How Data Preprocessing Affects AI Model Speed
Data preprocessing directly impacts how fast AI models train and make predictions. Poor preprocessing slows down GPUs, causing inefficiencies like idle time and bottlenecks. Optimized pipelines, on the other hand, can improve training speeds by 20% to 40% or even reduce processing time by up to 5x with advanced tools.
Key takeaways:
- Good preprocessing = faster training. Efficient pipelines keep GPUs busy, avoiding delays caused by slow CPUs.
- Common issues: GPU starvation, head-of-line blocking, unscaled features, and redundant data inflate training times.
- Fixes: Use feature scaling, dimensionality reduction (like PCA), and GPU-accelerated tools (e.g., NVIDIA RAPIDS, DALI) to speed up data preparation.
- Impact: GPU utilization can rise from 46% to over 90%, cutting training times significantly.
In short, a well-optimized preprocessing pipeline is essential for faster, more efficient AI workflows.
Data Preprocessing and Transformation in Machine Learning | Kelly Hoang, Gilead Sciences
How Data Preprocessing Affects AI Model Speed
This section explores how certain preprocessing choices can slow down both training and inference. By identifying these issues, you'll be better equipped to optimize preprocessing pipelines later.
How Unscaled Features Slow Down Training and Inference
When features aren't scaled, gradient descent struggles to operate efficiently. For example, consider mile ranges (0–3,000) versus dollar values ($10–$100): the vast difference in scale forces gradient descent into inefficient zigzag paths.
Models like KNN, which rely on distance metrics, are particularly sensitive to scaling. Without proper feature scaling, larger values dominate calculations, overshadowing smaller but potentially more important features. This imbalance skews predictions and hampers the learning process.
While scaling problems disrupt optimization, redundant data adds another layer of inefficiency.
How Redundant Data Increases Processing Time
Redundant features inflate data size, increasing the computational workload during both training and inference. Every redundant column means extra calculations, more memory usage, and longer runtimes - all without improving model performance.
High-cardinality features encoded with one-hot encoding are a prime example. A single categorical variable with 500 unique values transforms into 500 separate columns, leading to what's known as the "curse of dimensionality". This explosion in data size not only slows training but also drags down real-time prediction speeds.
These challenges highlight the importance of avoiding common preprocessing pitfalls, as shown in the table below.
Common Preprocessing Mistakes and Their Speed Impact
| Preprocessing Error | Speed Impact | Technical Cause |
|---|---|---|
| Missing Feature Scaling | Delayed Convergence | Inconsistent feature ranges slow down gradient descent. |
| Inefficient Looping | CPU Bottleneck | Pure Python operations lag behind optimized C++/CUDA kernels. |
| Sequential Loading | GPU Starvation | The GPU waits idly for the CPU to prepare data batches. |
| High-Cardinality One-Hot | Increased Inference Time | One-hot encoding inflates dimensionality, adding overhead. |
| Redundant Features | Increased Processing Time | Extra, irrelevant data adds noise and unnecessary calculations. |
| Unoptimized I/O | High Latency | Reading numerous small files creates significant filesystem delays. |
How to Optimize Data Preprocessing for Speed
Speeding up data preprocessing is essential for efficient machine learning workflows, especially when dealing with large datasets. Here are practical methods to tackle bottlenecks while preserving model accuracy.
Feature Scaling Methods to Boost Efficiency
Scaling features ensures models perform optimally without being influenced by differences in feature magnitude. Here are some effective scaling techniques:
-
Standardization: This method transforms features to have a mean of zero and a variance of one. It's crucial for algorithms like Support Vector Machines or linear models with regularization, as it prevents features with larger variances from dominating the learning process.
from sklearn.preprocessing import StandardScaler scaler = StandardScaler().fit(X_train) X_train_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test) -
Min-Max Scaling: This compresses features into a specific range (e.g., [0, 1]), which is particularly useful for preserving zero entries in sparse datasets.
from sklearn.preprocessing import MinMaxScaler min_max_scaler = MinMaxScaler() X_train_minmax = min_max_scaler.fit_transform(X_train) - MaxAbsScaler: Ideal for sparse data, this scales features to the range [-1, 1] without shifting them, maintaining the dataset's sparsity structure.
- RobustScaler: For datasets with many outliers, this method uses the median and interquartile range, making it less sensitive to extreme values.
To enhance speed, process data in bulk rather than item-by-item. Bulk operations can be 10–100 times faster, thanks to CPU cache optimizations. Additionally, pairing sparse input data with sparse models can reduce latency by over 30% in linear models.
Pro Tip: Always fit scalers on the training set and apply them to the test set to avoid data leakage, which can lead to overly optimistic performance estimates.
Reducing Dataset Size with Dimensionality Reduction
After scaling, reducing the number of features can significantly cut down computational overhead. Principal Component Analysis (PCA) is a popular method for this. It identifies the most informative features, eliminates redundancies, and simplifies models, which can also help mitigate overfitting.
Important Notes for PCA:
- Always standardize features before applying PCA, as it is sensitive to magnitude differences.
- Enabling whitening (
whiten=Truein Scikit-learn) removes linear correlations between features, which benefits downstream models that assume feature independence.
For even greater speed, GPU acceleration can transform data preprocessing. Libraries like NVIDIA RAPIDS can boost performance by as much as 150 times compared to traditional CPU-based processing, drastically reducing the time required for dimensionality reduction tasks.
| Technique | Primary Benefit for Speed | Impact on Dataset |
|---|---|---|
| PCA | Reduces computational load by identifying principal components | Compresses features into fewer, uncorrelated variables |
| Feature Selection | Removes irrelevant or redundant features | Reduces the number of columns in the dataset |
| GPU Acceleration | Speeds up data preparation by leveraging parallel processing | Handles larger datasets in shorter timeframes |
Using Scikit-learn's Pipeline is a smart way to combine scaling and dimensionality reduction. It ensures consistent transformation across training and test data, reducing manual errors and streamlining the process.
Streamlining Data Cleaning Operations
Beyond scaling and dimensionality reduction, optimizing data cleaning can further minimize delays caused by input/output operations.
Here are some key techniques:
-
Parallelization: Use multiple CPU cores to load and transform data simultaneously. For instance, in PyTorch, set
num_workersto match the number of CPU cores. In TensorFlow, usenum_parallel_callswithindataset.map(). -
Prefetching: Prepare the next batch of data while the current batch is being processed. In PyTorch, enabling
pin_memory=Truein theDataLoaderspeeds up data transfer to the GPU. -
Caching: If your dataset fits in RAM, cache preprocessed results after the first epoch. In TensorFlow, use
.cache()before shuffling and batching. - Vectorization: Replace Python loops with vectorized operations from libraries like NumPy, TensorFlow, or PyTorch to process data more efficiently.
- Binary Formats: Store data in formats like TFRecord, WebDataset, or Parquet to minimize filesystem overhead and improve read/write speeds.
Efficient pipelines work like assembly lines, where CPU preprocessing and GPU training happen in parallel. This avoids the inefficiency of sequential pipelines, where the CPU waits for the GPU to finish processing.
"A powerful GPU is only as fast as the data you can feed it" - ApX Machine Learning
sbb-itb-903b5f2
Using GPU Acceleration for Faster Preprocessing
CPU vs GPU Data Preprocessing Performance Comparison
If your preprocessing pipeline can't keep up with your GPU's training speed, you're wasting valuable compute resources. Modern GPUs, like the NVIDIA A100, process data so quickly that CPU-based tools - such as Pandas, Scikit-Learn, or native framework loaders - often become the bottleneck. This leaves your GPU waiting idly for the next batch of data to arrive.
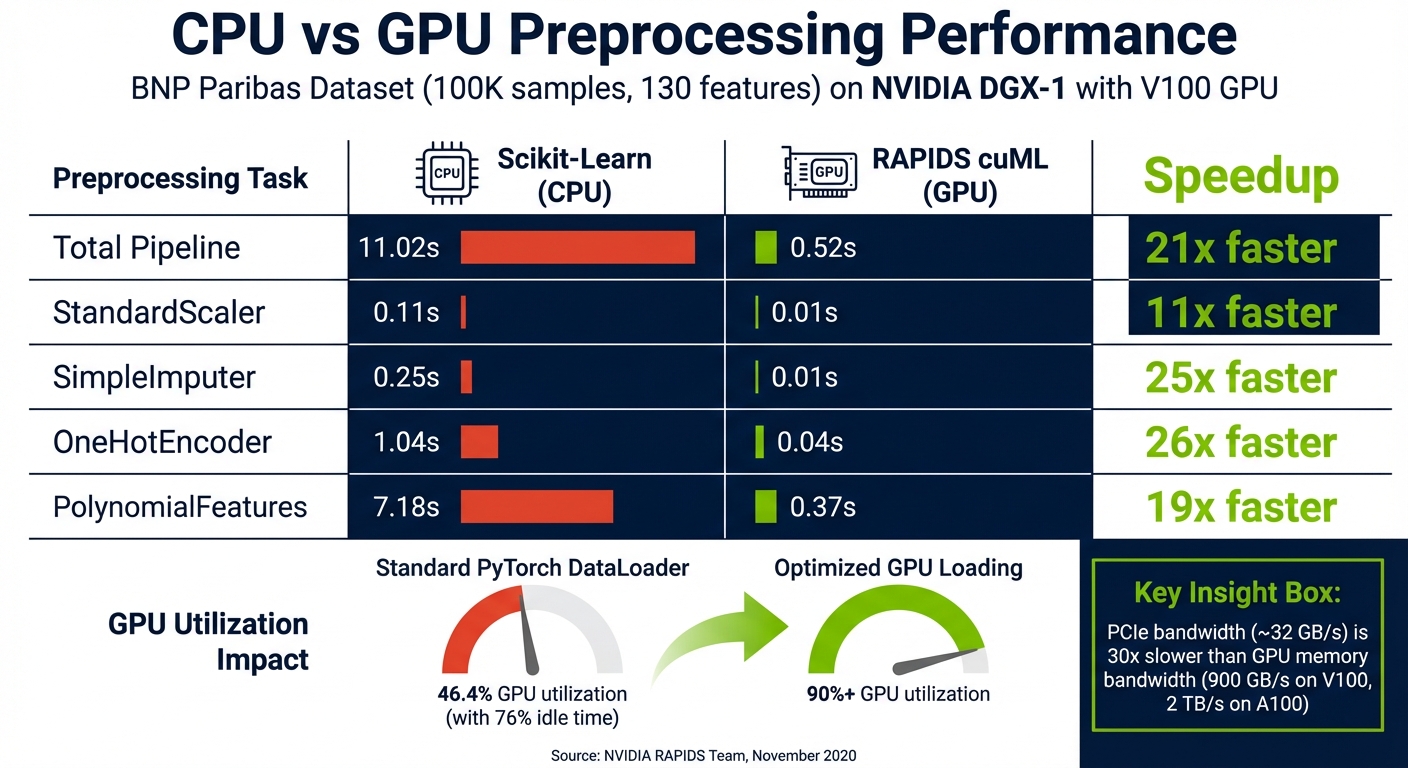
The fix? Shift your entire preprocessing workflow to the GPU. Tools like NVIDIA RAPIDS for tabular data and NVIDIA DALI for images, video, and audio ensure the data remains on the GPU throughout the pipeline. This avoids the slow transfer between CPU and GPU memory. Why does this matter? PCIe bandwidth (around 32 GB/s) is roughly 30 times slower than GPU memory bandwidth, which can reach 900 GB/s on a V100 and up to 2 TB/s on an A100. That massive difference in transfer speed highlights why GPU-based preprocessing is a game-changer.
"Dense multi-GPU systems like the NVIDIA DGX-2 and DGX A100 train a model much faster than data can be provided by the input pipeline, leaving the GPUs starved for data." - Joaquin Anton Guirao, Senior Software Engineer, NVIDIA
The scope of this issue is enormous. Google’s internal data reveals that 30% of total compute time in machine learning jobs is spent on input data processing. For one in five jobs, preprocessing consumes over one-third of the entire training time. In extreme cases, it can eat up as much as 65% of each epoch.
How GPUs Speed Up Data Preparation
GPU-accelerated preprocessing libraries take advantage of thousands of parallel cores to handle tasks that would overwhelm a CPU. For example, the NVIDIA A100 boasts 6,912 CUDA cores, while even high-end CPUs only have a few dozen. This level of parallelism leads to massive speed improvements for tasks like scaling, encoding, and feature transformations.
In November 2020, William Hicks from the NVIDIA RAPIDS team demonstrated this using the BNP Paribas Cardif Claims Management dataset (100,000 samples, 130 features). By swapping out Scikit-Learn with RAPIDS cuML on a single V100 GPU, the preprocessing time dropped from 11.02 seconds to 0.52 seconds - a 21x speedup. Some individual operations saw even greater improvements: SimpleImputer went from 0.25 seconds to 0.01 seconds (25x faster), while OneHotEncoder dropped from 1.04 seconds to 0.04 seconds (26x faster).
For deep learning tasks involving images or video, NVIDIA DALI processes decoding (e.g., JPEG, H.264) and augmentations (e.g., resizing, cropping, color adjustments) directly on the GPU. In October 2021, NVIDIA engineers showed that using DALI for ResNet-50 training boosted throughput by 2x to 5x compared to CPU-based data loaders. This brought performance much closer to the theoretical maximum achieved when using synthetic data already stored in GPU memory.
Similarly, RAPIDS cuDF can handle DataFrame operations up to 150x faster than Pandas on an A100 GPU. For ETL pipelines involving tasks like cleaning, joining, and aggregating large datasets, processes that take 16 minutes on a CPU can be completed in just 6 seconds on a GPU - a 49x speedup.
These examples underscore just how much faster preprocessing becomes when leveraging GPU acceleration.
CPU vs. GPU Preprocessing Performance
The performance gap between CPU and GPU preprocessing is evident across a range of operations. Here's a comparison using the BNP Paribas dataset on an NVIDIA DGX-1 with a V100 GPU:
| Preprocessing Task | Scikit-Learn (CPU) | RAPIDS cuML (GPU) | Speedup |
|---|---|---|---|
| Total Pipeline | 11.02s | 0.52s | ~21x |
| StandardScaler | 0.11s | 0.01s | 11x |
| SimpleImputer | 0.25s | 0.01s | 25x |
| OneHotEncoder | 1.04s | 0.04s | 26x |
| PolynomialFeatures | 7.18s | 0.37s | 19x |
GPU utilization also sees a huge boost. Standard PyTorch DataLoaders often leave GPUs idle 76% of the time, with average utilization hovering around 46.4%. By switching to optimized GPU-based loading strategies, utilization can exceed 90%.
These benchmarks highlight how GPU-based preprocessing not only slashes latency but also maximizes training throughput. Reducing CPU-to-GPU transfers is key to avoiding PCIe bottlenecks and making the most of your GPU's speed.
Measuring Preprocessing Performance Improvements
Once you've optimized your data preprocessing, the next crucial step is measuring the impact of those changes. After all, if you don't measure, you can't truly evaluate whether your improvements are effective. Whether you've implemented GPU-accelerated preprocessing or streamlined your pipeline in other ways, benchmarking is essential to verify the results.
Metrics for Measuring Preprocessing Efficiency
To determine if your preprocessing pipeline is performing well, focus on three key metrics:
- Inference latency: This measures the time it takes for a single forward pass or training step. If you notice significant delays between steps in a trace viewer, it’s a clear sign that your preprocessing might be the issue.
- Throughput: This tracks how many batches are processed per second, ensuring your GPU remains consistently active and not waiting for data.
- End-to-end processing time: This metric captures the complete process - from raw data extraction to final model output - helping reduce overall response times.
For an optimized TensorFlow pipeline, data requests should typically take no more than 50 microseconds. If IteratorGetNext calls exceed this threshold, your model is likely idling while waiting for data. Another crucial indicator is resource utilization. For instance, if your CPU is maxed out while your GPU usage hovers at just 20%, it’s a clear mismatch - your preprocessing isn't keeping pace with your model's demands. These metrics provide a solid foundation for identifying bottlenecks and fine-tuning your pipeline.
Tools for Monitoring Preprocessing Performance
Both TensorFlow and PyTorch offer powerful profiling tools to help identify and resolve bottlenecks in your pipeline.
- TensorFlow Profiler: This tool includes an Input Pipeline Analyzer, which can reveal if your program is "input bound" - essentially, when your GPU is starving for data. The Trace Viewer provides a detailed timeline of operations, with red gaps between training steps indicating preprocessing delays.
-
PyTorch Profiler: PyTorch uses context managers like
profiler.record_function("label")to analyze specific preprocessing tasks. This feature helps measure the time and memory costs of individual operations, making it easier to pinpoint inefficiencies. For example, in a PyTorch tutorial (updated November 2025), a developer optimized a "MASK INDICES" operation. By switching from NumPy'sargwhereon the CPU (5.931 seconds) totorch.nonzero()on the GPU, they reduced the operation time to just 225.801 milliseconds.
A straightforward benchmarking technique involves comparing your model's performance using real-world data versus synthetic data. If your model runs significantly faster with synthetic data, it’s a strong indication that preprocessing is the bottleneck. For quick checks, tools like nvidia-smi (for GPU monitoring) and htop (for CPU usage) can provide valuable insights before diving into more detailed profiling.
Conclusion
Main Points to Remember
Inefficient preprocessing can seriously limit GPU performance. As ApX Machine Learning explains, "A powerful GPU is only as fast as the data you can feed it". A sluggish pipeline can lead to GPU starvation, leaving hardware idle for as much as 76% of the time.
By focusing on optimized preprocessing, you can significantly improve GPU utilization - from 46.4% to 90.45% - and reduce training times by up to 7.5x. These improvements come from techniques like parallelization, prefetching, and sample-aware scheduling. Not only do these strategies enhance performance, but they also lower operational costs.
Cost efficiency is another major benefit. Prompt caching, for instance, can reduce token reprocessing by up to 90%. Similarly, optimized multi-stage pipelines can improve tokens-per-dollar efficiency by as much as 4.7x. For tools like NanoGPT, which offer pay-as-you-go AI model access, these optimizations directly translate to lower expenses and faster response times.
Beyond speed and cost savings, preprocessing optimizations can also improve user privacy. By caching data locally - similar to how NanoGPT stores information on users' devices - there’s less need for repeated data transfers to external servers. This approach not only speeds up processes and reduces costs but also ensures greater privacy for users.
FAQs
How does feature scaling enhance the speed of AI models?
Feature scaling speeds up AI models by standardizing the range of input data. This process ensures that features with larger numerical values don’t overpower smaller ones during training, helping algorithms converge faster and work more efficiently.
By normalizing the data, feature scaling not only cuts down computation time but also streamlines the preprocessing pipeline. The result? Faster model responses and smoother training workflows.
How does GPU acceleration improve data preprocessing for AI models?
GPU acceleration supercharges data preprocessing by significantly boosting the speed of data transformations and loading tasks. Instead of relying solely on the CPU, these processes are handled directly on the GPU, cutting down on delays caused by data transfers between the two. The result? A faster, more seamless pipeline.
By reducing bottlenecks and keeping the GPU consistently active, this method can noticeably cut training times. For AI models, efficient preprocessing means faster response times and better performance overall.
How does redundant data slow down AI model training?
Redundant data can drag down the efficiency of AI model training by clogging up the preprocessing pipeline. When duplicate or irrelevant data is included, it eats up computational power and stretches out processing time, slowing the entire training process.
In larger systems, redundant data can create bottlenecks during data transfers, particularly when moving datasets from remote storage. To avoid these slowdowns, it's crucial to optimize preprocessing by eliminating duplicates and simplifying data handling. Tackling redundancy ensures your pipeline operates smoothly, helping AI models train faster and making better use of available resources.