Dynamic Resource Allocation with AI: How It Works
Dynamic resource allocation powered by AI transforms how edge devices manage limited resources like CPU, memory, and energy. Unlike static methods, AI predicts workload spikes and adjusts resources in real time, ensuring smoother operations and preventing crashes. With global data volumes surging and 5G enabling dense device networks, manual management is no longer practical.
Key takeaways:
- AI predicts workload patterns, avoiding bottlenecks before they occur.
- Real-time adjustments optimize CPU, memory, and energy use, enhancing performance.
- Reinforcement learning models, like NEC’s "DataX Allocator", improve processing rates by up to 2.5x.
- Task offloading between edge and cloud ensures low latency and efficient resource use.
AI-driven systems are essential for managing the complex demands of edge environments, enabling efficient, reliable, and scalable operations.
Unleashing the Power of DRA (Dynamic Resource Allocation) for Just-in-Time GPU Slicing
sbb-itb-903b5f2
Resource Allocation Challenges in Edge Environments
Understanding the limitations of resources in edge environments highlights why AI-driven dynamic allocation is becoming increasingly important.
Resource Constraints in Edge Devices
Edge devices operate with far fewer resources - whether it's CPU, GPU, RAM, or storage - compared to centralized cloud servers. For battery-powered devices, the challenge is even greater as they must balance performance with energy efficiency, limiting both the intensity and duration of their processing tasks. Take, for example, a smartphone running AI-powered augmented reality or an industrial gateway analyzing sensor data. These devices simply cannot compete with the computational power of a data center.
Advanced applications like Generative AI further stretch these limitations. Researchers Partha Pratim Ray and Mohan Pratap Pradhan at Sikkim University explored this in August 2025 by testing quantized Large Language Models on edge devices via their DLUSEdge framework. Their work with models such as qwen2.5:0.5b-instruct demonstrated how careful memory scheduling could achieve task latencies as low as 1.97 seconds and switching latencies of 2.25 seconds. The wide variety of edge hardware - from smartphones to micro data centers - adds another layer of complexity to managing resources uniformly.
Variable and Unpredictable Workloads
Fluctuating workloads pose another significant hurdle. Allocating too many resources during low-demand periods wastes energy, while under-allocating during demand spikes leads to performance bottlenecks. For instance, agricultural IoT sensors might send consistent data streams most of the time, only to overwhelm the network during sudden weather events.
In March 2025, Saroj Mali (Central South University) and Inam Ullah (Gachon University) tackled this issue in agriculture using a Federated Reinforcement Learning framework powered by a Deep Deterministic Policy Gradient (D4PG) algorithm. Their system, tested on crop prediction datasets, achieved an impressive 92.86% accuracy and an F1-score of 0.9192 on non-uniformly distributed data. This approach helped stabilize power consumption across edge servers, even in the face of unpredictable sensor inputs. Such variability underscores the importance of flexible and adaptive resource management.
Latency and Quality of Service Requirements
One of the fundamental goals of edge computing is to minimize latency by processing data closer to its source. This is especially critical for applications like autonomous vehicles, telemedicine, and industrial control systems. Rafael Moreno-Vozmediano from Complutense University of Madrid highlights the risks of inadequate resource provisioning:
Under-provisioning causes insufficient resources to process service workload requirements, resulting in degraded service quality, data loss, or even service failure.
The challenge grows even more complex with 5G networks, which are designed to support up to one million devices per square kilometer. Managing resources effectively requires real-time decision-making to avoid temporary shortages that could disrupt latency-sensitive tasks. AI-based resource allocation becomes indispensable in ensuring quality of service across diverse edge environments.
How AI Optimizes Dynamic Resource Allocation
AI has fundamentally changed how resources are allocated, shifting from reactive methods to proactive, data-driven strategies. Instead of waiting for problems to arise, AI continuously monitors systems and predicts resource demands, ensuring smoother operations even during peak usage.
AI-Based Monitoring and Demand Prediction
AI systems analyze real-time data from edge devices - tracking metrics like CPU usage, RAM, and storage - to predict future needs and optimize workloads effectively. These systems often rely on advanced hybrid forecasting models, which combine Bidirectional Long Short-Term Memory (BiLSTM) and Gated Recurrent Unit (GRU) layers. This combination helps forecast resource usage patterns, enabling flexible and efficient scheduling. By performing these tasks directly at the data source, AI avoids the delays of relying on cloud-based instructions, making decisions autonomously.
This approach has shown impressive results across various industries, from industrial IoT setups to agricultural applications. The ability to predict and act on resource demands in real time allows for seamless adjustments, ensuring that systems can handle diverse and dynamic environments.
Real-Time Decision-Making Algorithms
Deep Reinforcement Learning (DRL) combines reinforcement learning techniques with neural networks to determine the best resource allocation actions. For instance, Deep Q-Networks (DQN) map system states - like CPU and RAM usage or latency - to optimal actions, such as whether to process tasks locally, at the edge, or in the cloud.
To improve on DQN's limitations, Double Deep Q-Networks (DDQN) use two separate networks: one for selecting actions and another for evaluating their value. This dual-network approach minimizes overestimation bias. As highlighted in Scientific Reports:
The Double Deep Q-Network (DDQN) provides superior training stability by separating action selection from value evaluation, thus reducing the overestimation bias present in conventional DQN frameworks.
A notable example is the AICDQN framework (Adaptive and Intelligent Customized Deep Q-Network), which reduced delays by 33.39% and improved energy efficiency by 57.74% compared to traditional offloading methods.
For tasks requiring continuous adjustments, such as fine-tuning CPU frequency or adjusting transmit power, AI systems use Deep Deterministic Policy Gradient (DDPG) algorithms. These are particularly effective for managing non-binary resource allocation and have been shown to cut task drop rates by up to 81.25% in high-traffic scenarios. These algorithms integrate seamlessly into larger systems, ensuring efficient collaboration between edge devices and cloud resources.
Task Offloading Between Edge and Cloud
AI plays a crucial role in deciding when to offload tasks between local devices, edge servers, and the cloud. This decision-making process is modeled as a Markov Decision Process (MDP), which evaluates three execution layers: local hardware for immediate, low-power tasks; edge servers for low-latency needs; and the cloud for handling large-scale data analytics.
Hybrid architectures predict task surges, enabling proactive offloading decisions instead of reactive ones. AI assigns an urgency score to tasks based on factors like deadlines, priority, and current system load. By using queue models - such as M/M/1 for individual devices and M/M/c for edge servers - the system prevents overloading already busy nodes.
A real-world example of this in action occurred in October 2025, when Virtuous AI deployed a generative AI model using DartPoints' edge data center in Greenville, South Carolina. By leveraging high-performance colocation infrastructure tailored for AI workloads, Virtuous AI achieved the low-latency performance needed for real-time responses in a distributed environment.
These AI-driven strategies form the foundation of dynamic resource allocation, providing a robust framework for managing complex, ever-changing demands.
Step-by-Step Guide to Implementing AI-Driven Resource Allocation
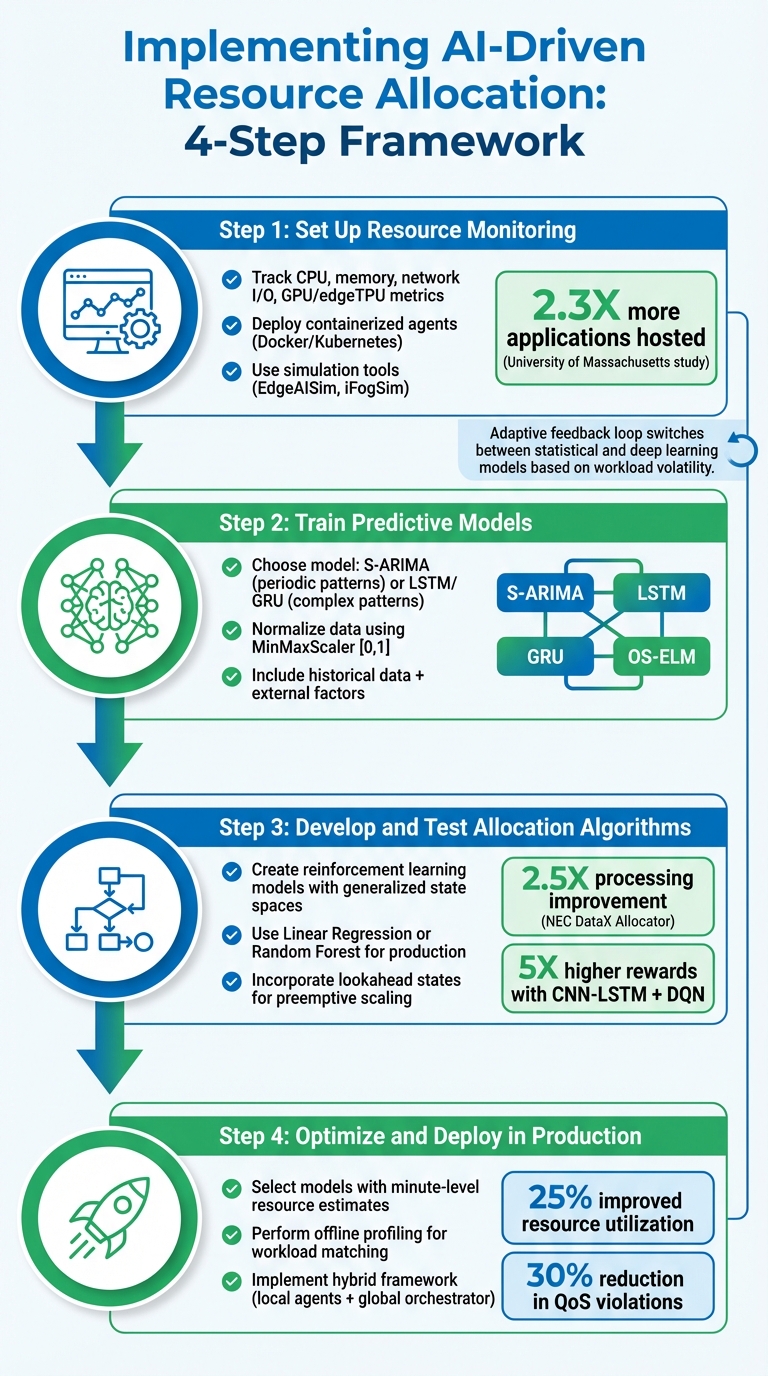
4-Step Implementation Guide for AI-Driven Resource Allocation in Edge Computing
If you're looking to integrate AI-driven resource allocation into edge environments, a systematic approach is essential. Each step builds upon the last to ensure effective implementation and smooth operations.
Step 1: Set Up Resource Monitoring
Start by tracking detailed, time-series data from your edge devices. This includes metrics like CPU load, memory usage, network I/O, and hardware-specific details such as GPU or edgeTPU utilization. AI relies on this comprehensive system view to make informed decisions.
To streamline monitoring, deploy containerized agents using tools like Docker or Kubernetes. For DNN inference workloads on shared edge accelerators, consider using Kubernetes sidecars for monitoring. A 2022 study from the University of Massachusetts Amherst demonstrated that a Kubernetes-based cluster resource management system could host 2.3X more applications than traditional knapsack algorithms, all while avoiding latency issues.
Before live deployment, use simulation tools like EdgeAISim or iFogSim to validate monitoring accuracy and test allocation policies. Pre-process raw data using feature extraction techniques, such as CNN-based filters, to identify spatial correlations and patterns before feeding the data into predictive models.
Step 2: Train Predictive Models
Choose a predictive model tailored to your workload. For tasks with clear periodic patterns, Seasonal ARIMA (S-ARIMA) works well. For more complex, non-linear temporal dependencies, Recurrent Neural Networks like LSTM or GRU are better options. GRU is often preferred for edge nodes due to its simpler structure and reduced resource demands.
In 2025, researchers Thang Le Duc, Chanh Nguyen, and Per-Olov Östberg developed a proactive resource allocation system using 18 months of real traffic data from BT's Content Delivery Network. By combining S-ARIMA, LSTM, and OS-ELM models, they forecast workload seasonality and cache-tier interactions, enabling proactive scaling with minimal rejection rates.
To prepare your data for training, use the MinMaxScaler method to normalize input values to a [0,1] range. This step speeds up convergence and improves model performance. Enhance forecasting accuracy by including external factors and static metadata, such as device-specific details, alongside historical usage data. Keep an eye on prediction errors over time - if errors increase significantly, it may signal concept drift, requiring model updates.
Once your predictive models are ready, the next step is to design and test allocation algorithms.
Step 3: Develop and Test Allocation Algorithms
Create reinforcement learning models with generalized state spaces. This ensures the models can adapt to different workload types or varying numbers of microservices without requiring retraining. These models use the forecasts from the previous step to adjust resource distribution proactively.
In 2022, NEC Laboratories America introduced the "DataX Allocator", a reinforcement learning model for dynamic edge resource management. When applied to a complex action recognition pipeline, this model doubled the processing rate compared to standard methods, achieving up to 2.5X overall improvements.
For production environments, simpler machine learning models like Linear Regression or Random Forest often outperform complex neural networks because they require less training time and fewer computational resources. As Rafael Moreno-Vozmediano from Complutense University of Madrid explains:
The time lag between the detection of the overload condition and the resource scaling decision may result in a temporary shortage of resources and a subsequent performance degradation. To address this issue, predictive auto-scaling techniques must be introduced in place of reactive ones.
Incorporate lookahead states into your AI agent's design. By including both current metrics and predicted future states, you enable preemptive scaling. Hybrid AI models, such as CNN-LSTM combined with DQN, can achieve nearly 5X higher rewards compared to reactive models by anticipating load spikes.
Step 4: Optimize and Deploy in Production
Select models capable of delivering resource estimates within minutes to enable rapid auto-scaling. Perform offline profiling to match workloads with resource consumption across different hardware setups. This step ensures that real-time adjustments align with the broader cloud-edge coordination strategy.
For large-scale systems, consider a hybrid framework. Local agents can handle neighborhood-level decisions, while a global orchestrator ensures system-wide coordination. This approach balances scalability with the need for global oversight.
Finally, implement an adaptive feedback loop that switches between statistical models (for lower computational cost) and deep learning models (for higher accuracy) based on workload volatility. AI-driven predictive models can improve resource utilization by 25% and reduce Quality of Service violations by 30% compared to traditional methods.
Benefits of AI-Driven Dynamic Resource Allocation
Organizations adopting AI-driven resource allocation strategies are seeing noticeable operational improvements. These systems enhance resource efficiency, boost performance, and help cut operational costs.
Better Resource Utilization
AI dynamically adjusts resources in real time, overcoming the inefficiencies of traditional static allocation methods. By analyzing workload patterns, AI reallocates CPU, GPU, memory, and storage to where they’re needed most. This real-time adaptability eliminates overprovisioning and waste.
The shift from reactive to predictive management is a game-changer. Anil Abraham Kuriakose from Algomox highlights:
This dynamic adjustment not only optimizes performance but also significantly reduces operational costs by preventing unnecessary resource allocation.
In short, AI ensures that organizations only use the resources they truly need, leading to greater efficiency and improved system performance.
Lower Latency and Better Performance
AI's predictive capabilities help systems respond to workload changes before they occur, reducing delays by processing data close to its source. This enables tasks to execute in the most efficient location - whether on an edge device, a local gateway, or the cloud. For applications like autonomous vehicles and industrial automation, where every millisecond counts, this is especially critical.
By analyzing historical data and real-time network conditions, AI-driven systems proactively scale resources ahead of traffic spikes, ensuring consistent application performance across diverse hardware setups. Lavanya Shanmugam from Tata Consultancy Services notes:
Edge computing has emerged as a promising paradigm for handling the computational demands of AI/ML tasks by leveraging resources closer to data sources.
Cost and Energy Savings
AI-driven optimization directly translates to cost reductions by preventing unnecessary resource consumption. This is particularly beneficial in resource-constrained environments, where avoiding waste can significantly lower capital and operational expenses. Processing data locally also reduces costs tied to long-distance data transmission, bandwidth usage, and backhaul traffic.
Energy efficiency is another major advantage. AI systems automatically shut down unused capacity and adjust power consumption based on real-time demand. This is crucial for battery-powered devices like wearables and autonomous vehicles, where excessive power use can lead to thermal issues or rapid battery drain. Additionally, predictive maintenance helps avoid hardware failures, cutting costs associated with unexpected outages or unnecessary repairs.
Conclusion
This guide underscores how AI is reshaping resource allocation in edge environments, moving from a reactive approach to a predictive one that anticipates workload fluctuations. By identifying patterns, AI optimizes CPU, memory, and storage usage ahead of time, effectively preventing bottlenecks and avoiding delays caused by resource shortages.
The benefits of AI-driven allocation are clear. For example, the "DataX Allocator" reinforcement learning system showcased a 2.5X boost in processing rates, all while adapting seamlessly to varying workloads.
However, deploying these systems effectively requires careful consideration of multiple factors. Machine learning models like Gradient Boosting automate scaling decisions, reducing waste compared to rigid, fixed allocation methods. As Rafael Moreno-Vozmediano and his team from Complutense University of Madrid explain:
The time lag between the detection of the overload condition and the resource scaling decision may result in a temporary shortage of resources.
AI's applications stretch across diverse industries. From enabling split-second decision-making in autonomous vehicles to managing dense IoT networks with up to one million devices per square kilometer, AI ensures resources are allocated precisely when and where they are needed. This coordination spans from local processing to the integration of edge and cloud systems, demonstrating its versatility and efficiency.
FAQs
What data should I monitor for AI-based allocation?
To make AI-powered resource allocation work effectively, you need to keep an eye on several critical data points. Start with workload characteristics, such as input volume and processing demands. Then, focus on application-specific metrics, like processing rate and accuracy, to evaluate how well the system is performing its tasks.
Real-time performance metrics are equally important - things like CPU usage, memory consumption, and network activity give you a clear picture of system health. In edge environments, where speed is key, tracking latency and response times becomes essential.
Using predictive analytics alongside historical data can also make a big difference. These tools help forecast future needs, allowing you to make proactive adjustments that keep performance smooth and efficient.
How do I choose between forecasting models and reinforcement learning?
Choosing the right approach between forecasting models and reinforcement learning hinges on how you plan to manage resources.
Forecasting models work best in steady environments where patterns can be anticipated. They rely on historical data to help you make informed plans for the future. On the other hand, reinforcement learning shines in unpredictable, ever-changing situations. It thrives by making real-time decisions and adapting through continuous interaction with its surroundings.
If you're dealing with rapidly shifting conditions, reinforcement learning provides more adaptability and the ability to fine-tune decisions as circumstances evolve.
When should a task run locally, on the edge, or in the cloud?
When low latency, offline functionality, or data privacy are priorities, running tasks locally or on the edge is the way to go. Edge computing helps cut delays, supports real-time responses, and keeps data transfer costs in check.
For tasks that need high computational power, centralized processing, or the ability to scale easily, the cloud is your best bet. Many systems combine both approaches: basic processing is handled at the edge, while more demanding operations are sent to the cloud.