Dynamic Failover Strategies for AI Workloads
AI systems fail - it’s inevitable. Whether it’s an outage, rate limit, or performance drop, the key is ensuring your system can handle it. Failover strategies are critical for maintaining reliability, especially for production-grade AI applications. This article breaks down five key approaches to failover:
- Active-Passive: Cost-effective but slower recovery, with standby regions ready to take over during failures.
- Active-Active: High resilience with multiple regions active simultaneously, but more expensive.
- Predictive Failover: Uses AI monitoring and circuit breakers to identify and fix issues before they impact users.
- Kubernetes-Based: Centralized routing for containerized workloads, ideal for training jobs but complex to manage.
- Serverless: On-demand failover with minimal latency and cost, suitable for flexible inference workloads.
Each method offers trade-offs in latency, cost, scalability, and complexity. The right choice depends on your workload - whether it’s training, inference, or high-availability needs. Read on for a detailed comparison of these strategies.
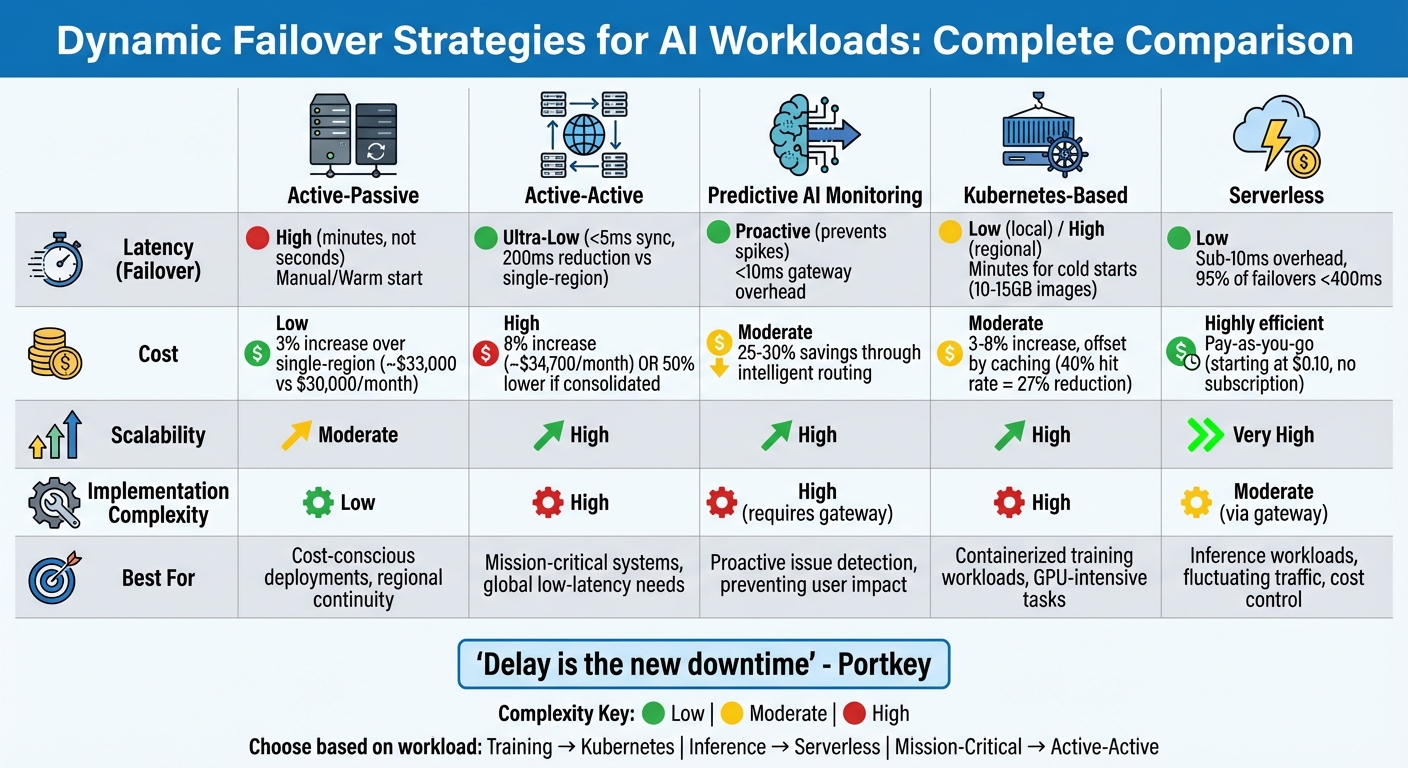
Comparison of 5 Dynamic Failover Strategies for AI Workloads
Understanding cloud-to-cloud failover for high availability (HA) | Dave Bermingham
sbb-itb-903b5f2
1. Active-Passive Failover
Active-passive failover is a straightforward and cost-friendly way to ensure your AI workloads stay operational in case of a regional issue. In this setup, your primary region manages all production traffic, while a secondary "standby" region remains warm - ready to take over if something goes wrong. When specific error codes like 429 (rate limit) or 503 (service unavailable) are detected, the system reroutes requests to the standby region immediately, bypassing prolonged retry cycles.
This approach is budget-conscious. Active-passive configurations typically add just 3% to your overall infrastructure costs compared to single-region setups. For example, if your AI API usage costs $30,000 per month, an active-passive failover setup would bring the total to around $33,000. This includes $800 for standby infrastructure and $200 for data replication. By contrast, active-active setups increase costs by 8% and come with added operational complexity.
"Active-passive is the right first DR design... often enough when the main requirement is continuity during a regional failure rather than global low latency." – Resilio Tech
Latency
Modern AI gateways are efficient, adding just 11 microseconds or less than 10ms to your request path. However, the failover process itself takes longer because the standby region needs time to scale up. Databases must warm up, caches need to populate, and GPU instances have to spin up to handle the sudden influx of traffic. This recovery typically takes minutes, not seconds. For applications like chatbots, aggressive timeout settings can help trigger failover quickly. For batch tasks, such as document processing, more relaxed timeouts may be appropriate.
These latency factors also tie into costs, as maintaining a warm standby region involves additional expenses.
Cost
Switching between providers - like OpenAI and Anthropic - can reduce failover delays to as little as 400ms. This method relies mainly on software logic, keeping infrastructure needs minimal. However, the real expense lies in keeping GPU capacity warm in your passive region. To handle a sudden 100% traffic shift, you'll need ample quota and autoscaling capabilities. Adding a caching layer can cut AI API costs by 40%, which often offsets the expense of maintaining a multi-region setup.
Scalability
One of the toughest challenges in scalability is synchronizing artifacts. Your passive region must have up-to-date model weights, prompt templates, and vector indexes. If you fail over to a region with outdated prompts or stale indexes, you risk creating a new problem instead of solving the original one. Regularly sending "smoke traffic" or synthetic tests to your standby region ensures that configurations are aligned and the system is ready to handle production traffic.
Implementation Complexity
Centralizing failover logic at the gateway level simplifies the process significantly. Instead of embedding failover mechanisms into every microservice, the gateway manages provider keys, format translations (e.g., converting OpenAI formats to Anthropic formats), and retry logic in a single layer. Some AI gateways even support up to 19 built-in providers for failover chains. Circuit breakers can also be integrated to temporarily remove underperforming providers from the routing pool for a cooldown period - usually about 30 seconds. A common failover strategy involves switching from a high-cost reasoning model like GPT-4o to a faster and cheaper alternative, such as Gemini Flash, when rate limits or budget constraints arise.
Next, we'll take a closer look at active-active configurations for even greater resilience.
2. Active-Active Failover
Active-active failover takes a different approach to traffic distribution by having multiple regions handle requests simultaneously. Instead of keeping a backup region idle, all regions are actively engaged in serving live requests. This setup ensures users connect to the nearest or fastest node, reducing latency by as much as 200ms compared to single-region deployments. Some teams even take it a step further with parallel request execution, where the same request is sent to multiple providers, and the system uses the first successful response.
"Delay is the new downtime." – Portkey
Let’s take a closer look at how active-active failover impacts latency, costs, scalability, and implementation complexity.
Latency
One of the key benefits of active-active failover is its ability to minimize latency. With immediate provider switching and geo-routing, users are automatically connected to the closest region - European users to Europe, U.S. users to the U.S., and so on. This setup ensures fast response times, especially for latency-sensitive applications like real-time assistants. Circuit breakers add another layer of reliability by quickly removing underperforming providers from the routing pool, preventing "latency cascades" that could impact the entire system.
Cost
Active-active configurations come with a modest increase in costs - around 8% more than single-region deployments. For instance, if a single-region setup costs $32,000 per month, an active-active setup might run about $34,700. This includes expenses like duplicate infrastructure across regions ($4,000), cross-region data transfer ($500), and global load balancing ($200). However, implementing a semantic caching layer can significantly reduce AI API costs - by as much as 40% to 60% - resulting in overall savings of 25% to 30%, even with the added infrastructure costs. Managed AI gateway platforms that handle failover logic can range from $2,000 to $50,000 per month, depending on usage volume.
Scalability
Scaling active-active setups introduces unique challenges, particularly around synchronization. For instance, if one region uses outdated prompt bundles or vector indexes, it can lead to a "correctness incident", even if the infrastructure itself seems fine. To avoid such issues, model weights, runtime images, and retrieval indexes must be pre-replicated across regions rather than updated during an outage. Rate limits can also be a bottleneck; OpenAI’s Tier 4 allows 2,000,000 tokens per minute, while Anthropic caps at 400,000 tokens per minute. To handle high-volume workloads, teams often rely on token bucket algorithms and multiple API keys.
Implementation Complexity
Active-active setups demand careful management of failure domains across regions. This includes ensuring consistent model-serving capacity and avoiding risks like vector database corruption. Synchronizing model versions, prompt bundles, and safety policies is critical, as any mismatch can result in degraded outputs. A provider abstraction layer - such as Portkey or Bifrost - can simplify these processes by enabling model swaps through configuration changes instead of code deployments. Circuit breakers also play a vital role, automatically removing providers when error rates exceed a set threshold (e.g., 5%). While these complexities do add to the workload, they are often worth it for the enhanced resilience and reliability active-active failover provides, as discussed further in the advantages and disadvantages section.
3. Predictive Failover with AI Monitoring
Predictive failover takes a proactive approach, aiming to address issues before they affect users. By combining AI monitoring with circuit breakers, it identifies potential problems - like error rates exceeding 5% or rising latency - and removes problematic providers from the routing pool automatically. This ensures users remain unaffected by service degradation.
"Circuit breakers are the proactive mechanism that retries and fallbacks alone cannot provide." – Maxim.ai
This method also avoids "retry storms", where repeated attempts overwhelm failing endpoints. Unlike traditional reactive failover, which can involve delays in detection and rerouting, predictive failover ensures transitions happen seamlessly, with no visible disruption for users.
Latency
The latency impact of AI gateways is minimal - typically less than 10ms for AI gateways and between 10–50ms for managed gateways. The real advantage lies in weighted load balancing, which adjusts traffic based on real-time performance data. Faster providers handle more traffic, while slower ones are deprioritized before they can cause issues. Circuit breakers enhance this further by entering a "half-open" state during recovery. This state sends limited test requests to a previously failing provider, ensuring it’s ready before resuming full traffic.
Cost
Managed gateways can reduce costs by 25–30% by automatically routing non-critical tasks to more affordable models. For example, intelligent routing might assign a budget-friendly model like DeepSeek-chat to handle less demanding requests. Setting up predictive failover can be time-intensive if done manually, often taking days or weeks due to the need for custom wrappers and centralized logging. In contrast, managed gateways simplify this process, allowing configuration in just minutes.
Implementation Complexity
Adding predictive capabilities builds on traditional failover mechanisms but introduces new challenges. These systems require proactive detection and distributed coordination to handle diverse error formats, rate limits, and latency variations across different LLM providers. For optimal reliability, you’ll need to combine three layers of protection: retries for transient issues, fallbacks for confirmed failures, and circuit breakers for prolonged outages. Scaling this setup involves managing circuit breaker states across multiple regions or instances, making distributed coordination essential.
"A failover system you cannot observe is a failover system you cannot improve".
Next, we’ll dive into Kubernetes-based failover, which leverages these proactive strategies to bolster system resilience even further.
4. Kubernetes-Based Failover
Kubernetes-based failover shifts routing control from the application code to a centralized gateway. This is achieved using YAML-configured priority groups that automatically switch from a primary model (like GPT-4o) to a secondary one (such as GPT-4-turbo) when errors occur. By building on earlier failover methods, Kubernetes offers a configuration-driven solution specifically designed for containerized AI workloads. Its declarative nature allows a single configuration to work across multiple services.
However, Kubernetes faces challenges when rescheduling pods that require specific GPUs and CUDA versions, which complicates failover processes. Sergey Kanzhelev from Google and Mrunal Patel from RedHat highlighted these limitations:
"Kubernetes lacks good support for handling full or partial hardware failures... The resource is either there or not".
These nuances significantly influence the performance, cost, and complexity of Kubernetes-based failover systems.
Latency
Large AI container images, often exceeding 10–15 GB, and the process of loading model weights can cause cold start delays lasting several minutes. Mélanie Dallé from Qovery elaborated on this issue:
"Loading a large language model into GPU memory takes minutes. A RollingUpdate that kills an inference pod forces the replacement to repeat the full loading sequence, causing severe latency spikes".
For large-scale training jobs, in-place restarts - where resources are reused instead of being rescheduled - can help reduce this overhead. Once operational, high-performance gateways add minimal latency, typically between 10–50 ms, compared to the response times of large language models, which range from 500 ms to 5 seconds.
Cost
Deploying Kubernetes across multiple regions increases infrastructure expenses by 3–8%, but strategies like semantic caching and Spot VMs can help offset these costs. For instance, with a 40% cache hit rate, an active-active setup that would typically cost $34,700 per month can drop to $23,500 - a 27% reduction from a $32,000 baseline. Additionally, using tools like GKE Flex-start and Spot VMs can provide up to 53% discounts on GPU and TPU costs.
GPU nodes, which are significantly more expensive than CPU nodes, make idle time during failover recovery particularly costly. NVIDIA’s self-healing infrastructure, for example, handles about 19 remediation requests per 1,000 nodes daily to address such inefficiencies. Beyond financial considerations, the challenges of deploying and managing Kubernetes add another layer of complexity to these failover strategies.
Implementation Complexity
Setting up Kubernetes-based failover involves deploying specialized AI gateways and configuring Custom Resource Definitions (CRDs) like Backend or AgentgatewayBackend. Models are categorized into priority tiers - primary, fallback, and emergency - ensuring requests are directed to the most reliable option available. However, current tools often only trigger failover on 429 rate-limit errors, potentially missing issues like 503 errors, timeouts, or DNS failures.
Centralized management simplifies this process. As Pranay Batta explained:
"The actual fix: route requests through a gateway that automatically fails over to a backup provider when the primary goes down. Your app sends requests to one endpoint. The gateway handles the rest".
To ensure pods are deployed on nodes with compatible hardware and drivers, careful configuration of nodeSelector labels, taints, and tolerations is crucial. These elements underline the importance of precise setup in achieving effective Kubernetes-based failover. Next, we’ll examine the broader pros and cons of these strategies.
5. Serverless Failover
Serverless failover treats AI providers like interchangeable backends, allowing them to be swapped through configuration changes. Instead of maintaining standby clusters, this method routes requests via a gateway that detects failures and redirects traffic to backup providers. By combining the capacity of multiple LLM providers, it avoids hitting any single vendor's rate limits. Below, we’ll explore how serverless failover impacts latency, cost, scalability, and complexity.
In April 2026, Fordel Studios implemented a multi-provider serverless failover system across three client projects over four months. Led by Head of Engineering Abhishek Sharma, the team used the Vercel AI SDK to build a routing layer in under 200 lines of TypeScript. The result? Zero user-facing outages despite provider rate limits. Impressively, 95% of failover events completed in under 400 ms, with the longest delay being only 1.2 seconds. As Sharma explained:
"The goal is not zero failovers. The goal is that failovers are invisible to your users."
This approach is distinct from Kubernetes-based failover, as it eliminates the need for container orchestration or manual pod rescheduling. Instead, serverless functions dynamically handle routing logic, switching to backup providers when encountering 429 rate-limit errors or timeouts. AI gateways add less than 10 ms of routing overhead, compared to the 10–50 ms typical of other solutions - an insignificant delay given LLM response times of 500 ms to 5 seconds.
Latency
When configured properly, serverless failover introduces minimal latency. Modern gateways often add less than 10 ms to processing time, and semantic caching can reduce delays further by bypassing the LLM provider for repeated or similar queries. Circuit breakers temporarily remove degraded providers from the rotation, ensuring smoother operations.
Failover strategies often switch from slower, high-reasoning models to faster alternatives during performance dips. Kuldeep Paul from Agentic Systems highlighted this necessity:
"A system that is 'up' but takes 30 seconds to respond is functionally broken for many use cases."
Aggressive timeouts - typically around 10 seconds per attempt - help prevent single hanging requests from exhausting worker pools. For streaming responses, reading the first chunk before committing to a provider can help catch infrastructure failures early. Additionally, latency-based routing prioritizes faster providers by tracking time-to-first-token metrics.
Cost
Serverless failover avoids the steep subscription fees of managed gateway platforms, which can range from $2,000 to $50,000 per month. DIY serverless setups, on the other hand, incur only API key and minimal compute costs. However, switching to a secondary provider during an outage might increase costs by up to 3× if the backup model is significantly more expensive.
Cost-aware routing helps manage this by dividing workloads into tiers like Critical, Standard, and Bulk. For example, simpler tasks can use mid-tier models costing around $0.15 per million tokens, while complex tasks are routed to premium models priced at about $15 per million tokens. Managed gateways claim to save 25–30% on costs through automated rate-limit management, but DIY setups offer better data privacy since no third party handles the prompts.
Scalability
Serverless failover ensures continuity during demand spikes by pooling capacity from multiple LLM providers, effectively bypassing individual vendor rate limits. Systems automatically detect 429 errors and reroute traffic to backup providers, ensuring uninterrupted service. Between November 2025 and February 2026, ChatGPT maintained approximately 98.71% uptime, highlighting the importance of multi-provider failover for achieving 99.9% availability in production systems.
Circuit breakers protect infrastructure by temporarily removing degraded providers from the routing pool, preventing "retry storms". OpenAI-compatible gateways allow teams to switch models with simple configuration changes rather than extensive code rewrites, making scaling faster and more efficient. Tools like Amazon Bedrock’s cross-region inference profiles also allow traffic routing between regions (e.g., US-East to US-West) to handle unexpected demand without manual intervention.
Implementation Complexity
Unlike Kubernetes-based solutions, serverless failover simplifies routing by removing the need for container orchestration. Managed gateways can be set up in minutes with an API key swap, while DIY implementations might take days or weeks but offer greater control. The core logic involves wrapping provider calls with retry mechanisms, using exponential backoff and jitter to avoid "retry storms" during temporary failures.
To ensure seamless failovers, prompts should be provider-neutral. This prevents issues like context loss or hallucinations when switching between model families, such as GPT-4 and Claude 3.5. Token bucket patterns can limit retries during overloads, allowing recovery attempts only when success is likely. LLMAPI.ai summed it up well:
"Your users won't care that 'it's OpenAI' or 'it's Anthropic' or 'it's Google.' To them, it's your app that broke."
Diversity in infrastructure is also key. For example, avoid fallback providers hosted in the same AWS region to reduce the risk of shared failures. A tiered model strategy works best: a high-quality primary model, a similarly capable secondary, and an affordable "basic mode" emergency model that’s widely available.
Advantages and Disadvantages
This section pulls together key takeaways from earlier discussions, highlighting the strengths and limitations of each failover strategy. Each approach comes with its own set of trade-offs, balancing cost, speed, scalability, and complexity.
Active-Passive setups are budget-friendly since you only pay for backup resources if the primary system fails. However, recovery can be slow, often involving manual steps or delays due to warm starts. On the other hand, Active-Active configurations offer lightning-fast failover, with synchronization times under 5 milliseconds in high-performance systems like Cisco's stretched database clusters. The downside? Maintaining parallel infrastructure can be costly unless consolidated into a single logical cluster, which has been shown to reduce costs by up to 50% per quarter.
Predictive AI Monitoring, equipped with circuit breakers, can proactively remove underperforming providers before they affect overall system performance. While this approach adds a layer of complexity with the need for a gateway, the routing overhead is minimal compared to typical response time requirements. Kubernetes-Based failover handles local failures efficiently but struggles with cross-region failover, often requiring manual intervention - making it less ideal for workloads spread across multiple regions.
Serverless failover stands out for its scalability and cost-effectiveness. Pay-as-you-go models, like NanoGPT's starting at just $0.10 with no subscription fees, eliminate the need to maintain idle backup systems. This approach simplifies administration while maintaining stable margins even if provider prices fluctuate. However, switching from a low-cost provider to a premium one during an outage can lead to sharp cost increases.
The table below breaks down these strategies across key dimensions like latency, cost, scalability, and complexity, summarizing their trade-offs.
| Strategy | Latency (Failover) | Cost | Scalability | Implementation Complexity |
|---|---|---|---|---|
| Active-Passive | High (Manual/Warm start) | Low (pay only on use) | Moderate | Low |
| Active-Active | Ultra-Low (<5ms sync) | High (or 50% lower if "Stretched") | High | High |
| Predictive AI | Proactive (Prevents spikes) | Moderate | High | High (Requires Gateway) |
| Kubernetes | Low (Local) / High (Regional) | Moderate | High | High |
| Serverless | Low (Sub-10ms overhead) | Highly efficient (Pay-as-you-go) | Very High | Moderate (via Gateway) |
"Delay is the new downtime. A chatbot that takes 6–8 seconds to respond feels broken, even if the API technically succeeded".
To maintain user trust, it's critical to set strict latency thresholds - usually between 2 and 3 seconds - and treat slow responses as system failures. For teams focused on cost and flexibility, serverless failover with unified gateways strikes a solid balance. Meanwhile, Active-Active architectures remain the go-to choice for mission-critical systems .
Conclusion
Choosing the right failover strategy depends on the specific needs of your workload and operational priorities. For training workloads that demand consistent high-performance GPU resources, Kubernetes-based failover is a solid choice. It ensures uninterrupted compute power while minimizing data loss through the use of persistent volumes.
For inference workloads with fluctuating traffic patterns, serverless failover stands out. It offers auto-scaling and redundancy without the hassle of managing infrastructure. Plus, it delivers failover times in under a second while keeping costs tied directly to usage.
For predictive failover, tools like Prometheus and anomaly detection can help monitor GPU usage, memory leaks, and model drift. Set alerts at around 80% utilization and configure auto-scaling policies to initiate failover after two consecutive failures. Validate these setups with chaos engineering to keep false alarms under 1%. In Kubernetes environments, leverage the Horizontal Pod Autoscaler (aiming for about 70% CPU/GPU usage), deploy StatefulSets to ensure training persistence, and use Pod Disruption Budgets to maintain at least two replicas.
Cost management is another key factor during failover. NanoGPT makes inference more affordable by offering pay-as-you-go access to models like ChatGPT, Gemini, and Stable Diffusion for as little as $0.10, with no subscription fees. This approach eliminates idle backup costs while providing on-demand scalability during traffic spikes, making it a great complement to serverless failover strategies.
Ultimately, aligning your failover strategy with your workload's specific demands is crucial. For mission-critical systems where downtime is unacceptable, active-active architectures can justify their higher price tag. On the other hand, if flexibility and cost control are your priorities, serverless architectures deliver strong results. Regularly test your setup, monitor performance closely, and consider hybrid strategies - such as combining Kubernetes orchestration with serverless scaling - for the best outcomes.
FAQs
Which failover strategy is best for training vs. inference?
For training, strategies such as redundancy and high availability play a crucial role in keeping resources accessible, reducing downtime, and safeguarding data integrity during unexpected disruptions. Common techniques include multi-region deployments and intelligent failover mechanisms, which distribute workloads and ensure smooth operations even during outages.
When it comes to inference, dynamic failover methods are key to maintaining real-time reliability. Techniques like load balancing, retries, circuit breakers, and fallback chains help reroute requests in case of failures, ensuring uninterrupted user experiences. The specific approach often depends on the unique requirements of the workload.
How do I pick failover timeouts and circuit breaker thresholds?
Set failover timeouts that quickly identify unresponsive providers. This ensures the system can switch to backup options before users notice any disruption. For example, configure timeouts to be just a few seconds longer than the usual response times for your service. This strikes a balance between giving providers enough time to respond and avoiding unnecessary delays.
Circuit breaker thresholds are equally important. These thresholds track failure rates and stop sending requests to a provider when failures exceed acceptable levels. To get this right, monitor failure rates over a rolling window and adjust the thresholds as needed based on real-time operational data. This approach helps maintain a smooth user experience while minimizing downtime.
How do I keep prompts, models, and vector indexes in sync across regions?
When managing multi-region AI systems, it's crucial to have disaster recovery and synchronization strategies in place. Here's how to keep everything running smoothly:
- Treat Components as Separate Failure Domains: Handle prompts, models, and vector indexes independently. This approach ensures that an issue in one domain doesn’t cascade into others.
- Define RTO and RPO: Establish clear Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). These benchmarks help measure how quickly systems need to recover and how much data loss is acceptable during failures.
- Automate Updates: Use automated processes to streamline updates across regions. This reduces manual errors and ensures consistency.
- Enable Real-Time Synchronization: Implement real-time or near-real-time synchronization to keep data consistent across regions. This is critical for avoiding issues like data staleness during unexpected outages.
- Ensure Seamless Failover: Design systems to switch automatically to backup regions in case of a failure. This minimizes downtime and prevents data inconsistencies.
By addressing these elements, you can build a resilient system capable of handling disruptions without compromising performance or data integrity.