models to run locally - using techniques like aggressive quantization and smart cache management - it ensures user data stays on their own devices. For example, a model that would typically require 1,543 GB can be compressed to just 4 GB through distillation and quantization, making it feasible to run locally on standard laptops and mobile devices.
Users also see measurable performance gains. DRAM-based designs, which NanoGPT relies on for local inference, deliver better throughput per dollar than SRAM-based systems. Latency improvements range from 2.2× to 12×, depending on query patterns, while throughput increases significantly for tasks like multi-round conversations and document analysis. NanoGPT’s cache-aware strategies ensure even users with modest hardware can access advanced AI models without sacrificing speed or privacy.
Conclusion
Cache hierarchy plays a crucial role in making AI model inference efficient on local hardware. Smooth operation hinges on how well data moves between GPU memory, CPU DRAM, and storage. As researchers from Stanford and NVIDIA pointed out:
"The storage footprint of long-context caches quickly exceeds GPU memory capacity, forcing production systems to adopt hierarchical caching across memory hierarchies".
When cache optimization is overlooked, 74% of prefill time can be lost to I/O stalls. However, techniques like GPU-assisted I/O, 8-bit quantization (which reduces memory usage by 50% with only about 1% accuracy loss), and cache-aware scheduling can significantly boost throughput and response times . These improvements mean faster responses, lower operating costs, and the ability to run advanced models on everyday devices.
Such performance enhancements are especially vital for platforms focused on local execution. Take NanoGPT, for example: understanding and optimizing cache behavior is key not only for better performance but also for making AI more accessible. By using these techniques, NanoGPT improves efficiency and ensures user privacy through local execution. Its pay-as-you-go pricing model, starting at just $0.10, means that every optimization directly benefits users by lowering costs.
Intel researchers have shown how optimizing cache usage can drastically reduce latency. On a Xeon 8563C system, next-token generation latency dropped to 87.7 milliseconds when scaling from 2 to 8 sockets. Meanwhile, distillation methods have compressed model sizes from 1,543 GB down to 4 GB , making it feasible to run AI inference on standard laptops. Real-world tests confirm that efficient cache management is a game-changer for cost-effective AI applications.
Whether you're using a powerful workstation or a basic laptop, the fundamentals remain the same: understand your memory hierarchy, reduce unnecessary data movement, and maximize cache reuse. These strategies underline how smart memory management is the backbone of effective AI inference, shaping the user experience on any device.
FAQs
How does cache hierarchy enhance the performance of AI model inference?
Cache hierarchy plays a key role in speeding up AI model inference by optimizing how memory is accessed. Frequently accessed data, like key-value (KV) cache states and model parameters, is kept in faster memory, such as on-chip or GPU memory. Meanwhile, less critical data is moved to slower storage like DRAM or CPU memory.
This setup cuts down on memory-access delays, improves cache-hit rates, and reduces the need for recomputation. The outcome? Lower inference latency and higher throughput, making AI processing quicker and more efficient.
What is the purpose of the KV cache in transformer models like Llama 2?
The KV cache (Key-Value cache) is a mechanism that holds intermediate key and value tensors created during the processing of tokens. By leveraging these stored tensors for the next tokens, it avoids repeating attention calculations, which can dramatically accelerate inference in transformer models such as Llama 2.
This approach is especially useful for large-scale text generation tasks, as it cuts down on computational demands while maintaining the model's performance.
How does optimizing cache improve AI model performance?
Optimizing cache can significantly accelerate AI tasks by keeping frequently accessed data - such as activations or key-value states - in faster memory types like GPU memory or DRAM. This approach cuts down on repeated calculations and avoids costly memory transfers, saving both time and resources.
Using methods like hierarchical caching or lossy compression further reduces latency. This enables quicker token generation and boosts throughput, allowing AI models to handle larger volumes of data in less time while improving overall performance.