Cross-Platform API Integration Strategies
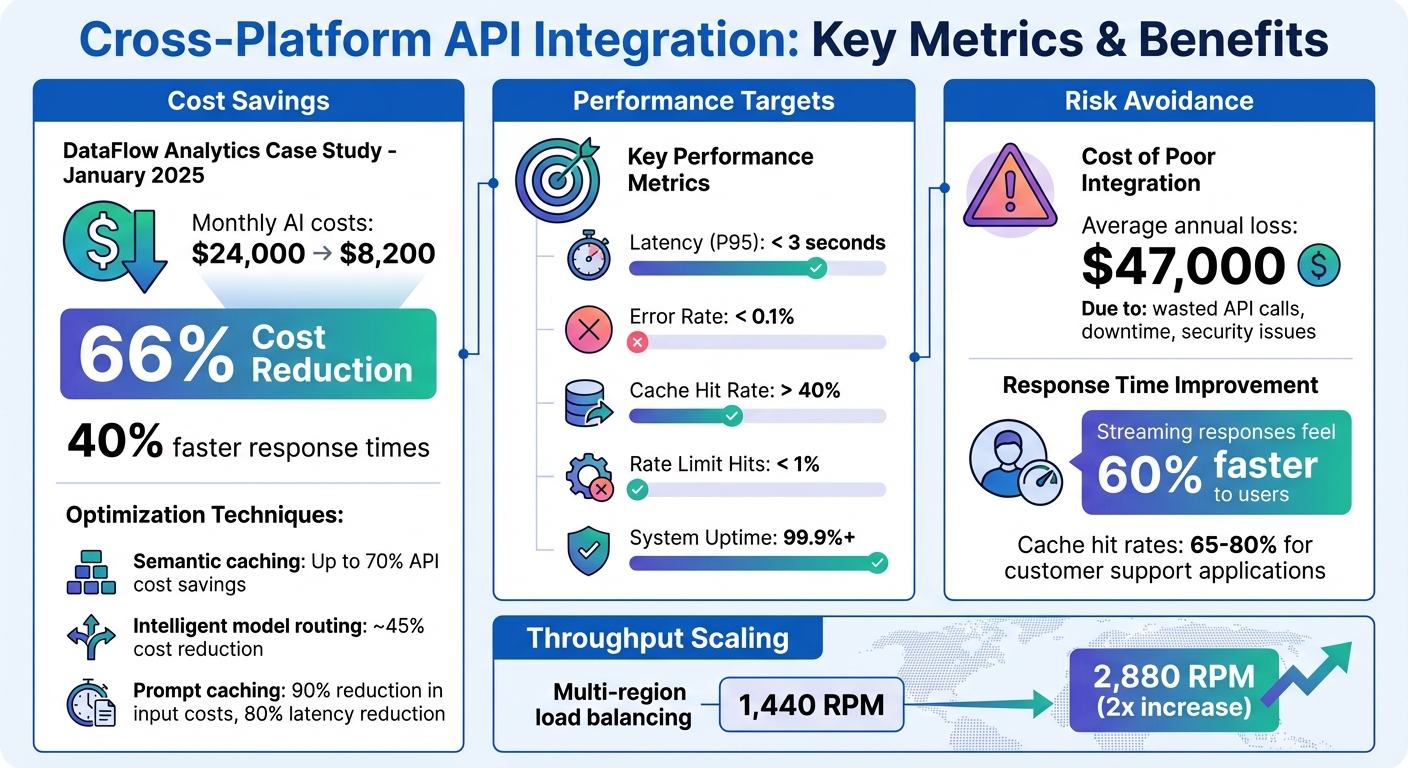
Cross-platform API integration makes it possible for tools like ChatGPT or Gemini to work seamlessly across devices and systems - whether it's a web app, mobile app, or backend software. This ensures smooth data exchange, consistent functionality, and cost savings. For example, DataFlow Analytics reduced their monthly AI costs by 66% in January 2025 through practices like semantic caching and intelligent model routing.
Here’s what you need to know:
- Efficiency: Proper API setups cut costs and improve response times. Semantic caching alone can save up to 70% in API costs.
- Standardization: Use frameworks like OpenAPI and stick to predictable endpoints (
/v1/chat/completions) to simplify integrations. - Security: Protect API keys, validate inputs, and comply with data privacy laws (e.g., GDPR, CCPA).
- Performance: Manage rate limits with queuing libraries, optimize caching, and monitor metrics like latency and error rates.
Cross-Platform API Integration: Cost Savings and Performance Metrics
What It Takes to Build API Integrations
sbb-itb-903b5f2
API Standardization and Compatibility Principles
When it comes to building cross-platform text generation APIs, standardization and thoughtful design are the cornerstones of success. Without these, you risk running into compatibility issues, wasted development time, and expensive integration failures. By following established industry patterns, you can avoid these headaches. One of the most important steps? Establishing clear and thorough documentation standards.
Understanding API Documentation Standards
Good documentation is essential for smooth API integration. The OpenAPI Specification (formerly known as Swagger) has become the go-to framework for structuring APIs. It ensures that endpoints are easy to discover, predictable, and compatible across various programming languages like Python, JavaScript, and C#. Many providers now offer OpenAI-compatible endpoints, such as /v1/chat/completions, allowing developers to switch between services with minimal effort. This approach not only accelerates integration but also minimizes vendor lock-in.
For text generation APIs, standardized message roles - such as developer (a replacement for the older system role), user, and assistant - are crucial to maintaining clear communication across different model families. Additionally, your API should handle errors consistently: use 429 for rate limits, 500 for server errors, and 400 for malformed requests. To manage retries effectively, implement exponential backoff with jitter. This prevents the "thundering herd" issue, where multiple clients retry simultaneously after a failure, overwhelming the system.
"If data and applications are the fuel that trains and powers AI, APIs are the wiring that connects those elements to make innovative AI solutions possible." - Brian Silverman, Sales and Marketing Leader
Designing for Platform-Agnostic Integration
Once your documentation is solid, the next step is designing an API that works seamlessly across platforms. A platform-agnostic design ensures consistent functionality on iOS, Android, Windows, Linux, and web browsers. Focus on resource-oriented design, where your API revolves around resources like conversations or completions, rather than specific actions. Standard HTTP methods - GET, LIST, CREATE, UPDATE, DELETE - make the API intuitive for developers regardless of their environment.
For security and reliability, avoid making direct API calls from frontend code. Instead, use a backend proxy to handle authentication, validate inputs, enforce rate limits, and protect API keys from exposure. This approach ensures consistency across mobile apps, desktop software, and web interfaces.
When it comes to data formats, JSON is a universal choice for most scenarios, as it works across all platforms without requiring special libraries. For high-performance, real-time processing, Protocol Buffers with gRPC can be a better fit. JSON is simple and widely supported, while gRPC shines in scenarios requiring low latency and high throughput.
In January 2025, DataFlow Analytics showcased the benefits of well-designed APIs. Led by VP of Engineering Marcus Thompson, the team implemented semantic caching, intelligent model routing, and standardized error handling. The results were impressive: monthly OpenAI costs dropped from $24,000 to $8,200 - a 66% reduction - while response times improved by 40%.
Managing Dependencies and SDKs
Dependencies play a critical role in maintaining cross-platform compatibility. Use semantic versioning (SemVer) with the MAJOR.MINOR.PATCH format to clearly communicate changes. Major updates indicate breaking changes, while minor and patch updates ensure backward compatibility. To avoid disrupting clients, support at least two API versions simultaneously, giving users time to migrate.
Hardcoding API keys is a common pitfall. Instead, rely on environment variables or secret management tools like AWS Secrets Manager or HashiCorp Vault. Implement automated key rotation every 90 days with a dual-key strategy to ensure continuity during transitions.
Circuit breakers are another essential tool for managing dependencies. When a service becomes unresponsive, circuit breakers temporarily block requests, preventing cascading failures. This gives failing services time to recover while safeguarding the rest of your system.
Finally, pre-count tokens before making API calls to avoid exceeding model limits. For example, if your model has a 128,000-token limit, reserve at least 8,000 tokens for the response to prevent truncation errors. These small precautions can save you from major headaches down the line.
Step-by-Step Guide to Cross-Platform Integration
Now that you’re familiar with the basics of API standardization, it’s time to roll up your sleeves and put those principles into action. By following a structured approach, you can set up your development environment, implement API calls, and thoroughly test your integrations. This ensures your text generation APIs work smoothly across platforms like iOS, Android, Windows, Linux, and web browsers - without needing to rewrite code for each one.
Preparing Your Development Environment
Start by securing your API keys. Instead of hardcoding them, use environment variables. For local projects, create a .env file (and don’t forget to include it in your .gitignore file). For production environments, rely on tools like AWS Secrets Manager or Google Secret Manager to keep your keys safe.
To further protect your keys and streamline operations, set up a backend proxy. This approach prevents direct API calls from your frontend, enforces usage limits, and allows you to validate inputs before they reach the API. Your frontend should only communicate with your backend, which handles all external API interactions.
Choose tools that align with your project needs. Official SDKs, like nanogptjs, offer built-in error handling, while standard HTTP clients such as Python’s requests or cURL provide greater flexibility. Many providers, including NanoGPT, support OpenAI-compatible endpoints like /v1/chat/completions, making it easy to switch between services by simply updating the base URL and API key.
Be prepared for rate limits. Use queuing libraries like p-queue or bottleneck to manage requests efficiently, or consider message brokers like Redis to handle provider-enforced limits. Set explicit timeouts - typically between 30 and 60 seconds - to avoid requests hanging during latency spikes. These steps ensure your API calls are consistent and reliable across all platforms.
Implementing API Calls Across Platforms
Consistency is key when implementing API calls. Design your API around resources like conversations or completions rather than platform-specific actions. Stick to standard HTTP methods (GET, POST, PUT, DELETE) to keep your API straightforward and intuitive, no matter the platform.
When it comes to data formats, JSON is a universal choice, but Protocol Buffers with gRPC are better suited for scenarios requiring low latency and high throughput.
For smarter API usage, implement dynamic routing. Direct simple tasks to cost-efficient models like GPT-3.5/Haiku, while reserving high-performance models like GPT-4/Opus for more complex tasks. This approach can slash costs by about 45%. Always count tokens before making API calls to ensure your prompt fits the model’s context window.
Reduce redundant calls with semantic caching. Even if users ask the same question in different ways, vector similarity matching can identify cached responses, potentially cutting API costs by 50–70%.
Testing and Debugging Integrations
Thorough testing is crucial to avoid costly mistakes that could disrupt your integrations. Poorly executed API setups have been known to cost businesses an average of $47,000 annually due to wasted calls, downtime, and security issues.
If you encounter rate limits (429 errors) or server issues (500, 503 errors), use exponential backoff with three retries and random delays. For persistent failures, apply the circuit breaker pattern, which temporarily halts requests - for instance, pausing for 60 seconds if the error rate exceeds 50% in one minute.
Track every API call with detailed logging. Include unique request IDs, timestamps, user identifiers, model versions, token counts, latency, and error codes. Set up alerts for error rates that exceed 5% over five minutes or for latency spikes beyond 10 seconds (P95). This monitoring helps you catch and resolve issues before they affect users.
Before making API calls, validate inputs. Sanitize prompts and mask any personally identifiable information (PII) to ensure compliance. Double-check that your requests meet the API’s requirements. In cases where the API is unavailable, provide fallback options like cached responses or static messages to keep your application functional during outages.
Performance Optimization for Text Generation APIs
Ensuring your text generation APIs run smoothly and cost-effectively means focusing on performance. By leveraging caching, managing request loads efficiently, and keeping a close eye on API performance, you can deliver consistent results across all platforms.
Caching and Reducing Latency
Caching is a game-changer when it comes to cutting down on costs and latency. For instance, prompt caching can slash latency by 80% and reduce input costs by a whopping 90%. Large Language Model (LLM) providers often cache prompt prefixes of up to 1,024 tokens by routing requests to recently active servers. To take advantage of this, structure your prompts with static content first and dynamic content later.
For even better results, consider semantic caching with vector embeddings. Instead of relying on exact matches, this method identifies prompts with high similarity (95% or more) and retrieves cached responses. This approach works especially well for applications like customer support, where repetitive queries often lead to cache hit rates of 65%–80%. Use tools like Redis to store these responses, setting a Time-to-Live (TTL) between 1 and 24 hours, depending on how frequently your data changes.
Keep an eye on cache performance by tracking metrics like hit rates, latency improvements, and the percentage of tokens cached. While trimming prompt length might improve latency by just 1–5%, caching offers far greater efficiency.
Once caching is optimized, the next step is managing high request volumes without bottlenecks.
Load Balancing and Request Management
Handling large volumes of API requests requires smart load management to keep your application responsive. A GenAI gateway can act as middleware, dynamically balancing traffic across backend resources. Since AI providers limit requests regionally, spreading load across multiple regions can double throughput - for instance, increasing from 1,440 requests per minute (RPM) to 2,880 RPM.
To handle traffic spikes, route requests first to Provisioned Throughput Units and then overflow to Pay-As-You-Go endpoints. This strategy prevents throttling while keeping costs in check. For example, you can assign simpler tasks to cost-efficient models like GPT-3.5 Turbo and reserve advanced models like GPT-4 for more complex tasks, cutting API costs by around 45%.
Use token bucket algorithms to manage request loads across platforms and reject excess requests before they hit provider-side rate limits. For tasks that don't need real-time processing, offload them to asynchronous queues using tools like Redis or RabbitMQ. When servers start showing signs of strain, such as frequent 429 errors, circuit breakers can temporarily pause requests to prevent further issues.
With these strategies in place, real-time monitoring becomes essential to maintain efficiency.
Monitoring API Performance
Real-time monitoring is key to identifying and fixing issues before they disrupt your users. Track critical metrics such as Request ID, User ID, Model ID, token counts, latency, and cost. Set up alerts at different levels: critical alerts for error rates exceeding 5% or P95 latency over 10 seconds, and warning alerts for daily spend surpassing 120% of your budget.
| Metric | Description | Target |
|---|---|---|
| Latency (P95) | Time for 95% of requests to complete | < 3 seconds |
| Error Rate | Percentage of failed requests | < 0.1% |
| Cache Hit Rate | Percentage of requests served from cache | > 40% |
| Rate Limit Hits | Frequency of 429 errors | < 1% |
Use tools like Amazon CloudWatch or Azure Monitor to gain real-time insights into your API's health. For pinpointing bottlenecks, distributed tracing tools like AWS X-Ray can track a single transaction from the initial request to the final LLM response. In high-traffic environments, push custom events to systems like Kafka for real-time analysis.
Standardize your logging, metrics, and tracing with OpenTelemetry to maintain consistent, actionable performance data across cloud providers and monitoring tools. This ensures you can keep tabs on your API's performance no matter what platforms you’re using.
Security and Privacy Considerations
When integrating APIs, ensuring user data security is absolutely critical. Poorly managed integrations can lead to costly consequences, with businesses losing an average of $47,000 annually due to security incidents, downtime, and inefficient API calls. The good news? Most vulnerabilities can be avoided with the right precautions.
Implementing Secure Authentication Protocols
Always route API calls through your backend to keep API keys hidden from prying eyes. If API keys are exposed in a developer console, you're leaving your system vulnerable. OpenAI emphasizes this in their terms:
"Your API key is intended to be used by you. The sharing of API keys is against the Terms of Use".
Store your API keys securely - use environment variables or services like AWS Secrets Manager or Google Secret Manager. Never hardcode them in your source code. To further protect your system, rotate API keys every 90 days. This can be done without downtime by creating a new key, setting it as a fallback, promoting it to primary, and then revoking the old one. Add restrictions to your keys, such as limiting them by IP address or specific API services, to reduce exposure.
For applications handling user-specific data or actions, OAuth 2.1 with PKCE is your go-to for preventing authorization code interception. On the backend, ensure your servers validate every request, including signature checks, audience matching, and expiration verification. Assign unique API keys to each team member to maintain a clear audit trail.
Beyond authentication, it's essential to ensure your data handling complies with privacy laws.
Ensuring Data Privacy Compliance
To comply with regulations like GDPR and CCPA, you must carefully manage where and how user data is processed. For GDPR, this might mean keeping EU users' data on EU-based servers. It's important to note that standard AI APIs from providers like OpenAI, Anthropic, and Google are not HIPAA or PCI compliant by default. If you're dealing with regulated data, you'll need to sign a Business Associate Agreement (BAA) with your provider and use compliant endpoints.
Sensitive data like Personally Identifiable Information (PII) should be scanned, masked, and redacted from prompts and logs to meet GDPR, CCPA, and similar regulations. Some API providers offer enterprise-level "zero data retention" policies to ensure user data isn't stored beyond the immediate request. Check whether your provider uses user prompts for model training - while platforms like ChatGPT, Mistral, and Grok allow opt-outs, others, such as Gemini and Meta AI, may not.
A platform like NanoGPT takes a different route by storing data locally on your device. This eliminates many compliance concerns since your data never leaves your control. For heightened privacy needs, Trusted Execution Environments (TEE) can provide attestation reports and signatures, proving that data was securely handled.
Once privacy measures are in place, focus on securing your application against common vulnerabilities.
Preventing Common Security Vulnerabilities
Exposed credentials and unsanitized inputs are among the most frequent security issues. To mitigate these risks, sanitize all inputs and outputs. For example, use HttpOnly flags on cookies and encode outputs to block XSS attacks, prevent prompt injections, and avoid exposing API keys in URLs. Prompt injection attacks can modify how language models behave, potentially allowing unauthorized actions. Always use HTTP headers like Authorization: Bearer or x-goog-api-key instead of embedding API keys in URLs.
To guard against DDoS attacks and manage costs, enforce per-user rate limiting and set up real-time alerts for unusual traffic patterns. Follow the principle of least privilege by only requesting the minimum scopes and permissions your integration needs. When dealing with server errors, respond appropriately. For instance:
- A 401 error means keys may have expired or are invalid - check and refresh them as needed.
- A 403 error suggests token scopes or audience claims need verification.
- A 429 error indicates a rate limit - use exponential backoff and queue requests.
- A 503 error signals service unavailability - implement a circuit breaker pattern to handle it gracefully.
| Error Code | Meaning | Recommended Action |
|---|---|---|
| 401 | Unauthorized | Check for expired/invalid keys |
| 403 | Forbidden | Verify token scopes and audience claims |
| 429 | Rate Limit | Use exponential backoff and request queuing |
| 503 | Service Unavailable | Implement circuit breaker pattern |
Conclusion and Key Takeaways
Recap of Main Integration Strategies
Cross-platform API integration relies on three core principles: standardization, performance tuning, and security. By using OpenAI-compatible endpoints, you can seamlessly switch between providers with minimal coding adjustments, saving time and effort. Routing API calls through a backend proxy not only secures credentials but also enforces rate limits effectively. Incorporating exponential backoff with jitter for temporary errors and circuit breakers for ongoing outages ensures your application remains stable and responsive. Plus, aligning specific tasks with the most suitable model can cut costs by 30–60% without compromising on quality.
These strategies provide a clear path to improved efficiency and measurable gains in both cost and system performance.
Benefits of Cross-Platform Solutions
When done right, cross-platform solutions offer substantial advantages. Standardization, combined with optimized performance and robust security, can lead to dramatic savings and faster response times. Companies adopting these practices have reported reducing costs by up to 66% while achieving 40% faster response times. Additionally, leveraging streaming responses can make interactions feel up to 60% faster, even if the total processing time remains unchanged. Following best practices not only ensures smoother operations but also helps achieve 99.9%+ uptime, avoiding potential losses - estimated at $47,000 annually - from poorly designed integrations.
Next Steps for Developers
With these insights in mind, here’s how you can get started. Secure your API keys using environment variables or a secrets manager, route API calls through a backend proxy, and implement response caching to cut down on redundant requests. For developers seeking a flexible, privacy-conscious solution, NanoGPT is worth exploring. It supports major AI models like ChatGPT, Deepseek, Gemini, Flux Pro, Dall-E, and Stable Diffusion, offering a pay-as-you-go pricing model starting at just $1.00 (or $0.10 with cryptocurrency). NanoGPT stores all data locally on your device, giving you complete control over your information while allowing seamless integration with multiple providers from one platform.
To get started with NanoGPT, create your API key on their API page, install the nanogptjs library for quick setup, and test features like real-time search by appending model suffixes (e.g., :online). By taking these steps, you’ll be well-equipped to build secure, efficient, and scalable integrations.
FAQs
How does semantic caching help reduce API costs?
Semantic caching operates by saving embeddings from earlier prompts and reusing them for queries that are alike. This approach minimizes unnecessary API calls to large language models (LLMs), which helps reduce token usage and, in turn, lowers costs.
By skipping the repeated processing of similar inputs, semantic caching can lead to cost savings of 70–90%. It's a smart way to optimize API expenses without sacrificing performance.
How can I protect my API keys when integrating NanoGPT?
Keeping your API keys safe is essential to avoid unauthorized access and unexpected costs. To protect them, don’t hard-code keys into your source code or include them in client-side applications like browsers or mobile apps. Instead, store them securely in environment variables or configuration files that are kept out of version control.
Make sure your keys never end up in repositories by adding them to your .gitignore file. When possible, use secret-management tools to handle them securely. Assign unique keys to each team member or service, and apply specific restrictions, such as limiting access to certain IP addresses or NanoGPT endpoints. Always use encrypted connections (like HTTPS) to transmit keys, and rotate them regularly. If a key is no longer needed or might have been exposed, revoke it immediately.
Keep an eye on your usage and set alerts to catch any unusual activity early. Taking these precautions ensures your NanoGPT API integrations stay secure and run smoothly.
Why is standardization crucial for seamless cross-platform API integration?
Standardization plays a key role in ensuring APIs function smoothly across different platforms. By adhering to common protocols and formats, developers can write code once and reuse it across various environments. This approach minimizes issues like mismatched data formats or authentication errors. Beyond just convenience, this consistency can save valuable time and help avoid costly problems, such as downtime or security risks, which could cost organizations as much as $47,000 annually.
Take the NanoGPT API as an example. Its standardized design includes consistent endpoint naming, uniform request structures, and clear authentication methods. This setup allows developers to seamlessly transition between platforms - whether they're working with JavaScript, Python, or serverless functions - without the need to rewrite code. The result? Compatibility and top-notch performance. Standardization also streamlines tasks like maintenance, scaling, and monitoring, enabling teams to concentrate on building high-quality AI features while keeping expenses in check.