Custom RISC-V Instructions for LLMs
RISC-V processors are reshaping how large language models (LLMs) operate by allowing developers to design custom instructions tailored for AI tasks. Unlike x86 and ARM, which rely on fixed or licensed architectures, RISC-V is open-source and modular, enabling hardware engineers to create AI-specific optimizations.
Key takeaways:
- Energy Efficiency: Custom RISC-V instructions, like vector dot products and zero-overhead loops, have reduced energy consumption by up to 49.1% compared to ARM Cortex-A9.
- Performance Boosts: The Sophon SG2042, a 64-core RISC-V CPU, achieved a 3.0× speedup in token generation for LLMs like Distill Llama 8B.
- Customizability: RISC-V’s open design supports specialized extensions, such as VEXP for Softmax, which improved performance by 162.7× with minimal hardware cost.
In contrast:
- x86: Offers high throughput but lacks customizability and consumes more power.
- ARM: Balances efficiency with some AI optimizations but is limited by licensing restrictions.
RISC-V’s flexibility makes it ideal for AI workloads requiring tailored hardware solutions, while x86 and ARM still dominate general-purpose and mobile computing.
RISC-V vs ARM vs x86 Architecture Comparison for LLM Workloads
1. RISC-V Custom Instructions

Instruction Flexibility
RISC-V's open architecture offers hardware engineers a unique opportunity to add custom opcodes, tailoring the processor to tackle specific computational challenges in large language models (LLMs). Unlike x86 or ARM, which rely on fixed instruction sets, RISC-V includes reserved slots - CUSTOM 0, 1, and 2 - where developers can insert specialized operations without disrupting standard compatibility.
Take the fusedmac instruction as an example. This operation combines two addi, one mul, and one add into a single cycle. Why does this matter? Because these patterns account for nearly 10% of AI-related code. In August 2025, researchers from University College Dublin introduced the MARVEL framework, which generates model-specific RISC-V extensions. When tested on an AMD Zynq UltraScale+ ZCU104 FPGA, MARVEL delivered a 2× speedup in inference and halved energy consumption for models like MobileNetV2 and ResNet50.
These examples highlight how custom opcodes can unlock new levels of efficiency in LLM kernel operations.
LLM Kernel Optimization
Custom instructions can directly enhance the performance of key computational tasks. For LLMs, vector dot products and matrix–vector multiplication (GEMV) are the most demanding kernels, and RISC-V's flexibility allows engineers to design hardware tailored to these operations.
One standout feature is zero-overhead loops (ZOL), which eliminate unnecessary cycles caused by branch instructions (e.g., blt) and loop counters. These inefficiencies add up - ResNet50 alone executes branch and loop counter operations nearly 1.89 billion times. The zol instruction streamlines these processes, saving millions of cycles.
In April 2025, researchers Run Wang and Angelo Garofalo introduced VEXP, a custom RISC-V extension designed for Bfloat16 exponentiation, particularly for Softmax computations. When integrated into a compute cluster, VEXP reduced latency by an astounding 162.7× and cut energy consumption by 74.3× compared to standard RISC-V implementations. For the FlashAttention-2 kernel in GPT-2 configurations, VEXP achieved an 8.2× performance boost with just a 1% increase in area overhead.
Performance Benchmarks
The impact of these optimizations is evident in performance benchmarks. In September 2024, researchers Xu-Hao Chen and colleagues introduced the Xiangshan Nanhu-vdot processor, featuring specialized vector dot product instructions. This processor improved GPT-2 inference speeds by 30% and delivered over 4× the speed of scalar methods in raw vector dot product calculations, all while maintaining minimal power consumption.
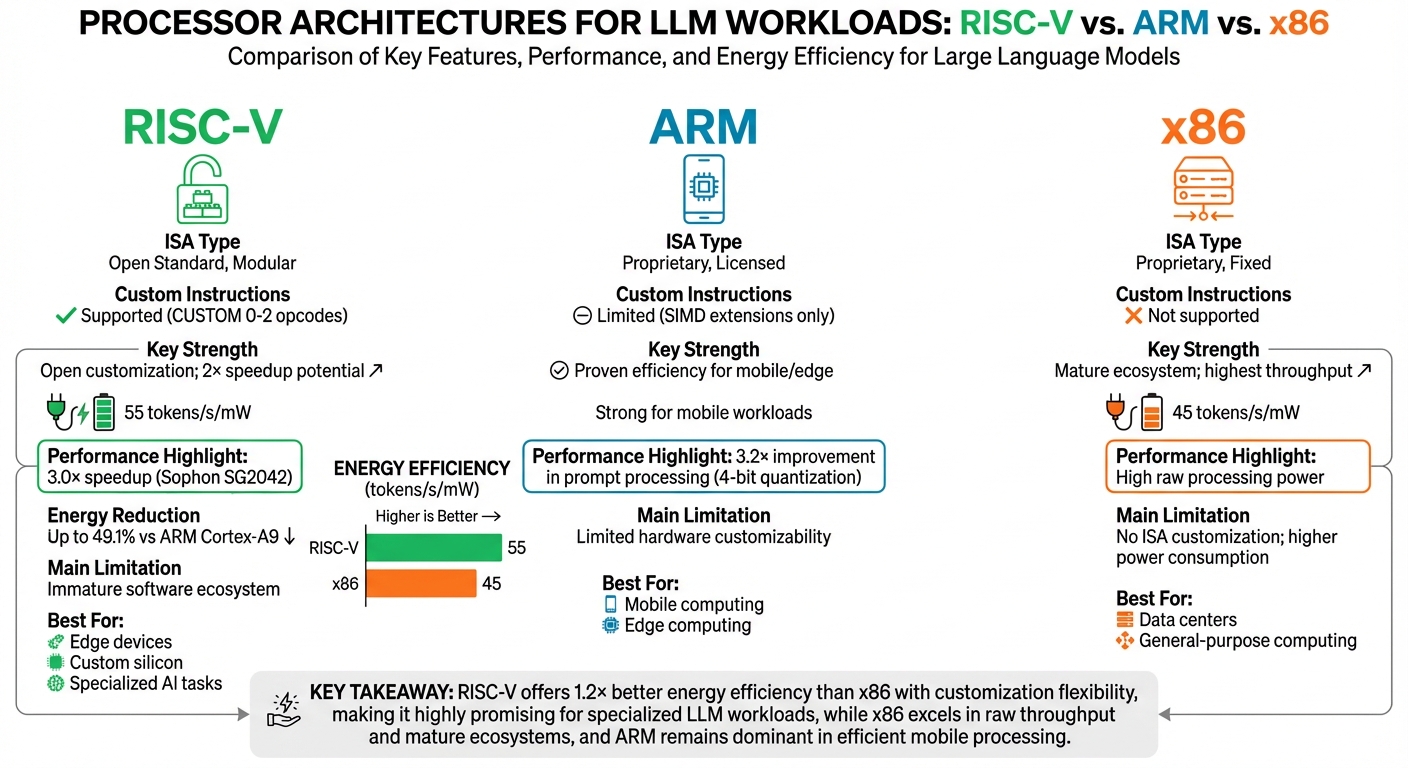
More recently, in March 2025, a collaboration between Politecnico di Torino and ETH Zurich optimized the llama.cpp framework for the Sophon SG2042, a 64-core RISC-V CPU. By fine-tuning custom GEMV kernels and optimizing NUMA policies, the team achieved 4.32 tokens per second for DeepSeek R1 Distill Llama 8B - 2.9× faster than baseline implementations. For Llama 7B, they reached 13.07 tokens per second during prompt processing, a 5.5× improvement. The SG2042 also demonstrated exceptional energy efficiency, processing 55 tokens per second per milliwatt - outperforming the x86-based AMD EPYC 7742, which managed 45 tokens per second per milliwatt.
| Model | Platform | Performance (Tokens/s) | Speedup over Baseline |
|---|---|---|---|
| DeepSeek R1 Distill Llama 8B | Sophon SG2042 (RISC‑V) | 4.32 | 2.9× |
| Llama 7B | Sophon SG2042 (RISC‑V) | 13.07 | 5.5× |
| DeepSeek R1 Distill QWEN 14B | Sophon SG2042 (RISC‑V) | 2.29 | 3.0× |
2. x86 Architecture
Instruction Flexibility
The x86 architecture operates on a fixed, vendor-controlled instruction set architecture (ISA). Intel and AMD hold the reins here, meaning developers must work within proprietary extensions like AVX-512 or Intel’s Advanced Matrix Extensions (AMX). This setup doesn’t allow for adding custom opcodes tailored to specific workloads, such as those required for large language models (LLMs).
Because of this rigidity, optimization teams often have to rely on handwritten assembly kernels for libraries like OpenBLAS or Intel MKL. Each new CPU generation - whether it’s Intel’s Skylake or AMD’s Zen - demands separate, manually tuned kernels to squeeze out the best performance. Ludovic Henry, Team Lead at Rivos, highlights the challenge:
The compiler is a generic compiler. It's not a matrix multiply optimizer. It's not going to have to know all the tricks you could do to optimize matrix multiply very specifically.
This lack of flexibility often leads to bottlenecks at the kernel level.
LLM Kernel Optimization
These fixed constraints significantly affect kernel optimization efforts. Matrix multiplication, a critical operation during LLM inference, dominates the workload. On x86, optimizing these kernels means working around the limitations of the fixed ISA and dealing with compiler shortcomings in areas like loop unrolling and auto-vectorization.
Memory access patterns add another layer of complexity. For example, matrix transpose operations, which are common in attention mechanisms, often hit cache performance limits. While x86 processors rely on standard shuffle instructions, they lack the ability to implement specialized, lower-latency instructions for these operations.
Performance Benchmarks
When benchmarked, these constraints reveal that while x86 processors can achieve impressive teraflop speeds, they still fall short compared to specialized AI accelerators.
For instance, accuracy tests using the MLPerf OpenOrca dataset showed an x86-hosted NVIDIA 2080 Ti achieving ROUGE scores of 39.41 (ROUGE-1), 15.85 (ROUGE-2), and 27.98 (ROUGE-L) for TinyLlama-1.1b in FP32 format. These results were identical to those from a RISC-V SiFive X390 system running the same model. However, the key difference lies in energy efficiency and customization potential. Unlike x86’s fixed architecture, RISC-V allows for tailored optimizations that better suit specific workloads. This distinction becomes critical as data center power consumption is forecasted to rise, potentially accounting for 8% of total U.S. energy use by 2030, up from 3% in 2022, largely driven by traditional high-performance hardware.
| Feature | x86 Architecture | RISC-V Architecture |
|---|---|---|
| ISA Type | Proprietary, Fixed | Open Standard, Modular |
| Custom Instructions | Not supported | Supported via CUSTOM 0-2 opcodes |
| Optimization Method | Handwritten kernels for specific CPU generations | Co-design with custom opcodes |
| Loop Handling | Software-based branching | Zero-overhead hardware loops (zol) |
Boosting AI on Semidynamics RISC-V Cores with Custom Tensor Instr... Roger Espasa & José María Arnau
sbb-itb-903b5f2
3. ARM Architecture
ARM takes a mixed approach to instruction design, blending dedicated SIMD instructions with specific optimizations, which stands in contrast to the fixed structure of x86 and the open flexibility of RISC-V.
Instruction Flexibility
While RISC-V allows for open customization, ARM focuses on targeted custom instructions to handle workloads like large language models (LLMs). Processors such as the Cortex-M33, M55, and M85 come equipped with specialized instructions to enhance data processing for these applications. For instance, ARM's Advanced SIMD (Neon) instructions support operations like vdotq_laneq_s32, which performs integer dot products on 8-bit activations and weights. However, ARM CPUs lack native support for directly multiplying 4-bit and 8-bit values, requiring 4-bit weights to be manually converted into 8-bit integers before processing.
LLM Kernel Optimization
ARM fine-tunes its LLM kernels by employing SIMD-aware weight packing, which reorganizes weights to align with the vector compute order. This approach also integrates dequantization directly with matrix multiplication, minimizing runtime overhead. In December 2024, researchers from Arm Inc., including Dibakar Gope and David Mansell, introduced highly optimized GEMV and GEMM kernels that streamline weight reformatting to match vector instruction requirements. By eliminating the need for runtime permutations, these kernels fully utilize MAC units and avoid the latency associated with writing intermediate values back to DRAM. Instead, operand loading is shared across multiple output rows, improving efficiency. As Arm Inc. explains:
Facilitating the efficient execution of LLMs on commodity Arm CPUs will expand their reach to billions of compact devices such as smartphones and other small devices.
These optimizations are designed to deliver tangible improvements in performance.
Performance Benchmarks
ARM's 4-bit group-wise quantization kernels demonstrate impressive results, achieving a 3.2× improvement in prompt processing and a 2× speed-up in autoregressive decoding by maximizing vector instruction usage and minimizing memory bandwidth issues. In comparison, RISC-V's 64-core Sophon SG2042 achieved 1.2× better energy efficiency, delivering 55 tokens/s/mW versus 45 tokens/s/mW on a 64-core x86 AMD EPYC 7742. While ARM maintains a stronghold in mobile and edge devices, RISC-V's open customization capabilities make it a strong contender for specialized LLM tasks.
Advantages and Disadvantages
Each processor architecture brings its own strengths and trade-offs when it comes to optimizing large language model (LLM) performance. Let’s break down how RISC-V, ARM, and x86 stack up in terms of their capabilities and limitations.
RISC-V stands out for its open-source flexibility, which allows developers to design custom instructions specifically tailored to LLM kernels. For example, the MARVEL framework achieved a 2× speedup and cut energy consumption in half, albeit with a 28% area overhead. Similarly, the Xiangshan Nanhu-vdot processor demonstrated the power of this approach in September 2024, using custom vector dot product instructions to boost GPT-2 inference speeds by about 30% with minimal hardware changes.
On the other hand, ARM offers a middle ground with its proven energy efficiency in mobile and edge devices. Its proprietary SIMD extensions ensure solid performance, but the ability to customize hardware for specific AI tasks is limited by ARM’s licensing restrictions. This makes it less flexible than RISC-V but still highly effective for energy-efficient applications.
Now, let’s consider x86, which excels in delivering high throughput and benefits from a well-established, optimized software ecosystem. This architecture dominates traditional server computing and even powers the world’s fastest supercomputer, Frontier. However, its proprietary and fixed instruction set makes customization for specific workloads nearly impossible, and its power efficiency lags behind the other two architectures.
Ultimately, the best choice depends on the workload. RISC-V is ideal for specialized applications that require custom instructions and freedom from vendor lock-in. ARM strikes a solid balance between efficiency and performance for mobile and edge computing. Meanwhile, x86 remains the go-to for general-purpose tasks where software maturity and raw performance are critical.
| Architecture | Key Strength | Main Limitation | Energy Efficiency |
|---|---|---|---|
| RISC‑V | Open customization; 2× speedup potential | Immature software ecosystem | 55 tokens/s/mW |
| ARM | Proven efficiency for mobile/edge | Limited hardware customizability | Strong for mobile workloads |
| x86 | Mature ecosystem; highest throughput | No ISA customization; higher power consumption | 45 tokens/s/mW |
Conclusion
Selecting the right processor architecture for large language model (LLM) workloads comes down to matching your specific needs with the strengths of each platform. RISC-V stands out for its energy efficiency and ability to support custom instruction designs. For instance, the 64-core Sophon SG2042 achieved an impressive 55 tokens per second per milliwatt in March 2025, offering 1.2× better energy efficiency than AMD's EPYC 7742. This makes RISC-V a compelling option for edge devices, custom silicon, and applications where battery life is a top priority.
For scenarios like mobile and edge computing that require dependable performance without the complexity of custom hardware, ARM provides a well-established ecosystem. While ARM delivers consistent results, it lacks the deep customization potential that RISC-V offers. This distinction highlights the trade-off between ARM's reliability and RISC-V's flexibility.
On the other hand, x86 architectures excel in environments where raw processing power and a mature software ecosystem are essential. Data centers running varied workloads benefit greatly from x86's decades of optimization and software compatibility. While RISC-V's ecosystem is still developing, it's catching up quickly. In fact, Semico predicts that by 2027, 25 billion AI chips will incorporate RISC-V technology.
These trends point to a significant shift in the AI hardware landscape. The growing demand for energy-efficient solutions is reshaping how processors are designed. RISC-V's ability to integrate specialized instructions - like vector dot product units that improved GPT-2 inference by 30% with minimal additional power consumption - illustrates the movement toward architectures built for specific tasks rather than one-size-fits-all solutions.
FAQs
How do custom RISC-V instructions enhance energy efficiency for AI workloads?
Custom RISC-V instructions enhance energy efficiency in AI tasks by simplifying operations like matrix multiplication, multiply-accumulate (MAC), and softmax into specialized hardware commands. These commands execute in just one cycle, cutting down the need to fetch and decode multiple standard instructions. As a result, this approach trims power usage in control logic and speeds up execution, reducing the overall energy needed for each operation.
On top of that, energy-conscious custom instructions lead to more streamlined and efficient circuit designs. For instance, integrating MAC operations directly into the processor lowers switching activity and supports lower voltage operation without compromising performance. Positioning these extensions closer to memory also reduces expensive data transfers, further boosting energy savings. These improvements make RISC-V a strong contender for handling AI workloads in both edge devices and large-scale data centers.
How does customizing RISC-V instructions improve the performance of large language models (LLMs)?
Customizing RISC-V instructions - like incorporating vector and tensor extensions - can greatly boost the performance of large language models (LLMs). These tweaks allow for quicker inference times and reduced energy consumption when compared to more conventional architectures. For instance, a 64-core RISC-V processor has shown impressive speed gains, while other configurations have managed to cut power usage with only minor hardware adjustments.
This makes RISC-V an attractive option for running LLMs effectively, particularly in situations where both energy efficiency and high performance are essential.
What makes RISC-V more adaptable for AI workloads compared to x86 and ARM architectures?
RISC-V is notable for its open and extensible instruction set architecture (ISA), which gives designers the freedom to create custom instructions tailored to specific AI tasks. For example, developers can optimize large language models (LLMs) by incorporating vector-dot-product extensions. This approach offers a level of flexibility that outshines the fixed, proprietary instruction sets found in x86 and ARM architectures.
With these fine-tuned optimizations, RISC-V can deliver better performance and improved energy efficiency for AI workloads like LLMs. This makes it a strong contender for powering advanced AI applications.