DevSecMLOps: Securing Machine Learning Pipelines
Machine learning systems are under attack - from poisoned datasets to adversarial inputs and model theft. As ML becomes central to industries like banking and healthcare, these risks are growing. Enter DevSecMLOps: a security-first approach to protect every stage of the ML lifecycle.
Key Highlights:
-
What is DevSecMLOps?
A blend of MLOps and security practices ensuring protection of data, models, and code across the pipeline. -
Why it matters:
ML systems face unique threats like data poisoning, model inversion, and adversarial inputs, which traditional security methods can't handle. -
How it works:
Security is integrated into all stages - data ingestion, model training, deployment, and inference. Tools like Sigstore, Great Expectations, and Snyk automate checks for vulnerabilities. -
Real-world impact:
Companies adopting DevSecMLOps report fewer security incidents and save millions by preventing breaches.
This methodology ensures that ML pipelines are not just functional but secure - protecting sensitive data, reducing risks, and maintaining compliance. Let’s explore how to implement it effectively.
Core Principles of DevSecMLOps
Shared Responsibility and Security by Design
In DevSecMLOps, security isn't just a task for one team - it's a shared responsibility across data science, ML engineering, and security teams. A practical way to achieve this is by embedding ML Security Champions within data science teams - individuals who understand both the technical aspects of modeling and the security implications of their work.
As Cranium AI explains:
"The non-deterministic nature of models means that security must be embedded in the model's behavior and its lineage, not just in the code that wraps it."
This highlights the importance of tracking model lineage. By keeping tabs on datasets, training runs, and code versions that contribute to a model, teams can quickly trace issues and roll back changes when necessary. A collaborative and forward-thinking approach to security naturally leads to the automation and enforcement of robust policies.
Automation and Policy Enforcement
Automated security checks are a must-have in CI/CD pipelines to ensure code, data, and model integrity. Google Cloud's architecture guidance emphasizes:
"CI is no longer only about testing and validating code and components, but also testing and validating data, data schemas, and models."
Tools like Open Policy Agent (OPA) make this possible by allowing teams to define and enforce rules automatically. For example, policies can block deployments to unapproved regions, reject models with unverified dependencies, or stop progress if accuracy drops below a set threshold. Automated governance gates can also flag fairness violations or detect critical vulnerabilities (CVEs) in dependencies.
Several tools help enforce these policies:
- Snyk for library vulnerability scanning
- Great Expectations for monitoring data quality
- Sigstore for signing model artifacts to prevent substitution attacks
A fintech client of Consensus Labs implemented this approach in August 2025 for their fraud-detection pipeline. They used Great Expectations to catch data ingestion errors, Snyk to address a high-severity TensorFlow CVE, and Kubernetes admission controllers to verify signed model binaries before deployment. This strategy reduced security incidents by 40% while maintaining uninterrupted operations during peak trading periods.
By combining automation with continuous monitoring, teams can build a proactive defense strategy that minimizes risks and ensures smooth operations.
Defense in Depth for ML Systems
While automated policies provide a strong first line of defense, relying on a single control is risky. A layered approach - known as defense in depth - ensures resilience by stacking multiple protective measures across data, models, and infrastructure.
Real-world examples show why this approach matters. In December 2022, attackers exploited a dependency confusion attack using a malicious PyPI package called torchtriton. It was downloaded 2,717 times and exfiltrated sensitive data like SSH keys via encrypted DNS requests. Two years later, in December 2024, attackers exploited a GitHub Actions vulnerability in the Ultralytics package, which had 60 million downloads. This attack delivered cryptomining payloads, causing some victims' cloud bills to skyrocket by $50,000 to $150,000.
These incidents aren't outliers. Research from perfecXion shows that 45% of AI-related breaches now stem from the supply chain, and 77% of organizations reported AI system breaches in 2024.
The table below outlines how layered defenses can protect different aspects of an ML system:
| Security Layer | What to Protect Against | Key Controls |
|---|---|---|
| Data | Poisoning, silent corruption | Immutable storage, cryptographic checksums, schema validation |
| Dependencies | Malicious packages, CVEs | SCA scanning (Snyk, Trivy), vetted base images |
| Model Artifacts | Tampering, substitution | Digital signing (Sigstore), secure model registry |
| Runtime/Inference | Adversarial inputs, data leaks | Input validation, anomaly detection at endpoints |
| Infrastructure | Misconfigured cloud resources | IaC scanning (Checkov, tfsec), hardened containers |
One simple but impactful step is to avoid using Pickle serialization for model files. About 80% of Hugging Face models rely on Pickle, which is highly vulnerable to remote code execution. Switching to SafeTensors eliminates this risk without disrupting the rest of the pipeline.
sbb-itb-903b5f2
Secure AI Pipelines MLOps DevSecOps Essentials
Securing the ML Pipeline Architecture
Building on the principles of DevSecMLOps, securing every stage of the machine learning (ML) pipeline is non-negotiable.
End-to-End Pipeline Security
To ensure a secure pipeline, every stage must validate data integrity before passing it along. Automated policy enforcement acts as a safety net, preventing any stage from becoming a weak link.
| Pipeline Stage | Primary Threat | Key Controls |
|---|---|---|
| Data Ingestion | Data poisoning, PII leakage | Schema validation, mTLS, checksums |
| Data Preparation | Sensitive data exposure | Data anonymization (e.g., Presidio), versioning (DVC), encryption at rest |
| Model Training | Dependency CVEs, insider threats | Confidential VMs, network isolation, RBAC |
| Model Registry | Artifact tampering, model theft | Cryptographic signing (Sigstore), SBOM generation |
| Inference | Adversarial inputs, model inversion | Rate limiting, input sanitization, prompt shields |
| Monitoring | Silent drift, evasion attacks | Drift detection (Evidently AI), runtime anomaly alerts |
A Zero Trust approach is key: treat every dataset, API call, container, notebook, and model artifact as potentially hostile until proven otherwise - and keep validating them every time. For example, a training job should NEVER have write access to production inference buckets.
These layered controls create a foundation for strong data and registry security, as discussed below.
Data Security and Compliance
Data is the most vulnerable part of ML pipelines. Two major risks stand out: data poisoning, where malicious samples manipulate model behavior, and sensitive data leakage, where personal information (like PII or PHI) is unintentionally exposed in training datasets.
For industries like healthcare in the US, compliance with HIPAA makes data security even more critical. Teams must also guard against model inversion attacks, which could reconstruct sensitive records from model outputs. A proven defense is Differential Privacy (DP), which limits how much influence any single record has on the final model. Tools like Microsoft Presidio can automatically remove sensitive fields - such as Social Security numbers or birth dates - before training begins.
Data versioning is another must-have. Tools like DVC (Data Version Control) paired with Git ensure reproducibility and provide a forensic trail for troubleshooting. When combined with encryption keys managed by customers (e.g., AWS KMS), this approach aligns with HIPAA safeguards and SOC 2 audit standards. These measures, integrated with automated governance, enforce compliance throughout the pipeline. Ignoring these steps can lead to costly consequences - SOC 2 violations in ML workflows have triggered fines exceeding $50,000 per incident.
While securing data is critical, protecting model artifacts is equally important.
Model Artifact and Registry Security
Once a model is trained, the artifact becomes a prime target. For instance, an attacker could replace a legitimate model with a backdoored one, causing harm without altering the training code.
One effective defense is a "no signature, no deploy" policy. Using Sigstore, teams can cryptographically sign artifacts (e.g., ONNX or SafeTensors formats) and enforce signature verification at the registry before deploying models to production. This approach is critical - consider the 2024 breach where authentication tokens for over 1.2 million users and 10,000 organizations at Hugging Face were exposed, potentially allowing unauthorized access to private model repositories.
Another important safeguard is creating an AI Bill of Materials (AI-BOM) for every model release. This document lists all datasets, base models, and software dependencies used during training, streamlining responses to new vulnerabilities. Tools like MLflow and Notary can automate this process within registry workflows.
Applying DevSecMLOps to AI Model Access Platforms
Protecting AI model access platforms goes beyond securing individual pipelines - it's about scaling those principles to safeguard the entire platform. With multiple AI models in play, a single misstep can expose every model and user to risk. The DevSecMLOps strategies that work for individual pipelines are just as relevant here, but the stakes rise dramatically when applied at scale.
Security in AI Model Access Workflows
In previous sections, we covered the importance of mTLS and rate limiting for individual pipelines. These controls become even more critical on a platform level, where they must secure every inference endpoint across all hosted models. A Zero Trust API gateway can enforce mTLS, rate limiting, and RBAC across endpoints. Without rate limiting, attackers could exploit vulnerabilities to launch model extraction attacks, using high-volume queries to reverse-engineer a model's parameters.
Each stage of the workflow introduces risks. For example, incoming prompts must be sanitized to block injection attacks - identified as LLM01 in the OWASP Top 10 for LLM Applications. Similarly, model responses should be filtered to ensure sensitive data doesn’t reach the user. As Siddardha Vangala, Senior AI Engineer at MasTec, aptly noted:
"AI is fundamentally shifting DevSecOps from reactive validation to continuous, intelligent enforcement."
The importance of these measures is underscored by alarming trends: 99% of organizations deploying AI systems reported security incidents in 2024–2025. Additionally, companies relying on unauthorized "shadow AI" tools faced data breaches that cost an average of $670,000 more per incident.
Next, let’s examine how privacy-focused design can further reduce risks.
Privacy-Preserving Design and Local Data Storage
Beyond securing APIs, limiting centralized data storage is another way to protect platforms. A key strategy? Avoid centralizing data unnecessarily. Platforms like NanoGPT demonstrate this by storing user data locally on user devices instead of centralized servers. This approach reduces the attack surface, as it eliminates a single repository of sensitive data.
This "local-first" mindset aligns with a broader DevSecMLOps principle: reducing the potential damage of a single failure. When sensitive data stays on the user’s device, risks such as large-scale credential theft or centralized data breaches are significantly lowered.
Additional Security Controls for Platforms
Scaling DevSecMLOps to multi-model platforms introduces added complexity. For instance, identity and secret management become even more crucial. Machine identities now outnumber human ones by a staggering 82 to 1 ratio. This makes leaked API keys a significant threat. Tools like Gitleaks and truffleHog can help by scanning for hardcoded credentials across numerous repositories and integration points. Additionally, replacing long-lived API keys with short-lived, scoped tokens managed by secure vaults (e.g., HashiCorp Vault) provides extra protection.
For multi-tenant platforms, strict user isolation is a must. Using dedicated Kubernetes namespaces with scoped IAM permissions ensures one user's workload cannot access another's data or compute resources. For GPU-heavy inference tasks, virtual partitioning or dedicated hardware can prevent side-channel attacks between tenants.
Here’s a quick summary of the essential security layers every AI model access platform should implement:
| Layer | Key Controls |
|---|---|
| Network | TLS 1.3, mTLS, API gateway, VNet isolation |
| Application | Input validation, rate limiting, RBAC, output filtering |
| Model | Signed artifacts, version control, access logging |
| Data | Encryption at rest (AES-256), PII detection, local storage |
| Infrastructure | Container scanning, short-lived tokens, GPU partitioning |
Running and Monitoring DevSecMLOps in Practice
DevSecMLOps: 4-Phase Implementation Roadmap for Secure ML Pipelines
Once you've set up a solid security framework, the real challenge begins: maintaining ongoing security. It's not enough to just deploy controls - you also need to spot issues quickly, prove compliance to auditors, and keep improving your defenses. In 2024, 77% of organizations reported AI-related breaches, with an average detection time of 194 days. In machine learning pipelines, problems are often only noticed after the model's performance visibly declines in production.
Continuous Monitoring and Threat Detection
Good monitoring covers four key layers, each aimed at catching specific types of threats:
| Monitoring Category | Key Metrics | Recommended Tools |
|---|---|---|
| Model Health | Accuracy, latency, output entropy, confidence thresholds | Evidently AI, Arize, KServe |
| Infrastructure | GPU utilization, CPU/memory usage, cloud spend | Prometheus, Grafana, Sysdig |
| Security/Supply Chain | CVE counts, signature status, API request spikes | Trivy, Sigstore, Cosign |
| Data Integrity | Input distribution shifts, label consistency | DVC, Great Expectations, Pachyderm |
For example, tracking GPU usage can help you detect cryptomining attacks early. The 2024 Ultralytics breach highlighted how automated circuit breakers - triggered by cost or GPU anomalies - can dramatically reduce detection times.
Drift detection is another must-have. Automating statistical tests, like the Kolmogorov-Smirnov test, can alert you when input data shifts beyond acceptable limits. Even a tiny poisoning attack - just 0.1% of a training dataset - can alter a model's behavior. Catching these shifts early is far cheaper and less disruptive than dealing with a full production failure later.
"The greatest threat to ML systems isn't adversarial examples or clever prompt injections - it's the supply chain." - perfecXion Research Team
These monitoring efforts naturally tie into governance practices, helping maintain compliance and accountability.
Governance and Compliance in ML Pipelines
Once monitoring is in place, the next step is to build governance into your ML pipeline. The insights you gather can power compliance-as-code, ensuring each deployment meets both security and regulatory standards. This approach replaces manual evidence collection with automated processes - like generating audit logs, validation reports, and model cards directly within the pipeline.
To maintain accountability, assign clear ownership of production models. Include representatives from business, data science, and risk management teams. Without this structure, it's easy for accountability to fall through the cracks when problems occur.
Treat retraining like a new deployment. Every updated model should go through the same validation and checks as the original launch. Silent logic drift - where a model's behavior changes subtly over time - can be one of the hardest problems to catch.
For regulatory compliance, don't start from scratch. Use established frameworks like NIST AI RMF or ISO/IEC 42001. Both Texas and California offer compliance benefits for organizations following these standards. For instance, the Texas Responsible AI Governance Act takes effect on January 1, 2026, while California's AI Transparency Act begins on August 2, 2026.
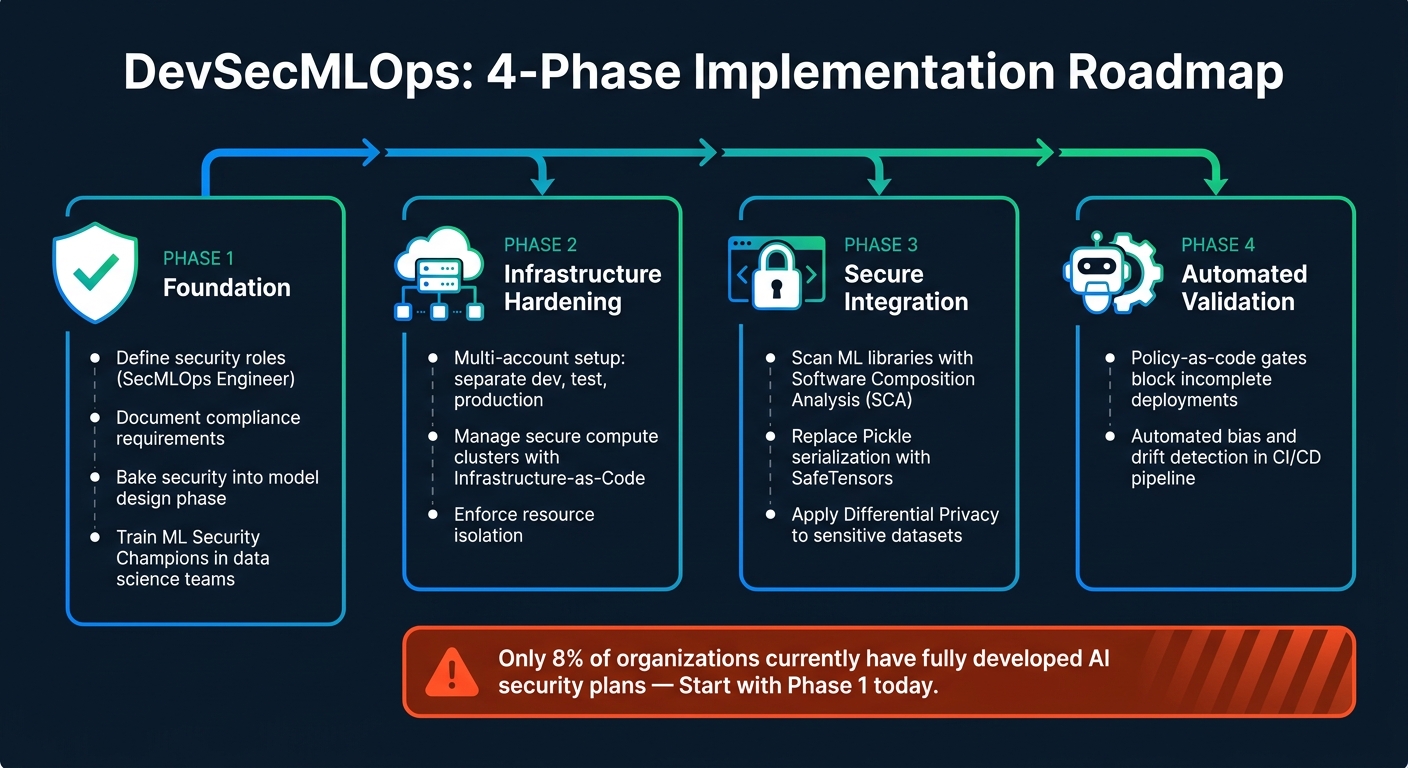
A Phased Plan for Adopting DevSecMLOps
To secure your ML pipeline effectively, follow a phased approach:
- Phase 1 - Foundation: Define security roles (such as a SecMLOps Engineer), document compliance requirements, and bake security into the model design phase. Train ML Security Champions within your data science teams.
- Phase 2 - Infrastructure Hardening: Use a multi-account setup to separate development, testing, and production environments. Manage secure compute clusters with Infrastructure-as-Code and enforce resource isolation.
- Phase 3 - Secure Integration: Scan ML libraries for vulnerabilities using Software Composition Analysis (SCA). Replace pickle-based model serialization with SafeTensors to avoid remote code execution risks. Apply differential privacy to safeguard sensitive datasets.
- Phase 4 - Automated Validation: Set up policy-as-code gates to block deployments if documentation is incomplete or validation fails. Integrate automated bias and drift detection into your CI/CD pipeline.
Right now, only 8% of organizations have fully developed AI security plans. Starting with Phase 1 gives you a solid security foundation, and each phase builds on the last to create a stronger, more secure pipeline.
Conclusion
ML pipelines represent a critical area for security. With 77% of organizations reporting at least one AI-related breach in 2024 and the average cost of such breaches reaching $4.88 million, it’s clear that ignoring security is no longer an option.
DevSecMLOps integrates security into every stage of the ML lifecycle. Whether it’s safeguarding training data from poisoning attacks, signing model artifacts with tools like Sigstore, or implementing policy-as-code gates in CI/CD pipelines, each step strengthens the overall security of the pipeline. As security researcher Jayriniv explains:
"Security now needs to be built into not just code, but data pipelines, training artifacts, and runtime outputs."
This multi-layered approach doesn’t just enhance security - it also delivers real-world benefits. For example, a fintech company that adopted DevSecMLOps reported a 40% reduction in security incidents, saving an average of $2.2 million per breach. These improvements can mean the difference between a manageable issue and a full-scale disaster.
Adopting a phased strategy - from defining security roles to automating adversarial testing - provides a practical path forward. With only 8% of organizations currently having comprehensive AI security plans, there’s a significant opportunity to close this gap.
"DevSecOps for ML is an evolving discipline that requires close collaboration between data scientists, DevOps, and security teams." - ConsensusLabs Admin
FAQs
Where do I start with DevSecMLOps if my team has no AI security plan yet?
Start embedding security measures at every point in your machine learning pipeline - right from data collection to the final deployment. Begin by evaluating your infrastructure for weak spots, such as risks of data poisoning or the possibility of model theft. To counter these, put safeguards in place, like data integrity checks and strict access controls.
Lay the groundwork with a risk assessment to identify potential threats. Promote awareness of security practices among your team, and as you progress, introduce automated checks and incident response protocols. These steps will help reinforce the security of your machine learning pipeline over time.
What are the most important security gates to include in an ML CI/CD pipeline?
Key security gates for an ML CI/CD pipeline include:
- Secrets management: Protects sensitive information like API keys and credentials from unauthorized access.
- Vulnerability scanning: Identifies weaknesses in code, dependencies, or environments to prevent exploitation.
- Model validation: Ensures models meet quality and security standards before deployment.
- Access control: Limits system access to authorized users, reducing the risk of breaches.
- Runtime anomaly detection: Monitors the pipeline for unusual behavior or inputs that could indicate threats.
These measures work together to defend against risks such as data poisoning, model theft, and adversarial inputs, helping maintain the pipeline's security and reliability.
How can I secure model files and prevent a tampered model from being deployed?
To keep model files safe and free from tampering, it's important to validate and verify artifacts to ensure their integrity. Strengthening your CI/CD infrastructure is another key step - it helps prevent unauthorized changes. Additionally, securing dependencies and keeping an eye out for any malicious activity is essential.
Some practical steps include:
- Signing model files: This ensures their authenticity and integrity.
- Using reproducible container images: These help maintain consistency and reduce risks.
- Enforcing access controls: Restricting access ensures only authorized individuals can make changes.
By following these practices, you can maintain trust and ensure that only secure models make it into production.