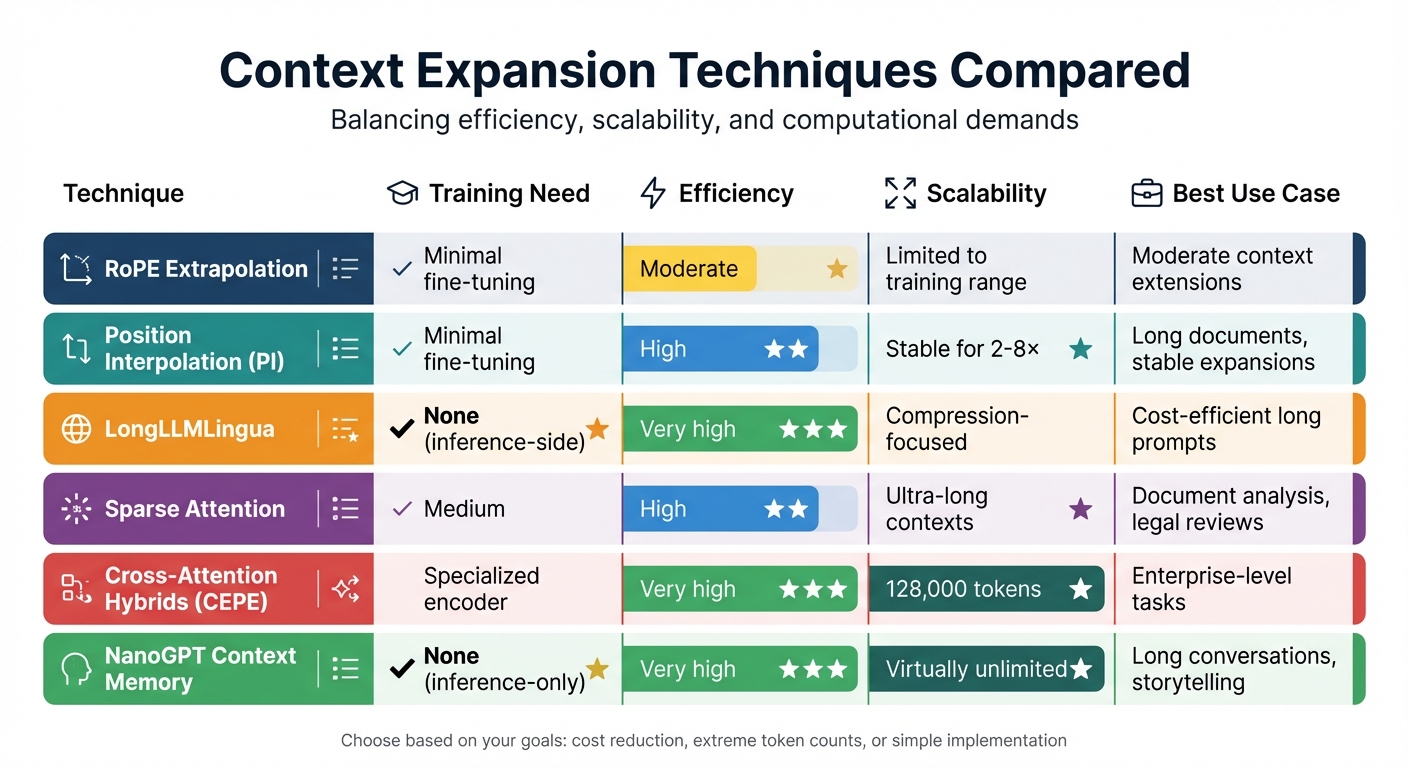
Efficient Context Expansion: Techniques Compared
When it comes to expanding a model's context window - its ability to process longer inputs - six key techniques stand out. Each offers unique benefits and trade-offs, balancing efficiency, scalability, and computational demands. Here's a quick overview:
- RoPE Extrapolation: Extends positional encoding but struggles with unseen token distances. Works well for moderate expansions with minimal fine-tuning.
- Position Interpolation (PI): Compresses longer sequences into the model's original context size, offering stability and simplicity without architectural changes.
- LongLLMLingua: Focuses on compressing prompts by selecting the most relevant information, reducing token usage and costs significantly.
- Sparse Attention: Reduces computational complexity by limiting attention to select token pairs, enabling efficient processing of ultra-long sequences.
- Cross-Attention Hybrids (CEPE): Uses a small encoder to preprocess long inputs, passing the data to the main model via cross-attention, cutting memory use drastically.
- NanoGPT's Context Memory: Hierarchically compresses conversation history, managing vast amounts of context without altering the model.
Each method fits different needs, from cost-saving compression to handling millions of tokens. Below is a quick comparison:
| Technique | Training Need | Efficiency | Scalability | Best Use Case |
|---|---|---|---|---|
| RoPE Extrapolation | Minimal fine-tuning | Moderate | Limited to training range | Moderate context extensions |
| Position Interpolation | Minimal fine-tuning | High | Stable for 2–8× | Long documents, stable expansions |
| LongLLMLingua | None (inference-side) | Very high | Compression-focused | Cost-efficient long prompts |
| Sparse Attention | Medium | High | Ultra-long contexts | Document analysis, legal reviews |
| CEPE Hybrids | Specialized encoder | Very high | 128,000 tokens | Enterprise-level tasks |
| NanoGPT Context Memory | None (inference-only) | Very high | Virtually unlimited | Long conversations, storytelling |
Choosing the right method depends on your goals - whether it's reducing costs, handling extreme token counts, or simplifying implementation. Let’s dive into how each approach works and its practical applications.
Context Expansion Techniques: Comprehensive Comparison of 6 Methods
Long-Context LLM Extension
sbb-itb-903b5f2
1. RoPE Extrapolation
RoPE (Rotary Position Embedding) is a widely used method in models like Llama 3, Mistral, and Gemma-2. Instead of adding positional information separately, RoPE integrates it by rotating query and key vectors. This creates a natural weakening of attention between tokens as their distance increases, often referred to as "decaying inter-token dependency".
RoPE operates using a multi-scale representation. In this setup, dimensions with faster rotations focus on local positions, while slower-rotating dimensions capture broader, global patterns. Michael Brenndoerfer explains it well:
"The fastest dimension pairs complete a full rotation every few positions, making them sensitive to fine-grained local position distinctions. The slowest dimension pairs complete a rotation only after tens of thousands of positions, making them sensitive to coarse global structure".
This balance between local and global encoding defines RoPE's unique approach and its impact on model performance.
Efficiency
RoPE stands out for its efficiency by embedding positional information directly into the self-attention mechanism, eliminating the need for additive positional embeddings. However, this efficiency diminishes when models are pushed beyond their trained context length. For instance, models trained on a 2,048-token context length often falter when extended to 8,192 tokens. This happens because the rotation angles exceed their training range, leading to issues like incoherent outputs or treating distant tokens as equally relevant.
Scalability
Efforts to scale RoPE have led to some major advancements. In July 2024, researchers Yiran Ding, Li Lyna Zhang, and their team at Microsoft Research Asia introduced LongRoPE, which extended the context window of LLaMA2 and Mistral models to 2,048,000 tokens using only 1,000 fine-tuning steps. Building on this, LongRoPE2 achieved a context window of 128,000 tokens for LLaMA3-8B with just 10 billion tokens - requiring 80 times fewer resources compared to Meta's standard approach - while maintaining over 98.5% of the performance for shorter contexts. These advancements hinge on careful training modifications.
Training Requirements
Extending RoPE effectively isn't as simple as scaling it linearly. It requires non-uniform rescaling, where different dimensions are adjusted independently instead of applying the same scale across all. LongRoPE2 takes this a step further by using evolutionary search guided by "needle-driven" perplexity to optimize rescaling factors, addressing gaps in training for higher RoPE dimensions. To ensure consistent performance across both long and short sequences, models should be fine-tuned with a mix of rescaled RoPE for long contexts and original RoPE for shorter ones.
2. Position Interpolation (PI)
Position Interpolation (PI) takes a different approach compared to RoPE's extrapolation by focusing on compressing longer sequences to fit within the model's existing context window instead of extending beyond it.
As explained by researchers at Continuum Labs, "Instead of guessing beyond known data, it compresses or scales down larger inputs to fit within the model's original context window". For example, a model trained on 2,048 tokens can handle sequences as long as 32,768 tokens by proportionally scaling down the position indices.
One of PI's key advantages is its mathematical stability. Research shows that attention scores calculated through interpolation are significantly more stable, with an upper bound roughly 600 times smaller than scores from extrapolation methods. This stability helps avoid severe issues where models might produce incoherent outputs or incorrectly assign equal importance to all tokens, regardless of their distance. Unlike RoPE extrapolation, PI emphasizes simplicity and stability rather than extending token rotations.
Efficiency
PI is efficient because it doesn't require changes to the model's architecture or additional parameters. Developers can continue using existing optimization tools and hardware without any modifications. Mathematically, PI works by increasing the RoPE base frequency constant. For instance, extending the context by 4× effectively raises the base frequency from 10,000 to 40,000. However, this comes with a trade-off: linear scaling compresses the positional coordinate system evenly, which reduces the resolution between adjacent tokens. As a result, models may struggle to distinguish fine-grained positional relationships in extremely long contexts.
Training Requirements
In June 2023, researchers Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian from Meta Platforms Inc. implemented PI on the LLaMA model family (ranging from 7B to 65B parameters). They expanded the context window from 2,048 tokens to 32,768 tokens using just 1,000 fine-tuning steps on the Pile dataset with the AdamW optimizer and FlashAttention. They noted:
"Position Interpolation can easily enable very long context windows (e.g. 32768), requiring only fine-tuning for 1000 steps on the Pile to achieve a good quality. The cost of fine-tuning is negligible compared to the pre-training costs".
This contrasts sharply with direct fine-tuning, which only increased the context window from 2,048 to 2,560 tokens after 10,000 batches.
The fine-tuning process uses standard techniques like next-token prediction, linear learning rate warm-up, and memory-efficient tools such as PyTorch Fully Sharded Data Parallel (FSDP). These practices help the model adapt to the compressed positional space, where smaller angular differences now represent larger distances. This adjustment is much simpler than learning entirely new rotation patterns.
Use Cases
PI's ability to extend context windows has made it useful for various applications. It is particularly effective for tasks requiring extended context, such as summarizing lengthy documents, maintaining coherence in long-form conversations, processing extensive codebases, and retrieving specific information from large texts. Additionally, the expanded context window enhances retrieval-augmented generation (RAG) by allowing more documents to be included in prompts. PI has been successfully applied across models ranging from 7B to 65B parameters, with these models retaining over 98% of their original performance on benchmarks while handling contexts up to 16 times longer.
3. LongLLMLingua
LongLLMLingua is a technique designed to condense lengthy prompts into a compact, information-rich format that fits within the token limits of existing language models. Instead of increasing a model's capacity, it focuses on selecting only the most relevant parts of a document to include in the prompt, cutting out unnecessary content before it reaches the main language model.
This method addresses a common issue called position bias - often referred to as the "lost in the middle" problem - where language models struggle to retrieve important information buried within long prompts. Microsoft researcher Huiqiang Jiang and colleagues noted:
"LLMs exhibit position bias... suggesting that the placement of key information within the prompt significantly affects LLMs' performance".
To combat this, LongLLMLingua reorganizes documents so that the most critical details appear at the beginning or end of the prompt, improving how efficiently the model processes information.
Efficiency
LongLLMLingua delivers impressive improvements in both cost and speed. According to 2024 benchmarks, it reduced costs by 94.0% in the LooGLE benchmark and improved performance in the NaturalQuestions benchmark by up to 21.4%, all while using 4× fewer tokens. For prompts around 10,000 tokens long, the method reduces latency by 1.4× to 2.6× and achieves compression rates between 2× and 20× with minimal loss of meaning.
These results are made possible by using a smaller, lightweight model (like LLaMA-2-7B) to handle the compression. This approach is far more economical than running the entire prompt through a large language model. The system uses contrastive perplexity to identify the tokens most relevant to the user's query, while a dynamic compression ratio ensures that critical content gets more space in the token budget, compressing less important sections more aggressively.
Training Requirements
One of the standout benefits of LongLLMLingua is that it doesn't require extensive retraining of large language models. Instead, it operates as a plug-and-play API solution, relying on a pre-trained small language model to handle the compression. This means developers can integrate it easily into existing workflows without modifying their primary models. It also works seamlessly with popular retrieval-augmented generation (RAG) frameworks like LangChain and LlamaIndex, making it a practical choice for production-level AI systems.
Use Cases
LongLLMLingua shines in scenarios that involve analyzing lengthy documents (10,000+ tokens) or working with RAG systems that need to process large amounts of retrieved data. In a 2024 evaluation using the NaturalQuestions benchmark, it achieved a 75.0% accuracy rate at 4× compression, compared to just 54.1% for uncompressed prompts when the correct answer was located in the 10th position of the context.
This technique is particularly useful for tasks like multi-document question answering, managing multi-turn chat histories, code completion, and document summarization. By addressing position bias, it complements other methods aimed at extending model capabilities, ensuring that critical information remains accessible even in long prompts. However, for shorter prompts, the overhead introduced by the compression model may outweigh its benefits, so it’s best suited for longer, more complex inputs.
4. Sparse Attention
Sparse attention tackles the challenge of quadratic attention complexity by narrowing the focus of each token to a subset of the sequence. Instead of calculating attention scores for every token pair - which scales at O(n²) - this method reduces complexity to near-linear levels, such as O(n log n) or even O(n). This makes it possible to process much longer sequences without maxing out computational resources.
This technique shines when tokens primarily rely on nearby context for meaning, rather than distant parts of a sequence. Over time, implementations have evolved from basic sliding windows to more dynamic systems. For example, DeepSeek's Native Sparse Attention (NSA) uses a "Lightning Indexer" to dynamically scan and identify relevant token blocks, achieving an impressive 11× speed boost during decoding for sequences of 64,000 tokens. Similarly, PowerAttention, tested on the Qwen2-7B model in March 2025, demonstrated a 3.0× speed improvement for 128,000-token contexts while maintaining strong benchmark performance on tasks like Passkey Retrieval and RULER. These advancements extend context capabilities while lightening the computational load.
Efficiency
Sparse attention delivers major gains in both speed and memory efficiency. High-performance implementations can achieve up to 94% sparsity - meaning only 6% of token pair scores are computed - without sacrificing accuracy. Studies show that just the top 10% of token positions account for 38% of total attention weight.
By focusing on fewer tokens, sparse attention significantly reduces the size of the Key-Value (KV) cache, which otherwise grows linearly with sequence length and can quickly hit hardware limits. Advanced architectures like Memory Sparse Attention (MSA), introduced by EverMind in March 2026, address this by offloading large KV caches to CPU DRAM while keeping essential routing keys on GPU VRAM. This approach enabled processing sequences as long as 100 million tokens on just two NVIDIA A800 GPUs - hardware typically limited to around 160 GB of memory. The trade-off? A small drop in accuracy, from 98.77% at 32,000 tokens to 94.84% at 1 million tokens.
Scalability
Sparse attention scales exceptionally well for ultra-long sequences. For example, the MOBA model achieved a 10× performance boost when handling 10 million tokens, and DeepSeek V3 operates at roughly half the FLOPs of dense models.
However, scalability comes with compromises. Sparse attention approximates relationships, which means it may miss some global context when processing long prompts with non-local dependencies. To mitigate this, modern architectures combine local sparse patterns with global "hub" tokens or random attention links, as seen in models like Longformer and BigBird. Techniques like PowerAttention use power-of-2 distances to expand the receptive field exponentially across layers, allowing a model with d layers to attend to 2ᵈ tokens.
Training Requirements
One advantage of sparse attention is its minimal training overhead. Static patterns, such as sliding windows or fixed power-of-2 distances, can be implemented without retraining, though fine-tuning may enhance results. Dynamic patterns, like DeepSeek's NSA, require training a lightweight "router" module to determine relevant tokens. However, this is far less resource-intensive than retraining an entire model. Sparse attention is often a plug-and-play optimization, further boosted by hardware-aware kernels like FlashAttention, which translate theoretical efficiency into real-world speed.
The choice of pattern depends on the use case: static patterns offer faster decoding and simpler optimization, while dynamic patterns provide flexibility but come with higher inference costs. These modest training requirements make sparse attention a practical tool for long-context tasks.
Use Cases
Sparse attention excels in tasks where nearby tokens carry most of the meaning, such as document analysis, legal contract review, and understanding large codebases. For instance, when analyzing a 400-page contract, sparse attention can identify contradictory clauses across the entire document without the chunking limitations of retrieval-augmented generation (RAG) systems. It’s especially effective for generating extensive "Chain-of-Thought" sequences, where models must navigate their own reasoning across thousands of tokens. Other applications include answering questions across multiple documents, completing code that spans multiple files, and summarizing lengthy research papers.
That said, for simple fact-based queries where the information is confined to a specific section, RAG may be more cost-efficient than processing the entire context with sparse attention. The key is to match the technique to the task: use sparse attention for synthesizing information from an entire document, and RAG for pinpointed retrieval. This balance makes sparse attention a powerful tool for extending model context windows efficiently.
5. Cross-Attention Hybrids (CEPE)
Cross-Attention Hybrids take a different approach to extending context by dividing the workload between two components. The Context Expansion with Parallel Encoding (CEPE) framework uses a small, bidirectional encoder to process lengthy inputs in chunks, while the main decoder-only large language model (LLM) remains unchanged. Instead of making the entire model handle massive sequences through self-attention, the encoder takes on the bulk of the work and passes the processed information to the decoder using cross-attention modules embedded in every decoder block. This chunk-based processing sidesteps the quadratic complexity that traditional self-attention methods face. Below, we’ll explore CEPE’s efficiency, scalability, training simplicity, and its practical applications.
Efficiency
CEPE builds on earlier methods by utilizing cross-attention to streamline context processing. It achieves 10× throughput and uses just 1/6 of the memory compared to standard long-context transformer models. This efficiency comes from shifting most of the context processing to the small encoder, which works on chunks of input in parallel. Meanwhile, the frozen decoder focuses solely on generating outputs.
In February 2024, researchers applied the CEPE framework to the Llama-2 model, successfully expanding its context window to 128,000 tokens. They accomplished this by adding cross-attention modules to the frozen Llama-2 decoder and employing a small bidirectional encoder to handle inputs chunk-by-chunk. Remarkably, even though the model was only trained on 8,000-token documents, it achieved the extended context window while maintaining 10× throughput and significantly reduced memory requirements.
Scalability
CEPE is highly scalable, allowing models to process far beyond their initial training limits. For instance, models trained on just 8,000-token documents can extend their context window to 128,000 tokens without suffering the typical performance issues associated with positional encoding extrapolation. This framework ensures consistent performance on tasks like language modeling and in-context learning, avoiding the common pitfalls of retrieval-augmented approaches, such as performance degradation.
Training Requirements
One of CEPE's standout features is its low training overhead. During the context expansion process, the decoder-only LLM remains frozen, and training is limited to the small encoder and the newly added cross-attention layers. This approach allows CEPE to unlock 128,000-token capabilities from models trained on just 8,000-token documents. Additionally, CEPE can extend the context window of instruction-tuned models like Llama-2-Chat using only unlabeled data, preserving their instruction-following abilities without requiring extensive retraining.
Use Cases
CEPE is particularly effective in tasks that demand processing over 100,000+ tokens. It’s ideal for multi-document question answering, where synthesizing information from multiple sources is critical. The framework also excels in retrieval-augmented generation, a domain where standard long-context models often falter when handling large retrieved contexts. Other strong applications include long-form summarization, complex instruction-following tasks that depend on dispersed information across extensive contexts, and in-context learning, where the model processes numerous examples provided in the prompt. CEPE complements other methods discussed, offering a distinctive solution to the challenges of context expansion.
6. NanoGPT
NanoGPT introduces a novel way to handle context expansion with its Context Memory feature. This feature uses a hierarchical B-tree compression system to manage conversation history without altering the model's architecture. Instead of increasing the number of tokens a model can process, NanoGPT compresses extensive conversation histories - sometimes exceeding 500,000 tokens - into a manageable active context of about 8,000–20,000 tokens. This approach avoids the computational challenges of traditional transformers while maintaining full access to the entire conversation history in a lossless manner.
Efficiency
The Context Memory system organizes conversation history into a tree structure. Upper nodes store concise summaries, while the leaf nodes retain detailed, verbatim information. When a query is made, the system retrieves only the relevant sections of the tree, ensuring efficiency and precision. Pricing reflects this streamlined approach:
- $3.75 per 1 million tokens for non-cached input
- $1.00 per 1 million tokens for cached input
- $1.25 per 1 million tokens for output
These costs are in addition to standard model inference fees.
Scalability
NanoGPT supports sessions of virtually unlimited length. Users can set data retention periods ranging from 1 to 365 days by adding the :memory-<days> suffix, with 30 days as the default. The system retains over 500,000 tokens of history but only delivers the most relevant 8,000–20,000 tokens during each inference. This scalability is achieved through server-side retention and hierarchical compression, avoiding the strain on the model’s self-attention mechanism.
Training Requirements
Unlike methods such as RoPE Extrapolation or Position Interpolation, which require changes to a model’s positional encoding, Context Memory operates entirely during inference. No retraining of the base model is needed. Activating this feature is as simple as appending :memory to the model name or using a specific API header. Thanks to a partnership with Polychat, NanoGPT integrates seamlessly with various models without requiring any modifications.
Use Cases
NanoGPT's Context Memory is particularly effective in scenarios where retaining extensive historical context is essential:
- Software development: Maintains project-wide context during long coding sessions, summarizing overarching details while retrieving precise code snippets as needed.
- Storytelling and role-playing: Manages large narrative histories, ensuring continuity without exceeding token limits.
- Research discussions: Preserves episodic details during extended problem-solving or brainstorming sessions.
These capabilities make NanoGPT a powerful tool for tasks that demand both scalability and precision in handling vast amounts of contextual information.
Advantages and Disadvantages
This section breaks down the key strengths and weaknesses of each technique, summarizing their trade-offs in areas like efficiency, scalability, training needs, and practical application.
RoPE Extrapolation and Position Interpolation stand out for their minimal fine-tuning requirements and low computational demands, making it possible to achieve 2–8× context extensions. However, RoPE Extrapolation can falter dramatically when rotation angles at unseen positions stray outside the training distribution, disrupting attention scores. Position Interpolation addresses this by rescaling position indices to stay within the original training range, offering far more stable results.
Sparse Attention methods are highly efficient, cutting inference costs by 50% and scaling up to 16,000–64,000 tokens with computational complexities of O(k) or O(N log N) - a significant improvement over the typical quadratic O(N²). The downside is a possible loss of global context since these methods don't attend to every token.
LongLLMLingua delivers impressive compression ratios of up to 20×, reducing costs significantly. However, this compression can sometimes sacrifice finer details.
Cross-Attention Hybrids (CEPE) excel in memory efficiency, using only one-sixth of the memory required by standard transformers and scaling effectively to 128,000-token contexts. That said, they require a specialized encoder, adding complexity to the training process.
NanoGPT's Context Memory is purely inference-based, requiring no model retraining. This makes it a highly efficient option for managing extended context lengths.
"Effective context length sits at roughly 50-65% of the marketed capacity for most models." - Let's Data Science
The table below captures the advantages and disadvantages of each technique, comparing them across key dimensions:
| Technique | Training Requirement | Computational Overhead | Memory Efficiency | Best Use Case |
|---|---|---|---|---|
| RoPE Extrapolation | Low (minimal fine-tuning) | Low | Baseline | Quick extensions (may fail at extremes) |
| Position Interpolation | Low (minimal fine-tuning) | Low | Baseline | Stable 2–8× extensions |
| LongLLMLingua | Low (inference-side) | Low | High (up to 20× compression) | Cost optimization |
| Sparse Attention | Medium | Low (O(k) or O(N log N)) | High | Long document QA |
| CEPE Hybrids | High (specialized encoder) | Medium | Very High (1/6 memory usage) | Enterprise documents |
| NanoGPT Context Memory | None (inference-only) | Low | Very High | Extended session lengths |
It's worth noting that many of these techniques exhibit a U-shaped attention curve, where performance tends to dip when crucial content appears in the middle of a context.
Conclusion
Choosing the right context expansion method depends on your specific deployment needs. For inference-heavy tasks, Sparse Attention techniques like DeepSeek DSA stand out. They reduce complexity to O(k) per step, cutting API costs by around 50% compared to dense models. Pairing this with prompt caching can further lower expenses by as much as 90% for repeated content.
Newer approaches, like Ring Attention and Test-Time Training (TTT-E2E), are pushing boundaries even further. Ring Attention supports token windows exceeding 10 million by distributing memory across GPU clusters with linear scaling, making it ideal for training scenarios. On the other hand, TTT-E2E, introduced in 2026, achieves constant inference latency regardless of input length, boasting a 35× speedup at 2 million tokens.
"The research community might finally arrive at a basic solution to long context in 2026." - Zylos Research
Position Interpolation offers stable expansions of 2–8× with minimal fine-tuning, making it a low-overhead option. Meanwhile, Multi-head Latent Attention (MLA) dramatically reduces KV cache size by 93.3% without compromising performance. Another noteworthy innovation, iRoPE - featured in Llama 4 - strikes a balance between local precision and global recall by using a 3:1 ratio of positional to position-agnostic layers. These advancements highlight a shift toward smarter and more efficient context handling.
It's important to note that the effective context length is often only 50–65% of the advertised capacity. This has led the industry to prioritize strategies like better data compression, hybrid memory setups, and smarter utilization techniques. For most practical applications, combining multiple methods - such as 4-bit KV cache quantization to cut memory use by 75% or integrated systems that route simple queries to RAG while assigning complex tasks to long-context models - provides the best mix of cost-efficiency, performance, and reliability.
FAQs
Which technique should I use for my long-context use case?
For scenarios involving extended context, a mix of techniques like prompt caching, compression, and retrieval-augmented methods works best. Methods such as chunking, summarizing, and using memory systems help manage large context windows more effectively. Tools like semantic compression and retrieval-augmented generation (RAG) stand out for their ability to conserve resources while keeping accuracy intact. These approaches are perfect for processing lengthy documents or conversations without hitting size limits or driving up costs.
How do I estimate the true effective context length for my model?
To gauge your model's effective context length, don't just rely on the advertised maximum window size. Instead, compare it to how the model actually performs. Many models tend to deliver optimal results only within 50-65% of their claimed capacity, with reasoning and accuracy dropping off as you approach the upper limits.
The best way to pinpoint this is through testing. Evaluate the model's performance across different window sizes and track where accuracy starts to decline. This hands-on approach provides a clearer picture of the model's practical limits, which often differ from the marketed specifications.
Can I combine compression, sparse attention, and caching for better results?
Expanding the context window in large language models (LLMs) becomes more efficient when combining compression, sparse attention, and caching techniques. Together, these methods tackle the challenges of processing longer sequences without sacrificing performance.
- Sparse attention patterns reduce computational load by focusing only on the most relevant parts of the input.
- Context compression methods, such as token pruning, condense information to fit within the model's limits while preserving meaning.
- Caching stores previously processed information, allowing the model to reuse it instead of recalculating, which saves both time and resources.
Recent research highlights the effectiveness of hybrid approaches that integrate these strategies, showing promising results in managing extended contexts while maintaining both efficiency and scalability.