How Dynamic Partitioning Optimizes AI Model Updates
Dynamic partitioning is reshaping how AI models update and function. By splitting tasks between local devices and servers based on real-time factors like network speed, battery life, and privacy, it ensures better performance and resource use. Unlike static methods, this approach adjusts as conditions change, solving issues like high latency and wasted energy. Here's what you need to know:
- What It Does: Splits AI models dynamically between devices and servers to improve efficiency.
- Why It Matters: Reduces latency, saves energy, and protects privacy, especially in unstable networks like 5G.
- How It Works: Uses tools like runtime reconfiguration and AI-driven policies to adjust split points in real-time.
- Key Benefits: Faster updates, lower costs, and better resource allocation for platforms like NanoGPT.
Dynamic partitioning is becoming essential for AI systems, especially those managing multiple models or operating in fluctuating environments.
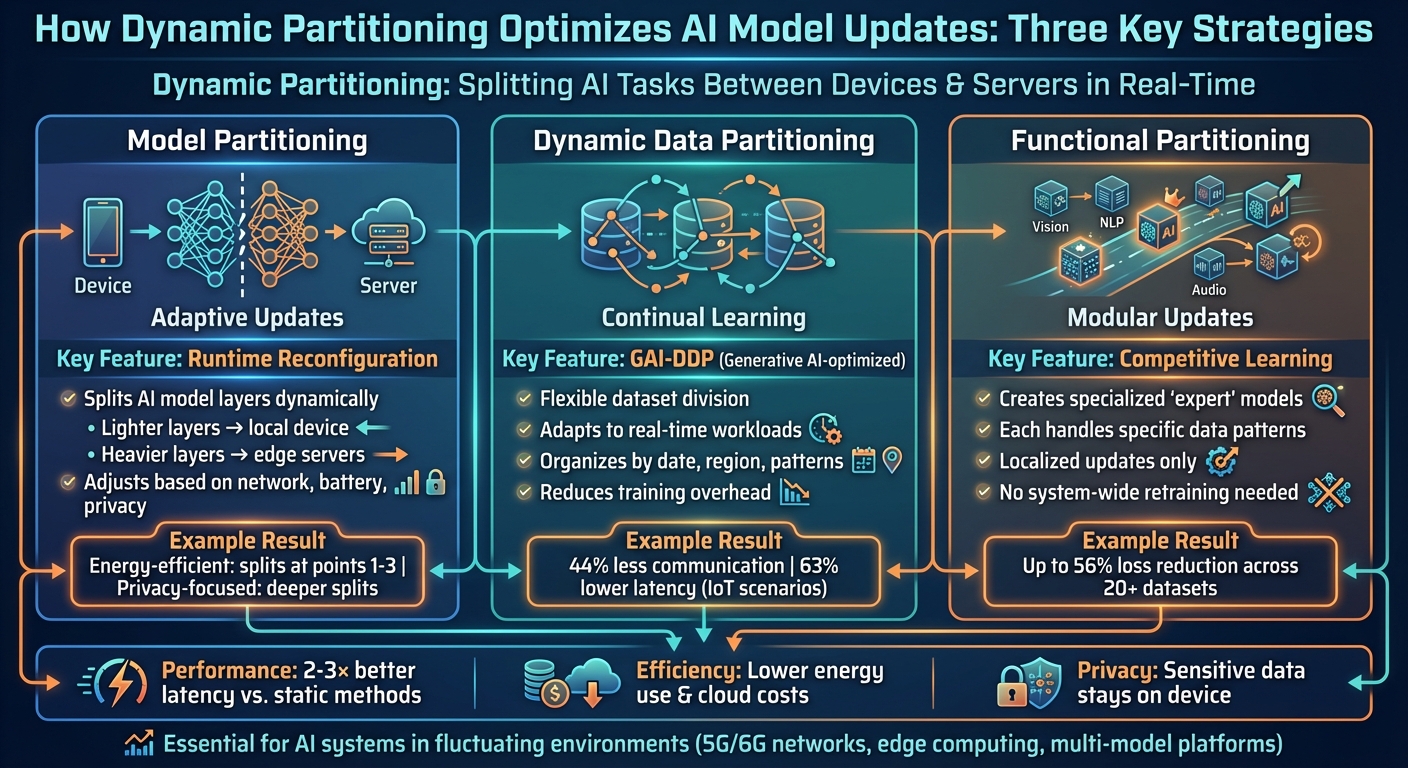
How Dynamic Partitioning Works: Three Key Strategies for AI Model Optimization
Key Strategies for Dynamic Partitioning
Model Partitioning for Adaptive Updates
Model partitioning involves dividing AI models into segments that can run sequentially across various devices. For instance, lighter layers might process locally, while heavier layers are handled on edge servers. The standout feature here is runtime reconfiguration, which adjusts these split points based on factors like network performance, device capacity, and privacy demands.
In a 2025 evaluation using AI-RAN with the NVIDIA Aerial 5G stack, adaptive partitioning fine-tuned the division of deep neural networks (DNNs) for image processing. The goal? To balance latency, energy consumption, and privacy under fluctuating throughput conditions. For example, energy-efficient strategies opted for earlier splits (points 1–3) to minimize device power usage, while privacy-focused setups pushed splits deeper into the model. Modern systems now use an Adaptive Orchestrator to dynamically manage these splits, redistribute workloads, or even adjust the model division as conditions shift.
This leads us to the next step: refining how data is handled with dynamic partitioning.
Dynamic Data Partitioning for Continual Learning
Dynamic data partitioning takes a flexible approach to dividing datasets, adapting to real-time workloads. Instead of sticking to fixed data shards, systems employ Generative AI–optimized partitioning (GAI-DDP) to create shard distributions optimized for parallel processing. These systems analyze access patterns and adjust partitions on the fly - organizing data by factors like date or region to better align with query trends in cloud environments.
This method streamlines incremental updates by avoiding the need to scan entire datasets. By dynamically adjusting shards, training overhead is reduced, and updates become more efficient. For example, in IoT scenarios, using dynamic region partitioning in distributed consensus algorithms cut communication frequency by 44% and slashed transaction latency by 63%.
Building on this concept, functional partitioning takes modularity to the next level.
Functional Partitioning for Modular AI Updates
Functional partitioning breaks datasets into specialized segments based on distinct functional patterns. This is achieved through competitive learning techniques, where multiple models compete to predict each data point. The best-performing model trains on that specific point, creating "expert" models tailored to specific functional regimes. Boundaries between these regimes are defined using support vector mechanisms.
This modular design enables localized updates, meaning individual expert models can be retrained without impacting the entire system. Tests on over 20 regression datasets demonstrated that competitive learning effectively partitioned data for modular experts, reducing loss by up to 56%. Platforms like NanoGPT benefit significantly from this approach, as it allows for efficient, targeted updates while maintaining privacy. By focusing on specific capabilities, this method ensures that updates are both precise and resource-efficient - a critical advantage for systems managing multiple AI models.
How Dynamic Partitioning Drives Optimization
Adaptive Split Inference
Adaptive split inference is all about how AI models decide to divide their workload between local devices and remote servers. It relies on an adaptive orchestrator that continuously evaluates three options: stick with the current setup, redistribute segments to underused nodes, or completely reconfigure the partitioning based on current conditions.
Here's how it works: the system dynamically adjusts splitting points based on network conditions. For example, when bandwidth is sufficient, deeper splits are used to enhance privacy. On the flip side, when conserving energy is the priority, earlier splits come into play. The orchestrator constantly monitors conditions and updates configurations across all nodes, ensuring the system adapts in real time. This approach consistently outperforms static setups, delivering better end-to-end latency and improved energy efficiency, even across varying throughput levels.
This constant monitoring naturally sets the stage for more precise adjustments, which is where dynamic reallocation and resplitting come into play.
Dynamic Reallocation and Resplitting
Dynamic reallocation involves shifting existing partition segments between nodes to balance workloads incrementally. When there are significant changes - like new privacy demands or major shifts in resources - full resplitting recalculates the optimal partition boundaries. This ensures the system stays efficient, even as real-time updates to AI models roll out.
The system treats partitioning as a dynamic variable, solving a constrained optimization problem that minimizes both latency and resource costs. By periodically recalculating these boundaries, it can handle changes in model weights and updates effortlessly. Integrating this approach into platforms like Kubernetes is possible through custom controllers, with reinforcement learning fine-tuning strategies over time.
Generative AI-Driven Partitioning Policies
To take things a step further, AI-driven policies refine partitioning decisions by predicting workload patterns. For instance, GAI-DDP uses these predictions to automatically adjust how data shards are distributed across processing nodes. By analyzing access patterns, these policies dynamically organize data to align with actual usage trends.
These AI-driven strategies work hand-in-hand with adaptive split inference, offering a learning-based method for partitioning decisions. This allows systems to adapt to infrastructure changes while balancing computational loads effectively. The result? Smarter resource use and faster updates - especially useful for platforms juggling multiple AI models, where maintaining both performance and privacy is key.
Measured Benefits of Dynamic Partitioning
Latency and Efficiency Gains
Dynamic partitioning significantly cuts down on end-to-end latency and energy use by adjusting split points in response to real-time network conditions. Systems designed to balance latency, privacy, and energy consumption have shown performance gains of up to 2–3× compared to fixed configurations.
Research into automated deep neural network (DNN) partitioning frameworks reveals that static splits can lead to 2–3× higher latency under realistic conditions. By actively monitoring throughput and dynamically adjusting partition boundaries, these systems ensure stable response times - even when bandwidth drops or device resources shift unexpectedly.
These enhancements open the door to modular performance improvements, as explored in the next section.
Improved Model Performance Through Modular Updates
Dynamic partitioning also boosts model performance by dividing datasets into specialized sections, each managed by expert models. For example, a competitive-learning-based approach tested across more than 20 regression benchmarks achieved loss reductions of up to 56% when using modular experts for specific partitions instead of relying on a single monolithic model.
This approach is particularly effective for datasets with distinct behavioral patterns. By allowing each expert model to focus on the data it handles best, the system achieves better generalization compared to global models. Additionally, modular updates make it possible to retrain only the affected partitions, cutting costs and avoiding disruptions to the rest of the system.
Examples of Real-Time Updates in Practice
The practical advantages of dynamic partitioning are evident in real-world implementations. For instance, in federated and edge-learning systems, dynamic partitioning enables frequent, low-overhead updates. A federated learning setup combined with blockchain technology implemented an improved PBFT consensus algorithm that leveraged dynamic region partitioning. This reduced communication frequency by 44% and slashed transaction latency by 63% compared to traditional single-layer approaches. Even with differential privacy measures in place, the system maintained high efficiency, with only a 3.5% dip in data transmission accuracy.
In edge AI applications like real-time video analytics, selecting partition points based on device capabilities and network conditions leads to tangible benefits. For example, camera devices can offload compute-heavy layers to edge servers equipped with powerful GPUs while keeping simpler layers local. This setup results in higher frames-per-second processing rates and lower energy consumption. Such optimizations are particularly useful in U.S.-based deployments for traffic monitoring, industrial inspections, and mobile applications, where consistent performance is critical.
sbb-itb-903b5f2
Design Implications for AI Platforms like NanoGPT

Runtime Partition Management
Managing dynamic partitioning of AI model components requires a robust runtime stack. This includes a partition-aware model loader, a telemetry monitor, and an adaptive orchestrator. The telemetry monitor keeps tabs on essential metrics like latency, GPU/CPU usage, memory pressure, and bandwidth, helping to create detailed capacity profiles. Meanwhile, the adaptive orchestrator acts as the decision-maker, determining whether to maintain the current model split, redistribute parts to other nodes, or entirely re-partition based on resource constraints and quality-of-service needs. This approach builds on earlier methods like adaptive split inference and dynamic reallocation.
For NanoGPT, which offers access to over 400 AI models - including GPT 5, Claude, Gemini, and Grok - these features could be implemented as a lightweight local agent on the user's device. This agent would work alongside a global orchestrator in the cloud, communicating through low-latency protocols to handle partition adjustments for each request or session. By extending NanoGPT's "Auto Model" feature, this system could intelligently distribute workloads between local and remote resources, ensuring a seamless and efficient user experience.
Balancing Local and Remote Resources
Dynamic partitioning also plays a key role in optimizing how tasks are divided between on-device processing and cloud execution. For platforms like NanoGPT, this means adopting strategies like partial weight residency - storing smaller, lighter components (like prefix layers or adapters) locally while keeping deeper, more complex layers in the cloud. This setup is especially useful for U.S. users with resource-limited devices, such as older laptops or smartphones, where downloading massive models isn't feasible.
To make this work, NanoGPT can use on-demand weight streaming, caching commonly used model components locally and fetching specialized ones only when needed. For instance, if a user experiences Wi‑Fi congestion, the orchestrator could shift more processing to the device, reducing data transfer while maintaining performance. Similarly, commuters relying on cellular data could benefit from prefetched layers during periods of strong signal strength, allowing for smooth local execution when connectivity weakens.
Ensuring Privacy and Efficiency
NanoGPT's dynamic partitioning aligns seamlessly with its commitment to privacy. The platform ensures that sensitive data - like raw text, images, or personally identifiable information - is processed exclusively on the user's device. Only higher-level, abstract representations are sent to the cloud, minimizing the risk of re-identification. This approach supports NanoGPT's privacy-first promise, where conversations are saved locally, and providers are instructed not to use user data for training.
For tasks requiring heightened privacy, such as medical consultations or legal reviews, NanoGPT enforces full local execution. By splitting workloads between the CPU and GPU, it eliminates the need for remote data flow entirely. In cases where remote execution is unavoidable, only encrypted, temporary intermediate activations are transmitted. This design meets stricter U.S. privacy expectations while still leveraging the power of remote GPUs for demanding computations.
Conclusion and Future Directions
Key Takeaways
Dynamic partitioning transforms static deployments into a flexible, real-time optimization process. This approach reduces latency, conserves energy, and maximizes hardware usage across both edge and cloud environments. For platforms like NanoGPT, which manage hundreds of models, it allows modular updates to be applied locally, minimizing maintenance windows without interrupting services. On top of that, dynamic partitioning enhances privacy and compliance by shifting sensitive tasks to local devices when necessary, while still utilizing remote GPUs for more resource-intensive computations.
Adaptive split inference frameworks further push the boundaries by dynamically adjusting partition points based on real-time bandwidth and node usage. Unlike static splits, these frameworks maintain quality-of-service targets, reducing cloud infrastructure costs and improving the cost-per-1,000 inferences for pay-as-you-go systems. Together, these strategies deliver operational efficiencies, showcasing how partition-aware protocols can improve scalability and responsiveness in real time.
These advancements set the stage for future research to refine and expand these methods even further.
Future Research Opportunities
While current strategies have demonstrated measurable benefits, hybrid approaches could unlock even greater potential. Future research should focus on combining model splits, data sharding, and functional specialization into unified optimization strategies. Instead of addressing these dimensions in isolation, future systems could employ reinforcement learning or generative AI to balance latency, cost, privacy, and environmental impact simultaneously. Generative models, for instance, could simulate partition changes to predict their effects before implementation.
As discussed earlier, adaptive split inference and dynamic reallocation have already proven effective. For platforms managing multiple models, future work should address cross-hardware heterogeneity by designing partitions that adapt in real time across GPUs, CPUs, NPUs, and mobile accelerators with varying memory and bandwidth capacities. This also includes creating auditable partitioning systems that log critical details - such as device type, location, and timestamp - to meet U.S. data-handling regulations and industry-specific privacy standards. With the continued rollout of 5G and the emergence of 6G networks, dynamic partitioning will play a pivotal role in maintaining low latency, controlling cloud expenses, and protecting local privacy under fluctuating bandwidth conditions.
That said, challenges remain. Continuous telemetry and frequent re-splitting can strain CPUs and consume significant bandwidth, underscoring the need for lightweight performance models and optimized control-loop cycles. Additionally, as model sizes grow, the number of possible partition and placement configurations expands exponentially, requiring scalable solutions that go beyond manual adjustments. Overcoming these hurdles will be essential for unlocking the full potential of dynamic partitioning in real-time AI systems. Whether it’s consumer-facing tools like chatbots and image generators or enterprise analytics platforms, these systems must adapt to ever-changing traffic patterns and compliance demands.
AI-Driven Spectrum Sensing for Dynamic & Privacy-preserving AI Model Partitioning over 5G Network
FAQs
How does dynamic partitioning improve privacy in AI models?
Dynamic partitioning takes privacy to the next level by dividing data into smaller, more manageable chunks. This reduces the risk of exposing sensitive information during updates while ensuring that all data stays securely on the user's device. It's a method that perfectly complements NanoGPT's commitment to protecting user privacy and maintaining strong data security.
What advantages does dynamic partitioning offer compared to static methods?
Dynamic partitioning brings several notable benefits compared to static methods. It boosts efficiency by allowing AI models to update in real time, keeping them responsive to shifting data patterns and workload demands. This method also makes better use of resources, ensuring computational power is directed where it's needed most. On top of that, dynamic partitioning enhances scalability, making it easier to manage increasing or unpredictable demands while maintaining strong performance.
By tapping into these advantages, AI models can adjust more seamlessly to changing needs, resulting in improved functionality and smoother operations.
How does dynamic partitioning improve the energy efficiency of AI models?
Dynamic partitioning improves energy efficiency by cutting down on unnecessary computations and smartly distributing resources during real-time AI model updates. This approach helps lower power usage while maintaining smooth and consistent performance.
By simplifying processes and directing system resources to where they’re needed most, dynamic partitioning not only reduces energy consumption but also enables quicker and more efficient updates, ensuring AI models remain dependable even in high-pressure scenarios.