Domain Adaptation in Unsupervised Transfer Learning
Machine learning models often struggle when applied to data that differs from their training environment. This issue, called domain shift, leads to performance drops when models encounter new conditions, like different cities, hospitals, or marketplaces. Unsupervised Domain Adaptation (UDA) is a solution, allowing models trained on labeled data (source domain) to work effectively on unlabeled data (target domain) with different distributions.
Key Takeaways:
- Domain shift occurs when training and deployment data differ statistically, impacting model performance.
- UDA bridges this gap using methods like feature alignment, adversarial training, and pseudo-labeling.
- Challenges include handling large domain gaps, noisy pseudo-labels, and imbalances in class distributions.
- Popular benchmarks include datasets like Office-31 and DomainNet, with performance measured by accuracy and metrics like MMD and mIoU.
- Emerging trends focus on source-free methods, multi-source adaptation, and test-time adjustments.
UDA techniques are vital in fields like healthcare, autonomous vehicles, and e-commerce, where labeling new data is costly or impractical. The article explores UDA methods, limitations, and future directions, offering practical insights for researchers and practitioners.
Key Concepts and Problem Formulation
Domain Shift and Label Space Variations
Domain shift, also known as dataset or distribution shift, happens when the training data and deployment data differ statistically. Traditional machine learning assumes that training and test data follow the same distribution. However, Unsupervised Domain Adaptation (UDA) relaxes this assumption, acknowledging that while the source distribution (P) and target distribution (Q) are related, they are not identical (P ≠ Q).
Domain shift can take several forms. One common type is covariate shift, where the input distributions differ (P<sub>X</sub> ≠ Q<sub>X</sub>) but the labeling rules remain consistent. Another is label shift, where the label distributions differ (P<sub>Y</sub> ≠ Q<sub>Y</sub>) even though the underlying concepts are the same. A more complex scenario, Generalized Label Shift (GLS), combines both covariate and label shifts. Understanding these variations is crucial for crafting algorithms that can perform well across different domains.
Mathematical Setup for UDA
In UDA, the goal is to bridge the gap between a labeled source dataset and an unlabeled target dataset. Although the two datasets share the same label space, their distributions differ. The objective is to learn a hypothesis (h) from a hypothesis class (ℋ) that minimizes the true risk on the source domain:
ε<sub>P</sub>(h) = 𝔼<sub>P<sub>XY</sub></sub>[ℓ(h(X), Y)]
At the same time, the model must also generalize effectively to the target domain.
The challenge lies in the fact that minimizing risk on the source domain doesn’t automatically lead to low risk on the target domain. Researchers You-Wei Luo and Chuan-Xian Ren explain:
"The model trained on source domain (distribution) P with sufficient knowledge (e.g., annotations) is supposed to be unbiased on a related but different target domain (distribution) Q with less or no prior knowledge."
To address this, a common strategy is marginal alignment, which involves aligning the marginal feature distributions in a shared latent space (P<sub>Z</sub> = Q<sub>Z</sub>). However, this approach can fall short under label shift. In such cases, conditional alignment - matching class-level feature distributions (P<sub>Z|Y=y</sub> and Q<sub>Z|Y=y</sub>) - becomes necessary. Conditional alignment directly tackles the discrepancies caused by label shift, as Luo and Ren highlight:
"Marginal adaptation with P_Z = Q_Z is error-prone when label shift exists."
With these theoretical principles in place, benchmarks and evaluation metrics offer practical ways to measure UDA performance.
Benchmark Datasets and Evaluation Metrics
The challenges of domain adaptation are mirrored in commonly used benchmarks and metrics. For instance, Office-31 includes 31 object categories spanning three domains: Amazon product images, DSLR photos, and webcam shots. Another benchmark, DomainNet, introduced in 2019, contains approximately 600,000 images across 345 categories and six distinct visual styles.
| Dataset | Domains | Categories | Scale |
|---|---|---|---|
| Office-31 | 3 | 31 | ~4,100 images |
| DomainNet | 6 | 345 | ~600,000 images |
For image classification tasks, target domain classification accuracy is the main performance metric. For dense prediction tasks like semantic segmentation, mean Intersection over Union (mIoU) is used to evaluate how well predicted regions overlap with ground truth across different classes. Additionally, measures such as Maximum Mean Discrepancy (MMD), Jensen-Shannon (JS) divergence, and KL divergence are employed to quantify distributional differences, each offering a unique perspective on the extent of the shift.
sbb-itb-903b5f2
Empowering Unsupervised Domain Adaptation With Large-Scale Pre-Trained Vision-Language Models
Core Techniques in Unsupervised Domain Adaptation
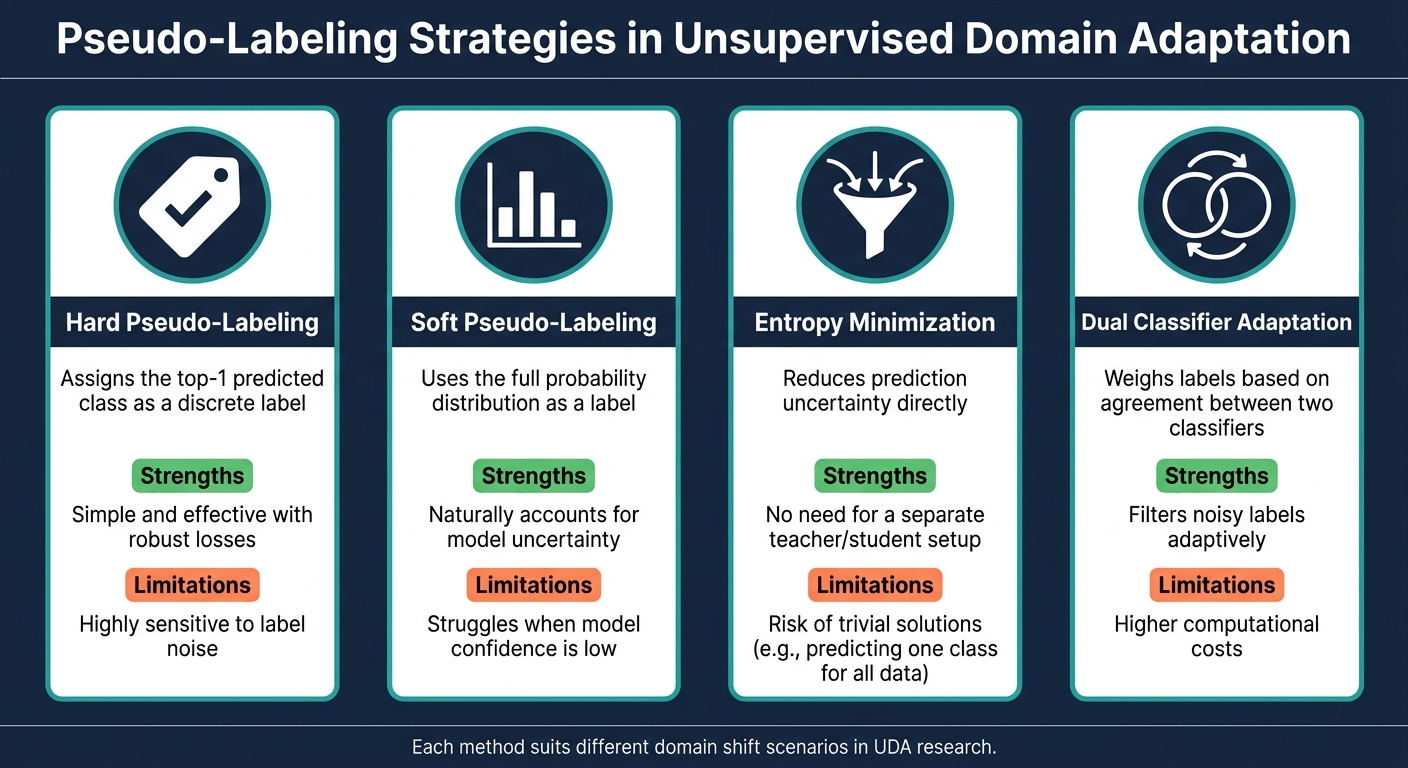
UDA Pseudo-Labeling Strategies: Methods, Strengths & Limitations
Let’s dive into the methods that help bridge the gap between source and target domains. These techniques generally fall into three main categories, each with its own approach and trade-offs.
Feature Alignment and Distribution Matching
One straightforward way to tackle unsupervised domain adaptation (UDA) is by reducing the statistical differences between source and target feature distributions. For instance, Maximum Mean Discrepancy (MMD) measures the difference between two distributions by comparing their mean embeddings in a reproducing kernel Hilbert space. By minimizing MMD, a model learns features that are statistically similar across domains - no target labels required.
A simpler alternative is CORAL (Correlation Alignment), which aligns the second-order statistics (like covariance) of source and target features, skipping the need to match full distributions. CORAL is computationally efficient and works well for visual tasks. Both MMD and CORAL aim to align feature spaces while preserving discriminative structures. However, these methods face challenges when label distributions differ significantly between domains. This is where adversarial techniques come into play with a more dynamic approach.
Adversarial Domain Adaptation
Adversarial methods treat domain adaptation as a two-player game. One player, the domain discriminator, tries to distinguish whether a feature comes from the source or target domain. The other player, the feature extractor, tries to "fool" the discriminator by creating features that look indistinguishable across domains. This approach, popularized by the Domain-Adversarial Neural Network (DANN) framework, encourages the model to learn domain-invariant features.
Adversarial training excels at capturing complex, non-linear differences that simpler methods like MMD and CORAL might miss. However, it’s not without challenges. Training can be unstable, and achieving class-level alignment is tricky. Sometimes, features from different classes across domains get mixed, which can hurt accuracy on the target side. To address these limitations, self-training methods introduce a new layer of adaptability using pseudo-labels.
Self-Training and Pseudo-Labeling
Self-training relies on generating pseudo-labels for unlabeled target data and then iteratively fine-tuning the model. This method becomes particularly important in Source-Free Unsupervised Domain Adaptation (SFUDA) scenarios, where the source dataset isn’t available - only a pre-trained source model can be used.
The main risk here is error amplification. When the domain shift is large, early pseudo-labels can be inaccurate, and training on these noisy labels can lead the model further astray. To combat this, researchers have developed practical solutions. For example, replacing standard cross-entropy loss with Generalized Cross Entropy (GCE) helps the model handle label noise better. Another approach uses dual-classifier structures, where a frozen source classifier and an evolving target classifier compare outputs. Labels agreed upon by both classifiers are treated as more reliable.
Here’s a quick comparison of common pseudo-labeling strategies:
| Method | Mechanism | Strengths | Limitations |
|---|---|---|---|
| Hard Pseudo-Labeling | Assigns the top-1 predicted class as a discrete label | Simple and effective with robust losses | Highly sensitive to label noise |
| Soft Pseudo-Labeling | Uses the full probability distribution as a label | Naturally accounts for model uncertainty | Struggles when model confidence is low |
| Entropy Minimization | Reduces prediction uncertainty directly | No need for a separate teacher/student setup | Risk of trivial solutions, like predicting one class for all data |
| Dual Classifier Adaptation | Weighs labels based on agreement between two classifiers | Filters noisy labels adaptively | Comes with higher computational costs |
Each of these methods has its strengths and trade-offs, making them suitable for different scenarios in domain adaptation.
Research Findings and Effectiveness Across Domains
Let’s dive into how unsupervised domain adaptation (UDA) techniques hold up when applied across various domain discrepancies.
Performance Across Different Domain Shifts
The success of UDA methods hinges on the size of the gap between the source and target domains. When this gap is relatively small, many UDA methods manage to adapt effectively. But as the differences between the source and target distributions grow, the adaptation process becomes far more difficult. Larger domain shifts bring unique challenges, sparking discussions about where these methods tend to falter and how they can be improved.
Common Failure Modes and Limitations
UDA research has uncovered some recurring problems. One major issue is the poor performance on minority classes, which often stems from unreliable pseudo-labels. When the source and target feature distributions overlap in unclear ways, these pseudo-labels can introduce errors that compound during training.
Another challenge lies in the separation of feature extraction and label propagation. Without a feedback loop between these processes, errors aren’t dynamically corrected. Additionally, constructing sample-level similarity graphs for label propagation can be computationally expensive, making it impractical for large datasets often encountered in real-world scenarios.
Practical Takeaways for Researchers
To tackle these issues, researchers have proposed several targeted solutions aimed at improving UDA methods:
- Prototypical Augmentation (ProAug): This approach strengthens performance on minority classes by augmenting the source domain with interpolated class prototypes.
- Class-Level Prototypical Graphs: Moving from sample-level to class-level graphs for label propagation addresses scalability issues and handles class imbalances more effectively.
- End-to-End Architectures: Integrating feature extraction and label propagation into a single training loop enhances robustness, particularly against noisy pseudo-labels and large domain discrepancies.
- Prototypical Contrastive Learning: By aligning domains at the class level, this method provides more stable and interpretable results.
These strategies represent promising steps forward, helping researchers address the limitations of UDA methods and adapt them to more complex scenarios.
Future Directions and Practical Tools
Emerging Trends in Domain Adaptation Research
The field of unsupervised domain adaptation (UDA) is advancing rapidly, with researchers focusing on a few exciting directions.
One area that's drawing significant attention is privacy-preserving adaptation. In many scenarios - like healthcare or proprietary industrial datasets - sharing raw source data isn't an option. This limitation has spurred interest in source-free methods. A standout example is SFGAR (Source-Free Graph foundation model Adaptation via pseudo-source Reconstruction). This approach uses a frozen Graph Neural Network (GNN) to create synthetic pseudo-source graphs, aligning them with unlabeled target data. The result? State-of-the-art performance on public benchmarks.
As Liang Yang and colleagues from Hebei University of Technology explain:
"Existing source-free UGDA methods remain limited by the absence of source data: deprived of source graphs, they lose the reference distribution needed to gauge domain shift and must lean on noisy target cues, incurring biased adaptation and catastrophic forgetting." - Liang Yang et al.
Beyond source-free methods, other trends are gaining momentum. Multi-source adaptation, which integrates knowledge from multiple source domains, and universal domain adaptation, which tackles unknown target categories, are both areas of active research. Additionally, test-time adaptation (TTA) offers a novel approach by dynamically adjusting the model during inference, rather than adapting it beforehand. These trends are shaping the future of UDA research and tools.
Using NanoGPT for Domain Adaptation Research
UDA research thrives on iterative experimentation - whether it's testing prompts, summarizing findings, or exploring new methods. Tools like NanoGPT are becoming invaluable in this process. NanoGPT provides access to various AI models, including ChatGPT, Gemini, and Deepseek, and operates on a pay-as-you-go model starting at $0.10. This flexibility allows researchers to experiment without committing to hefty upfront costs, making it easier to tackle diverse domain shifts.
For researchers working with sensitive target-domain data, NanoGPT's local data storage feature is a game-changer. By storing data directly on the user's device, it ensures privacy - a critical consideration in source-free settings where maintaining confidentiality is paramount.
Deployment Considerations for UDA Models
As these research trends evolve, deploying UDA models effectively becomes just as important. A key decision revolves around full fine-tuning versus feature extraction. Fully fine-tuning a model can deliver superior performance but comes with higher computational demands and the risk of catastrophic forgetting. On the flip side, feature extraction is faster and more cost-effective but might not fully bridge the domain gap.
The best approach often depends on your specific constraints, like dataset size, available computational resources, and the extent of domain shift. For many practical scenarios, starting with feature extraction and selectively fine-tuning the top layers strikes a good balance between accuracy and efficiency.
Conclusion and Key Takeaways
Key Insights from UDA Research
Unsupervised domain adaptation (UDA) tackles the challenge of aligning labeled source data with unlabeled target data through methods like feature alignment, adversarial training, and self-training. Each method addresses specific aspects of domain shift, but there’s no one-size-fits-all solution. One thing remains clear: as the gap between domains grows, more advanced techniques often become necessary.
How NanoGPT Supports Domain Adaptation Work
NanoGPT streamlines the process of fine-tuning pretrained GPT-2 models, requiring as few as 20 iterations. This represents a dramatic reduction in computational needs - up to 30,000× less - compared to starting from scratch. Additionally, NanoGPT's local data storage ensures sensitive target-domain datasets remain private, which is especially crucial in source-free adaptation scenarios.
What Comes Next
The field of domain adaptation is moving toward solutions that are both scalable and mindful of privacy. As these methods evolve, future UDA workflows will need to strike a balance between technical precision and data security to create dependable and effective pipelines.
FAQs
How can I tell if I’m dealing with covariate shift or label shift?
To spot covariate shift, look for changes in the distribution of input features while the connection between inputs and labels remains steady. This approach assumes that the features are the driving force behind the labels.
On the other hand, label shift occurs when the distribution of labels changes, but the distribution of features within each class (class-conditional features) stays constant. This scenario is common when labels are thought to affect features, such as when certain outcomes or conditions become more or less frequent over time.
When should I use feature alignment, adversarial training, or pseudo-labeling?
To tackle distribution gaps between source and target domains, you can use feature alignment techniques. This approach aligns features on a global scale, ensuring smoother transitions between domains.
Adversarial training is another method that helps create domain-invariant representations. While effective, it’s important to keep in mind that this approach might compromise some discriminative power, so balance is key.
For refining target domain data, pseudo-labeling is a solid choice. By labeling high-confidence samples, you can fine-tune the model on target data. However, it’s crucial to implement rigorous filtering processes to avoid introducing noisy labels that could derail the training process.
NanoGPT provides tools to support these strategies, offering pay-as-you-go AI models and secure local data storage to keep your data protected while adapting to your needs.
How can I reduce noisy pseudo-labels without target labels?
To cut down on noisy pseudo-labels during unsupervised transfer learning, focus on strategies that filter and refine data effectively. Start by using uncertainty estimation and adaptive selection to weed out ambiguous samples. This can be achieved by evaluating factors like cluster density or neighborhood consistency to ensure only reliable data is retained.
Techniques like prototype-based methods and curriculum learning are also useful. These approaches prioritize dependable samples first, gradually incorporating data that might be noisier over time. This step-by-step process helps maintain the quality of pseudo-labels.
For added accuracy, class-aware contrastive learning can be employed to maintain semantic consistency across labels. Finally, implementing a noise transition matrix can help tackle label confusion, ensuring the model learns from cleaner, more accurate data.