Data Backup in Hybrid Disaster Recovery
Hybrid disaster recovery (DR) combines on-premises systems with private and public cloud environments to ensure data protection and quick recovery from failures. With 69% of businesses using hybrid cloud solutions, managing these environments can be complex. Alarming stats show 34% of DR plans fail during outages, and 29% of businesses never test their DR plans. This guide covers backup strategies, recovery configurations, and security practices to help you safeguard your data in hybrid systems.
Key Takeaways:
- Backup Strategies: Use the 3-2-1 rule (3 copies, 2 media types, 1 off-site) or the enhanced 3-2-1-1-0 approach for added security.
- Recovery Configurations: Options include active-passive setups (e.g., pilot light, warm standby) and active-active for minimal downtime.
- Security Measures: Protect backups with AES-256 encryption, multi-factor authentication (MFA), and immutable storage to counter ransomware attacks.
- Testing: Regularly test recovery plans to ensure they meet Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO).
Hybrid DR offers flexibility but requires proper planning, regular testing, and robust security to ensure data recovery and business continuity.
Standardizing Backups Across Hybrid Cloud | Webinar
sbb-itb-903b5f2
Data Backup Strategies for Hybrid Disaster Recovery
Hybrid disaster recovery (DR) relies on three core strategies to protect data and ensure recovery across diverse environments.
The 3-2-1 Backup Rule
The 3-2-1 rule has long been a trusted method for data protection. It’s simple: keep three copies of your data, store them on two different types of media, and ensure one copy is off-site. In a hybrid setup, this could mean:
- Copy 1: Production data on primary servers.
- Copy 2: A local backup on a NAS or external drive for quick recovery.
- Copy 3: A geographically distant cloud location like AWS, Azure, or Google Cloud.
But times have changed, and so have threats. The 3-2-1-1-0 approach adds an immutable copy and insists on zero errors through automated verification. This is critical since 93% of ransomware attacks now target backup systems. For a small-to-medium business managing 500 GB of data, initial costs for this strategy range from $1,300 to $3,300, with ongoing cloud storage fees between $55 and $110 per month.
"Your cloud provider is not responsible for backing up your data... If you are the victim of a ransomware attack, constant synchronization means both data sets will be encrypted", warns Veeam.
Avoid relying on cloud sync services like Dropbox or OneDrive as backups. These services mirror deletions or encryptions instantly, leaving you vulnerable to ransomware. Instead, use WORM (Write-Once-Read-Many) technologies like Amazon S3 Object Lock or Azure Immutable Blob Storage to safeguard your off-site backups. To ensure reliability, schedule quarterly restore tests to confirm your backups work when needed.
Continuous Data Replication and Snapshots
Beyond traditional backups, continuous data replication and snapshots offer near-instant recovery options.
- Continuous replication creates real-time copies of data across multiple locations.
- Snapshots capture the system’s state at specific moments, enabling point-in-time recovery.
Snapshots are especially useful after accidental deletions or data corruption, allowing you to restore to a clean state within minutes. To maximize their effectiveness:
- Store snapshots separately from production data.
- Use WORM features to ensure immutability.
- Automate integrity checks to catch corruption early.
| Feature | Continuous Replication | Snapshots |
|---|---|---|
| Primary Goal | High availability, minimal data loss | Point-in-time recovery |
| Recovery Speed | Near-instant (via failover) | Fast (granular or full restore) |
| Protection Type | Redundancy across locations | Protection from corruption/deletion |
| Storage Impact | High (duplicate active storage) | Moderate (incremental changes) |
Geo-Redundant Storage
Geo-redundancy protects your data from regional disasters like extreme weather, natural calamities, or power failures by storing backup copies in distant locations. This is especially important in hybrid systems where data spans multiple sites. By having backup infrastructure ready in a secondary location, geo-redundancy eliminates single points of failure and ensures quick recovery.
"Geo-redundancy facilitates a quick recovery by ensuring there are powered and networked servers on standby for the recovery software to work with", explains Johnny Yu, Enterprise IT storage analyst at IDC.
Managing costs is a common hurdle. To optimize expenses:
- Use lifecycle policies to move older backups to cheaper storage tiers.
- Automate failover processes to reduce manual intervention.
- Implement WORM with retention policies for ransomware protection and cost control.
Geo-redundancy, like other hybrid backup strategies, requires careful planning but ensures robust protection and recovery options when disaster strikes.
Disaster Recovery Configurations for Hybrid Systems
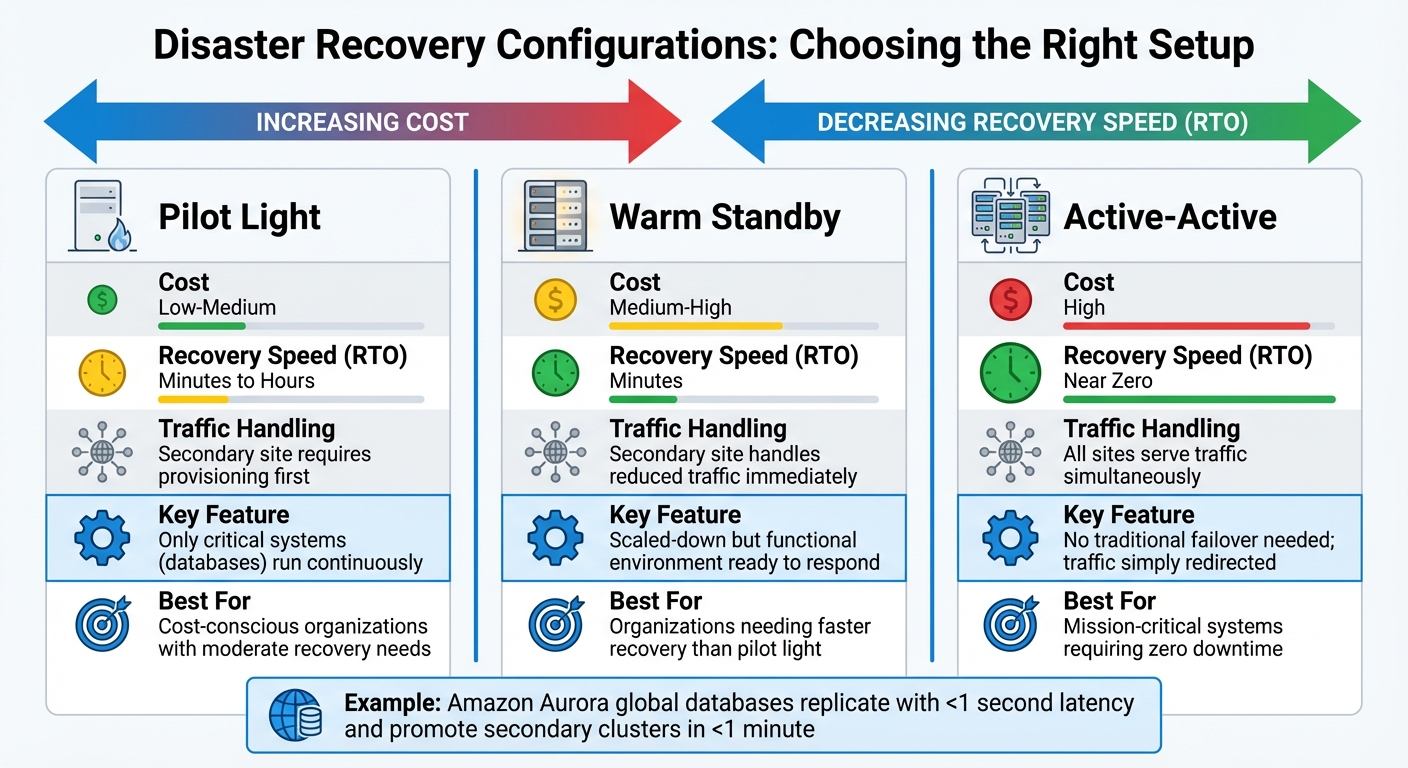
Disaster Recovery Configuration Comparison: Pilot Light vs Warm Standby vs Active-Active
Once you've secured your data with solid backup strategies, the next step is deciding on the right disaster recovery setup. This choice is crucial - it can heavily influence how quickly you recover and the costs involved. In hybrid systems, your disaster recovery architecture should align with your overall backup approach to ensure smooth business operations during disruptions. The main options are active-passive, active-active, and cloud-based disaster recovery (DR), each offering a different balance of speed, complexity, and expense.
Active-Passive Configuration
An active-passive setup relies on a primary environment to handle all traffic, while a secondary site remains on standby, ready to step in during an emergency. The secondary site doesn't process requests unless a failover is triggered. There are two common approaches:
- Pilot Light: This keeps only critical systems, such as databases, running continuously to ensure data replication. Application servers stay inactive until needed, which keeps costs low but results in longer recovery times.
- Warm Standby: This option maintains a scaled-down but functional environment capable of immediately handling reduced traffic. Unlike pilot light, warm standby is ready to respond faster.
According to AWS, pilot light requires additional action before it can process requests, while warm standby can handle reduced traffic right away.
To streamline failover, tools like VMware Site Recovery Manager or Zerto can automate the process and reduce manual intervention, helping you meet your Recovery Time Objective (RTO). Infrastructure-as-code tools like Terraform or AWS CloudFormation can ensure your recovery site mirrors your primary environment, minimizing discrepancies.
While active-passive setups are cost-efficient, active-active configurations are designed to eliminate downtime altogether.
Active-Active Configuration
In an active-active configuration, all environments operate simultaneously, with traffic distributed across locations through load balancing. This setup minimizes downtime since there’s no need for a traditional failover; traffic is simply redirected from the failed site. However, it does require advanced data synchronization methods. You can either centralize all writes to one region ("write global") or enable writes in multiple locations with reconciliation strategies like "last writer wins".
For example, Amazon Aurora's global databases showcase the potential of this approach. They replicate data to secondary regions with a latency of under 1 second and can promote a secondary cluster for full read/write operations in less than a minute during a regional failure.
| Configuration | Cost | Recovery Speed (RTO) | Traffic Handling |
|---|---|---|---|
| Pilot Light | Low-Medium | Minutes to Hours | Secondary site requires provisioning first |
| Warm Standby | Medium-High | Minutes | Secondary site handles reduced traffic |
| Active-Active | High | Near Zero | All sites serve traffic simultaneously |
For organizations aiming to avoid the expense of duplicate physical infrastructure, cloud-based DR offers a flexible alternative.
Cloud-Based Disaster Recovery
Cloud-based DR leverages automated failover, block-level replication, and scalable resources, eliminating the need for idle on-premises hardware. This makes it an attractive option for businesses that prefer not to maintain unused infrastructure until a disaster occurs.
Before implementing cloud-based DR, conduct a Business Impact Analysis to identify critical applications and their dependencies. Clearly define your RTO and Recovery Point Objective (RPO) to ensure cloud-native tools meet your recovery requirements.
However, keep in mind potential challenges like bandwidth limitations, which can slow the transfer of large backup datasets between private and public environments. This delay could jeopardize your recovery timeline. Additionally, if regulations require sensitive data to remain on-premises, your DR strategy must account for these legal constraints.
"Taking a comprehensive approach to disaster recovery in hybrid cloud environments is crucial for today's businesses. This strategy offers the necessary flexibility, scalability, and resilience to shield against various types of threats", says David Cackowski from Veeam.
For a seamless failover process, rely on "data plane" operations - such as Route 53 health checks - instead of manual configurations. Data planes are designed to deliver higher availability, reducing the risk of human error during critical moments.
Data Security in Hybrid Backup Systems
Protecting backup data is just as important as creating it. With 93% of ransomware attacks targeting backup repositories and 85% of organizations experiencing such attacks in the past year, it's clear that a multi-layered defense strategy is essential. This includes strong encryption, strict access controls, and continuous monitoring to safeguard hybrid backup systems.
Encryption Standards for Data Protection
Encryption plays a key role in securing backup data. AES-256 ensures that data at rest remains unreadable, even if storage - whether physical or cloud-based - is compromised. For data in transit, TLS 1.3 protects against interception, while IPsec and SSH secure network communications and remote access.
A practical example of this strategy comes from Illinois State University (ISU). In 2024, ISU migrated its off-site backups to AWS using Commvault Cloud HyperScale X. Under the leadership of Devin Carlson, Assistant Director of Infrastructure Operations, and Craig Jackson, Executive Director of Technology Infrastructure & Research Computing, ISU implemented tiered storage with AES-256 encryption and deduplication. This move allowed the university to decommission a physical data center and quickly shift workloads to Amazon EC2 in the event of a disaster.
"If something catastrophic happens, if we need to spin up some [virtual machines] and do restores, now our backups are in the cloud, as opposed to having to move all that data across the wire before making services available."
– Craig Jackson, Executive Director of Technology Infrastructure & Research Computing, Illinois State University
To further enhance security, cloud key management services like AWS KMS, Azure Key Vault, and Google Cloud KMS provide secure storage for cryptographic keys. Experts recommend using self-managed keys instead of default provider keys for better control. Regularly rotating IAM access keys and removing unnecessary permissions also reduces risks tied to compromised credentials.
Once encryption is in place, controlling access becomes the next critical step.
Multi-Factor Authentication and Role-Based Access Control
Encryption is just one part of the puzzle. Adding layered access controls, such as multi-factor authentication (MFA) and role-based access control (RBAC), strengthens hybrid backup security. MFA ensures that access requires more than just a password, while RBAC grants users only the permissions they need, minimizing the risk of unauthorized changes or brute force attacks.
For instance, assigning "restore-only" permissions lets users recover data without altering backup settings. This separation of duties ensures no single person has full control over critical systems. A Zero Trust approach - where access is granted only when necessary - adds another layer of defense.
| Security Measure | Implementation Method | Primary Benefit |
|---|---|---|
| MFA | OTP, biometrics, digital signatures | Blocks unauthorized access from stolen passwords or brute force attempts |
| RBAC | Restore-only roles, administrative controls | Limits damage from compromised accounts |
| IAM | Granular role definitions, key rotation | Provides precise control and reduces risks tied to compromised credentials |
Continuous Data Protection
Continuous Data Protection (CDP) ensures real-time backups, reducing data loss from unexpected failures by eliminating gaps between scheduled backups. Security Information and Event Management (SIEM) tools analyze logs from on-premises and cloud environments to detect anomalies and potential threats.
Monitoring for unusual activity - like unexpected CPU spikes or abnormal network behavior - can uncover ransomware or other malicious processes. Automated tools that isolate infected systems can stop threats before they spread to backup repositories. Additionally, Data Loss Prevention (DLP) solutions help secure sensitive information by preventing unauthorized access or disclosure within hybrid environments.
These combined measures create a strong defense for hybrid backup systems, helping to counter evolving security threats effectively.
Building and Testing a Hybrid Backup Strategy
A disaster recovery plan serves as your roadmap for keeping operations running during unexpected disruptions. It begins with identifying your most critical systems and data, setting specific recovery goals, and routinely testing your procedures to ensure they deliver when needed.
Identifying Critical Systems and Data
Start by creating a detailed inventory of all assets in your hybrid environment. This includes on-premises servers, private cloud resources, and public cloud services. Understanding how these components interact is crucial - failure in one on-premises server, for instance, could ripple through and disrupt cloud-hosted applications.
A Business Impact Analysis (BIA) helps you prioritize systems based on their role in your operations. Not every asset demands the same level of protection, and trying to safeguard everything equally can be prohibitively expensive. A tiered approach allows you to focus resources where they matter most. For example, mission-critical systems like e-commerce platforms or electronic health records should take precedence, while less vital systems, such as marketing analytics, can receive lower-priority protection.
"You can't protect what you don't know you have." – Kraft Business Systems
Automated discovery tools can be invaluable for identifying virtual resources in real time. Use these tools to pinpoint critical data that should be stored with immutable or air-gapped backups, which are particularly effective against ransomware and other targeted attacks. Surprisingly, while 96% of organizations claim to have a disaster recovery system, only 13% manage to recover all their data after a ransomware attack.
Once your assets are identified and prioritized, it’s time to define clear recovery targets.
Setting RTO and RPO Targets
Recovery Time Objective (RTO) and Recovery Point Objective (RPO) are essential metrics that guide your disaster recovery strategy. These decisions are driven by the financial and operational impact of downtime and data loss. To put things into perspective, enterprise IT downtime in 2025 cost an average of $9,000 per minute. That’s a figure no business can ignore.
To set these targets, ask questions like: “What does one minute of downtime cost us in revenue?” and “What penalties do we face for missing SLAs?”. Use the answers to classify systems into tiers:
- Tier 1 (Mission-Critical Systems): Requires RTOs under an hour and RPOs measured in minutes or seconds. Techniques like continuous data replication or active-active setups are often necessary here.
- Tier 2 (Business-Critical Systems): Can tolerate 2–8 hours of downtime, often relying on snapshot technology for recovery.
- Tier 3 (Non-Essential Systems): May rely on daily backups with recovery windows exceeding 24 hours.
"If everything is deemed critical, then nothing is." – Kari Rivas, Senior Product Marketing Manager at Backblaze
Document the reasoning behind these targets so your infrastructure investments align with actual business needs. Whether you use basic cloud backups or more advanced replication methods will depend on these defined goals.
Regular Testing and Updates
Setting recovery targets is just the beginning. Regular testing ensures your disaster recovery plan works when it’s most needed.
"A DR plan that hasn't been tested is not a DR plan - it's a hope." – Alex Thompson, CEO of ZeonEdge
Despite its importance, a 2025 survey revealed that 43% of companies have never tested their disaster recovery plan, and 23% don’t even have one.
Testing should follow a tiered schedule:
- Tier 1: Monthly testing
- Tier 2: Quarterly testing
- Tier 3: Annual testing
Use a mix of methods, such as tabletop exercises to review procedures, component recovery tests to check backup integrity, and full failover simulations to validate the entire strategy. Companies with mature testing programs report 70% faster recovery times and 50% less data loss during incidents.
Each test should confirm that recovery times and data loss stay within your RTO and RPO limits. Automate processes where possible, using scripts to verify backup integrity and flag failures. After each test, document lessons learned, update your recovery plan, and assign follow-up actions. Also, keep contact lists, network diagrams, and recovery runbooks current - review these at least every six months or after major infrastructure updates.
For hybrid environments, don’t overlook critical details like validating cross-region replication, reviewing IAM permissions for recovery accounts, and monitoring API rate limits that could slow down large-scale restorations. Once your team is comfortable with the plan, unannounced "fire drills" can help gauge their readiness under pressure.
"The difference between having a DR plan and having a tested DR plan can mean the difference between business survival and catastrophic failure." – InventiveHQ Team
Conclusion
In today's hybrid environments, where on-premises systems integrate with cloud services, having a unified backup and recovery strategy is non-negotiable. Operational continuity depends on a well-thought-out approach that combines planning, execution, and frequent testing. Managing both on-premises and cloud resources is complex, and backup strategies must be proactive - especially with ransomware increasingly targeting backups.
Under the shared responsibility model, cloud providers maintain infrastructure availability, but securing and backing up your data is entirely your responsibility. This means adopting practices like the 3-2-1 backup rule, using immutable storage options such as Amazon S3 Object Lock or Azure Blob immutable storage, and creating secure air gaps with separate accounts or subscriptions.
"The worst thing any business can do is wait until it's the subject of a ransomware or hacking attack to plan for disaster recovery." – Sam Nicholls, Director for Public Cloud Product Marketing, Veeam
Ownership also includes setting measurable recovery performance goals. Define clear Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO), and conduct regular tests to ensure your recovery processes are effective. Skipping disaster recovery testing is a common but costly mistake.
Hybrid environments bring their own set of challenges, like bandwidth constraints and limited scalability for on-premises systems. Addressing these challenges requires constant vigilance. Your disaster recovery plan should be a dynamic document - one that evolves with your infrastructure, incorporates lessons from testing, and adapts to emerging threats. The cost of insufficient preparation far outweighs the investment in a comprehensive hybrid backup strategy.
FAQs
How do I choose the right RTO and RPO for each system?
To figure out the best RTO (Recovery Time Objective) and RPO (Recovery Point Objective) for your business, start by evaluating how much downtime and data loss your operations can handle. For critical systems where even a small amount of data loss is unacceptable, you may need near-zero RPOs. Similarly, essential operations often require very short RTOs to minimize disruptions.
Your backup and recovery strategies should match these needs. For low RPOs, technologies like continuous replication can help by ensuring data is updated almost in real time. For low RTOs, automated failover systems can significantly reduce recovery times.
Don't forget to regularly test your disaster recovery plan. This ensures your strategies actually align with your RTO and RPO goals when it matters most.
When should I use replication vs snapshots vs backups?
When deciding how to protect your data, consider these options based on your specific needs:
- Replication: Perfect for creating real-time or near-real-time data copies. It's ideal for maintaining high availability and enabling rapid recovery in case of system issues.
- Snapshots: Best for quick restores of recent data states. These are particularly useful if you need to recover from accidental deletions or data corruption.
- Backups: Designed for long-term data retention and recovery from significant disasters, such as ransomware attacks or hardware failures.
Each method addresses different recovery goals, depending on the type of threat and your tolerance for downtime.
How can I ransomware-proof my backups in a hybrid setup?
To keep your backups safe from ransomware in a hybrid environment, stick to these practical steps:
- Follow the 3-2-1 rule: Keep at least three copies of your data, store them on two different types of media, and ensure one copy is offsite. This ensures redundancy and resilience.
- Implement logical air gaps: Isolate backups from your primary systems to make it harder for ransomware to reach them.
- Enable immutability: Configure your backups so they can't be altered or deleted, even by administrators.
Additionally, take these extra precautions:
- Apply the principle of least privilege (PoLP): Restrict access to backups only to those who absolutely need it.
- Encrypt your backups: Protect data both during storage and while it's being transmitted.
- Test recovery processes regularly: Simulate recovery scenarios to confirm your backups work as expected and are ready when needed.
These steps help ensure your backups stay secure and accessible, even in the face of ransomware threats.