Cloud-Based Text-to-Speech: Multilingual Features Explained
Cloud-based text-to-speech (TTS) systems transform written text into natural-sounding audio using AI. These platforms now support over 75 languages and 380+ voices, making them a key tool for global communication, accessibility, and content creation. Businesses use multilingual TTS for customer support, training, and localization, while content creators rely on it for audiobooks, e-learning, and multimedia projects.
Key highlights:
- Language Coverage: Supports widely spoken languages (e.g., English, Spanish, Mandarin) and regional accents (e.g., U.S. vs. U.K. English).
- Customization: Adjust pitch, speed, tone, and add emotional styles for tailored outputs.
- Advanced Features: Use SSML (Speech Synthesis Markup Language) for precise control over pronunciation, pauses, and multilingual transitions.
- Providers: Top platforms include Microsoft Azure, Google Cloud, Amazon Polly, ElevenLabs, and Play.ht, each offering unique strengths like extensive voice libraries or high-quality audio.
Choosing the right TTS solution depends on your language needs, voice quality requirements, and budget. With rapid advancements, TTS is becoming more accessible and effective for diverse applications.
Supported Languages and Regional Variations
Most Common Supported Languages
Cloud-based TTS systems focus on a core group of widely spoken languages to connect with the largest audiences. Some of the most commonly supported languages are English, Spanish, French, Mandarin Chinese, German, Hindi, Arabic, Russian, and Portuguese. Major providers have built extensive voice libraries to serve global users. For instance, Microsoft Azure Neural TTS offers support for 140 languages and provides over 400 pre-built voices. This broad coverage makes it easier for businesses to reach customers across regions like North America, Europe, and Asia. Beyond just language support, these systems also fine-tune their outputs to reflect regional accents and dialects.
Regional Accents and Dialects
Modern TTS technology doesn’t stop at offering basic language options - it also captures the nuances of regional accents and dialects. Take English as an example: providers offer distinct variants such as U.S. English (en-US), British English (en-GB), Australian English (en-AU), and Indian English (en-IN). These variants account for differences in pronunciation, intonation, and rhythm that native speakers recognize.
To achieve this, TTS systems often rely on BCP‑47 locale codes, which specify regional variations. For example, selecting es-MX for Mexican Spanish produces different pronunciations and word choices compared to Castilian Spanish (es-ES). In June 2022, Microsoft expanded its Neural TTS service to include new regional accents, such as Sichuan and Liaoning variants for Mandarin, alongside Arabic variants for Lebanon and Oman. Advanced models like WaveNet are trained on recordings of regional speakers, allowing them to generate speech with natural emphasis and inflection. Newer systems, such as Gemini‑TTS, take this a step further by enabling users to define accents and speaking styles through natural-language prompts rather than relying solely on preset voice options. These advancements reflect a growing emphasis on regional authenticity, even as TTS providers extend their reach to less common languages.
Support for Less Common Languages
The TTS industry is also making strides to include languages spoken by smaller populations. While the top 70 languages cover over 80% of the world’s population, providers are now prioritizing low-resource languages to create high-quality neural voices, even with limited training data. Garfield He from Microsoft highlights this effort:
"While there are thousands of spoken languages in the world, the top 1% (~70 languages) accounts for the 80%+ of the global population... powered by the low resource setting TTS technology, we keep working to expand our capability to support those less touched languages".
Between June and December 2022 through 2025, Microsoft added nine low-resource languages to its Neural TTS portfolio, including Arabic (Lebanon and Oman), Azerbaijani, Bosnian, Georgian, Mongolian, Nepali, Albanian, and Tamil (Malaysia). Similarly, Google Cloud introduced HD voice support for languages like Punjabi (India), Hebrew, Bulgarian, Estonian, Basque, Galician, and Chinese (Hong Kong) by 2025.
This growing support for less common languages empowers organizations to connect with niche markets and linguistically diverse communities. Whether it's creating Tamil-language content for Malaysian audiences or delivering Punjabi voiceovers, modern TTS systems are increasingly equipped to produce natural-sounding speech that reflects regional identities and linguistic diversity.
sbb-itb-903b5f2
Customizing Multilingual TTS Output
Voice Selection and Personalization
Cloud-based text-to-speech (TTS) platforms typically offer three voice tiers: Standard, WaveNet/Neural2, and Studio, each with distinct pricing - $4.00, $16.00, and $160.00 per 1 million characters, respectively.** These tiers cater to multilingual needs by tailoring voice characteristics to different languages and regions. Users can further refine their output by adjusting parameters like pitch, rate, and volume using the <prosody> tag.
Some platforms, like Microsoft Azure, go a step further by offering speaking styles and roles. These include emotional tones such as cheerful, empathetic, or calm, and even specific personas like a child or senior. Azure also provides a styledegree attribute, enabling users to fine-tune the intensity of these styles on a scale from 0.01 to 2.
Using SSML for Advanced Customization

Speech Synthesis Markup Language (SSML) elevates TTS capabilities from simple text reading to a powerful audio production tool. As Nawaz Dhandala from OneUptime puts it:
"SSML transforms Cloud Text-to-Speech from a basic text reader into a professional audio production tool".
SSML offers granular control over elements like pronunciation, pacing, and language. Tags such as <say-as>, <phoneme>, <break>, <lang>, and <emphasis> allow users to manage how dates, technical terms, pauses, and multilingual transitions are handled. For instance, Google Cloud TTS supports SSML inputs of up to 5,000 characters per request, with generated audio capped at 240 seconds and 5 megabytes. This level of customization opens doors for applications in fields like language learning, customer support, and multimedia production.
Real-World Customization Examples
The flexibility of SSML brings practical benefits across various scenarios. For example, language learning platforms use the <prosody> tag to slow down speech to 0.9× the default rate, giving learners extra time to absorb pronunciation and vocabulary. Similarly, the <sub> tag can expand acronyms like "CI/CD" into full terms, ensuring clarity in educational or technical content.
In customer support, businesses optimize communication for non-native speakers by combining the customerservice speaking style with the <break> tag to insert 300-millisecond pauses between sentences. Audiobook producers use the <voice> tag to seamlessly switch between languages and characters - like alternating between French dialogue and English narration - while maintaining distinct voices.
E-commerce platforms also benefit from SSML's precision. Using the <say-as> tag with interpret-as="currency", they ensure prices are pronounced accurately. For example, "$49.99" is rendered as "forty-nine dollars and ninety-nine cents" in U.S. English, while adapting to local conventions in other languages.
Free Multilingual TTS | English TTS with Accent | E2-F5 + Fish Audio Tutorial
Comparing Multilingual Features Across Providers
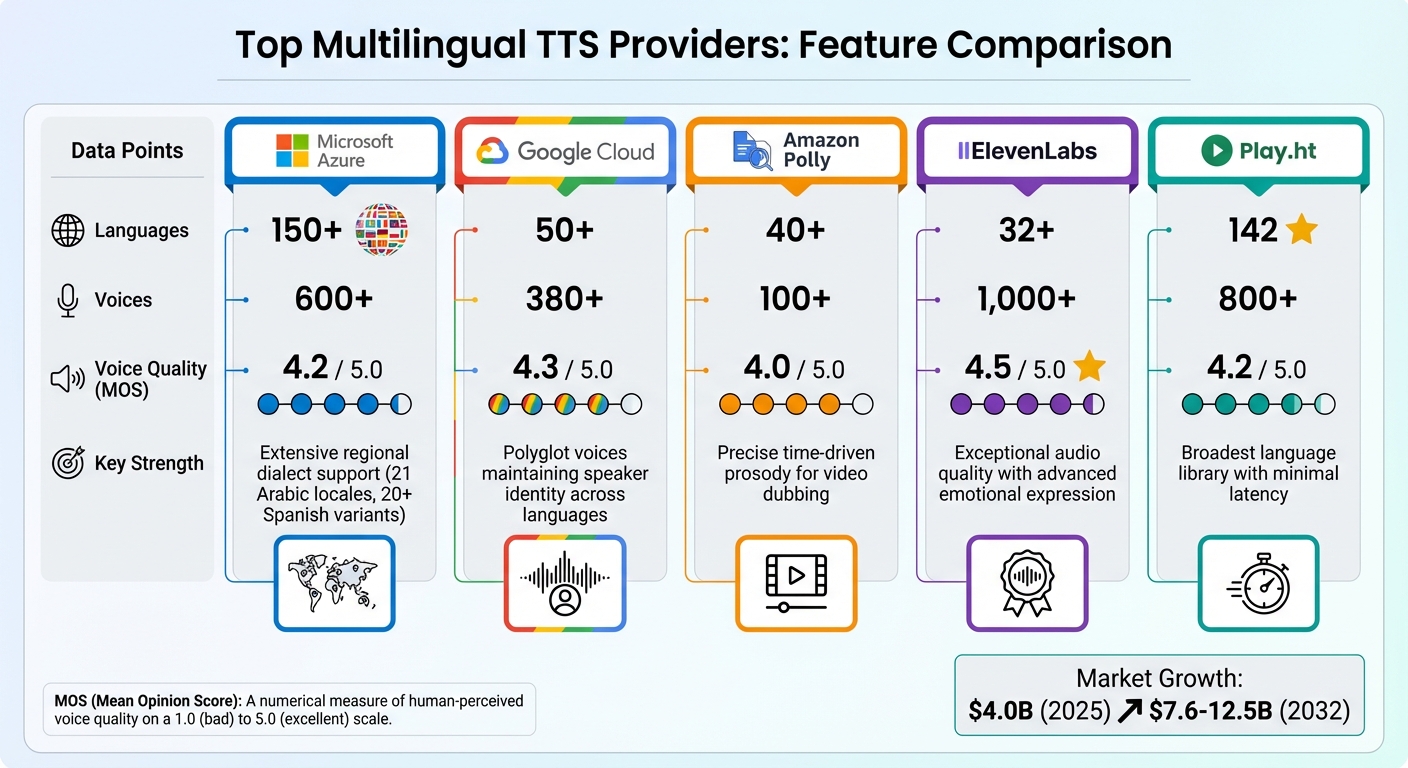
Multilingual TTS Provider Comparison: Languages, Voices, Quality and Strengths
When diving into multilingual text-to-speech (TTS) platforms, it's essential to weigh their strengths and trade-offs. Here's a closer look at what matters most and how key providers stack up.
What to Compare
When evaluating TTS platforms, focus on these critical aspects:
- Language Coverage: Look at both the number of supported languages and the availability of regional variants. For example, does the provider differentiate between Mexican, Castilian, and U.S. Spanish, or just offer a generic "Spanish" option?
- Voice Quality: Often measured using the Mean Opinion Score (MOS), which rates naturalness on a 1.0 to 5.0 scale.
- Customization Options: Ranges from basic pitch adjustments to advanced controls for emotional tones and prosody, particularly useful for dubbing.
- Pricing Structure: Providers vary significantly in cost, depending on voice tiers and usage.
The table below summarizes how top platforms compare across these criteria.
Provider Comparison Table
| Provider | Languages | Voices | Voice Quality (MOS) | Key Strength |
|---|---|---|---|---|
| Microsoft Azure | 150+ | 600+ | 4.2/5.0 | Extensive regional dialect support, including 21 Arabic locales and 20+ Spanish variants |
| Google Cloud | 50+ | 380+ | 4.3/5.0 | Polyglot voices that maintain speaker identity across languages |
| Amazon Polly | 40+ | 100+ | 4.0/5.0 | Precise time-driven prosody for video dubbing |
| ElevenLabs | 32+ | 1,000+ | 4.5/5.0 | Exceptional audio quality with advanced emotional expression |
| Play.ht | 142 | 800+ | 4.2/5.0 | Broadest language library with minimal latency |
The multilingual TTS market is booming. It hit $4.0 billion in 2025 and is forecasted to grow to between $7.6 billion and $12.5 billion by 2032. Providers like Microsoft Azure dominate with scale, offering over 600 neural voices in 150+ languages, while Google Cloud focuses on delivering top-tier quality with its WaveNet and Chirp 3 HD models.
Strengths and Weaknesses of Each Provider
The table gives a quick overview, but here's a deeper dive into what each provider brings to the table - and where they stumble.
- Microsoft Azure: Known for its unparalleled regional granularity, it's ideal for projects requiring specific dialects. Its emotional styling enhances audiobooks, but the platform can be tricky to master, and custom voice creation requires approval [[24]](https://tts.barrazacarlos.com/blog/The Best Neural TTS Models & Their Differences (Google, Microsoft, Amazon Polly)).
- Google Cloud: With its WaveNet technology, it offers some of the most natural-sounding voices, achieving a 4.3/5.0 MOS rating. Polyglot voices allow seamless language switching, making it great for maintaining a consistent brand voice across markets. However, its premium Chirp 3 HD voices lack support for SSML and pitch adjustments, limiting flexibility.
- Amazon Polly: A strong choice for those already using AWS, Polly offers a generous free tier - 5 million characters per month for 12 months [[24]](https://tts.barrazacarlos.com/blog/The Best Neural TTS Models & Their Differences (Google, Microsoft, Amazon Polly)). Its time-driven prosody makes it perfect for syncing speech with video frames. However, it falls short in the number of voices and emotional expressiveness compared to competitors.
- ElevenLabs: Leading the pack in audio quality with a 4.5/5.0 MOS score, ElevenLabs shines in high-quality content creation like marketing videos and audiobooks. Its focus on fewer languages but deeper voice customization makes it a premium option. Pricing starts with a free tier but can go up to $1,320 per month for 11 million characters.
- Play.ht: If you're looking for extensive language support, Play.ht is unmatched, offering 142 languages and 800+ voices. Its low-latency performance is another standout feature, rivaling even specialized platforms like Smallest.ai, which boasts 100ms response times compared to the 300–800ms norm.
Each provider has its niche, whether it's the sheer scale of Microsoft Azure, the quality focus of Google Cloud, or the emotional depth of ElevenLabs. Choosing the right one depends on your specific needs and priorities.
Integrating Multilingual TTS into Global Applications
Scaling for International Businesses
Expanding multilingual text-to-speech (TTS) capabilities for global applications requires technical solutions that can scale effectively. REST APIs and specialized SDKs like Node.js or Python are key tools for real-time TTS integration. Choosing the right model is equally important: high-definition options such as Google Chirp 3: HD work well for e-learning narrations, while budget-friendly models like gpt-4o-mini-tts (priced at $0.0006 per 1,000 characters) are better suited for high-volume use cases like customer service.
For interactive applications, streaming is essential. Using chunked streaming (stream: true) reduces latency by starting playback almost immediately. Additionally, polyglot voices ensure consistent branding across multiple languages, whether you're addressing users in English, Spanish, or Mandarin. Microsoft Azure Neural TTS, for instance, supports over 330 neural voices and 129 languages and dialects, making it a reliable choice for large-scale operations.
Once scalability is in place, localization becomes the next step in creating a seamless user experience.
Localization for Better User Experiences
Generic language support isn’t enough for effective communication - regional nuances make a big difference. For example, choosing "Spanish [Mexico]" instead of "Spanish [Spain]" ensures content resonates with the intended audience. Developers can further refine localization with Speech Synthesis Markup Language (SSML), which allows for features like pauses, emphasis adjustments, and proper handling of acronyms. These tools are especially useful for applications in education and professional training.
Managing resources efficiently also enhances performance. Caching audio URLs or files on the client side reduces redundant API calls, cutting down on latency and billing costs. For static content like IVR menus or training modules, batch synthesis is a practical way to generate all required prompts at once. Advanced solutions like Meta's Massively Multilingual Speech project, which supports over 1,100 languages, or Kokoro-82m, offering 44 voices across 13 language groups, further expand localization options.
Privacy and Data Security
Securing user data is just as important as functional deployment and localization. Start by managing API keys securely through server proxies to avoid exposing them on the client side. Redacting personally identifiable information (PII) from logs before sending text to TTS providers is another critical step. For organizations with strict data residency requirements, providers like Google Cloud offer regional endpoints (e.g., "global", "eu", and "us"), though some high-definition models, such as Chirp 3: HD, may not support these regional options.
Platforms like NanoGPT tackle privacy concerns by storing data locally on user devices rather than relying on the cloud. This approach addresses privacy at its core while offering access to various TTS models, including Kokoro-82m ($0.001 per 1,000 characters) and Elevenlabs-Turbo-V2.5 ($0.06 per 1,000 characters), all on a pay-as-you-go basis. Implementing Trusted Execution Environments (TEE) with attestation and hardware-level security adds another layer of protection. Additionally, rate limiting on public-facing routes prevents resource misuse, while automated content policy checks ensure compliance with usage guidelines.
Conclusion and Key Takeaways
The Importance of Multilingual TTS
Multilingual text-to-speech (TTS) technology is breaking down language barriers, enabling organizations to connect with audiences across the globe. Modern cloud-based TTS systems not only support a variety of widely spoken languages, but they also incorporate regional accents and dialects. For instance, a Mandarin speaker in Sichuan can hear content that feels tailored to their local community, rather than something that sounds generic or overly formalized. Advanced systems even auto-detect languages, seamlessly adjusting pronunciation and intonation. As Dan Aharon, Product Manager at Google Cloud, explains:
Businesses that offer human-sounding voices offer the best experiences for their customers, and if that experience can also be provided in numerous languages and countries, that advantage becomes global.
This progress makes TTS a practical tool for everything from AI-powered contact centers to IoT devices in cars and homes. The numbers back this up: the global AI voice market is expected to grow from $4.16 billion in 2025 to $20.71 billion by 2031. For companies looking to expand internationally, multilingual TTS is essential for creating consistent brand personas and empowering users worldwide. With these benefits in mind, selecting the right TTS platform is more important than ever.
How to Choose the Right Solution
When choosing a multilingual TTS platform, start by ensuring it covers the specific languages and locales your audience speaks. For example, simply supporting "Spanish" isn’t enough - you’ll want to confirm if the provider offers LATAM Spanish versus Spain Spanish, or Canadian French versus European French. Next, consider the type of voice technology you need. Standard voices are fine for high-volume, less critical tasks, but for customer-facing applications, Neural2 voices strike a good balance between sounding natural and being cost-effective. For real-time interactions, like conversational agents, prioritize low-latency streaming options such as Chirp 3: HD.
Customization is another key factor. Look for features like SSML (Speech Synthesis Markup Language) support and custom lexicons to handle brand names, technical jargon, and local expressions accurately. Testing the system with native speakers early on can help identify any awkward pacing or pronunciation issues that automated tools might miss. For global brands, polyglot voices - those that maintain a consistent speaker identity across multiple languages - can be a valuable feature. Lastly, if you’re planning to use TTS for monetized content like ads or audiobooks, make sure to verify the platform’s commercial rights and usage policies.
Platforms like NanoGPT simplify the decision-making process by offering access to various TTS models. Whether you’re looking for budget-friendly options like Kokoro-82m (priced at $0.001 per 1,000 characters) or premium choices like Elevenlabs-Turbo-V2.5 ($0.06 per 1,000 characters), these platforms let you pay as you go, with no subscription fees. Plus, by storing data locally on your device, they address privacy concerns right at the source.
What's Next for Multilingual TTS
The future of multilingual TTS is heading toward even more advanced capabilities. Zero-tagging auto-detection is on the horizon, where AI will dynamically identify the language of each sentence and adjust its delivery on the fly. High-definition conversational voices are becoming more refined, capturing subtle human intonations for real-time applications, making interactions feel natural and engaging. Additionally, TTS technology is expanding to include low-resource languages, opening up new opportunities for underserved communities.
Another exciting development is cross-lingual custom voices, which allow businesses to create a unique brand voice that can speak multiple languages while maintaining its distinct character. Instruction-based synthesis is also gaining traction, enabling users to specify tone - whether warm, urgent, or formal - for more contextually appropriate output. As these features evolve, multilingual TTS is set to become more accessible, budget-friendly, and indistinguishable from human speech across a wider range of languages and dialects. These advancements highlight a central theme: integrating multilingual TTS effectively and at scale is key to achieving global communication success.
FAQs
How do I pick the right locale (like en-US vs en-GB) for my audience?
To connect with your audience effectively, start by identifying their regional preferences using analytics tools. For example, if your audience is primarily in the U.S., you’d choose en-US, while for the U.K., en-GB would be more appropriate. Similarly, if you’re targeting Spanish speakers in Mexico, opt for es-MX.
It’s also crucial to use regional API endpoints that match your audience’s location. This ensures both compliance with local regulations and optimal performance. Additionally, programmatically validate voice options to confirm they align with the specific region and dialect you’re targeting. This approach guarantees that your content resonates with your audience, both linguistically and culturally.
What’s the easiest way to switch languages in one audio clip using SSML?
The easiest way to alternate between languages in a single audio clip is by utilizing multiple <voice> elements in your SSML (Speech Synthesis Markup Language) document. Each <voice> element can be assigned a specific language or voice, enabling smooth transitions between different languages.
Here’s an example of how it works:
<speak>
<voice name="en-US-Standard-B">Hello, how are you?</voice>
<voice name="es-ES-Standard-A">Hola, ¿cómo estás?</voice>
</speak>
In this case, the first <voice> element uses an English (United States) voice, while the second switches to a Spanish (Spain) voice. This approach ensures clear and natural delivery for multilingual content within a single audio file.
How can I keep user data private when sending text to a cloud TTS API?
When working with a cloud TTS API, safeguarding user data should be a top priority. One way to do this is by avoiding participation in data logging programs. Providers like Google typically process text or audio content solely to deliver the service and won’t store or reuse it unless you explicitly opt into these programs. Always take the time to review the API's privacy policies carefully to ensure they align with your data protection requirements.