Dynamic Sparse Data for Evolving AI Models
Dynamic sparse data is transforming AI by making models more efficient and responsive. Instead of activating all parameters, it selectively uses only the necessary ones for each input, cutting down on computational costs and energy usage. Here's what you need to know:
- Efficiency: Models like NeuroTrails and ResNet-50 demonstrated better performance with fewer parameters and reduced FLOPs.
- Scalability: Techniques like Sparse Maximal Update Parameterization (SμPar) allow large sparse models to perform as well as dense ones without extra tuning.
- Real-Time Adjustments: Dynamic systems assess input complexity on the fly, optimizing resources and maintaining performance.
- Applications: From text generation (ChatGPT) to image creation (Dall-E), dynamic sparsity improves quality while reducing computational demands.
Core Principles of Dynamic Sparse Data Management
Sparsity in Data Representation
Sparsity in data representation focuses on using only the necessary parameters during computation, instead of engaging all of them. By implementing sparse data structures, you store only non-zero values along with their indices. This approach can significantly reduce memory usage, especially in high-dimensional datasets where less than 10% of the data is meaningful.
However, converting sparse structures into dense formats can erase these efficiency gains. For instance, adding constants to sparse matrices or performing certain division operations may introduce numerous non-zero values, undermining the benefits of sparsity. When working with frameworks like Pandas, it’s crucial to use specialized sparse data types, such as Sparse[float64], to preserve these advantages throughout the data pipeline.
Dynamic Adaptation Techniques
Beyond efficient storage, dynamic adaptation fine-tunes parameters in real time. Instead of locking sparsity patterns from the start, these techniques assess importance dynamically, tailoring the process to the specific task at hand.
One promising method is dynamic content-aware filtering, which identifies significant query-key pairs during computation by using approximate dot-product scores. This approach reallocates resources on the fly, focusing only where they’re needed. For example, the Energon co-processor demonstrated this concept in February 2026, achieving up to 168× faster performance compared to traditional CPUs and 8.7× faster than GPUs by leveraging dynamic sparse attention mechanisms.
Another useful technique, Progressive and Adaptive Data Pruning (PADP), evaluates data based on "instant difficulty" and "difficulty variation" scores. This method determines which data points to retain as models evolve. By doing so, it reduced training time by up to 52.90%, all while maintaining or even improving model accuracy. A key consideration when implementing PADP is to include a class-balance retention mechanism. This ensures that no specific categories are entirely removed during pruning, preserving the model's ability to generalize across all classes.
Once critical parameters are dynamically selected, the next step is to ensure that these optimizations do not come at the cost of model performance.
Balancing Sparsity and Model Performance
Dynamic filtering techniques are only part of the equation. The real challenge lies in maintaining model accuracy while adopting sparsity. As researchers Nolan Dey, Shane Bergsma, and Joel Hestness explain:
"Sparse and dense networks do not share the same optimal HPs. Without stable dynamics and effective training recipes, it is costly to test sparsity at scale".
Sparse Maximal Update Parameterization (S$\mu$Par) addresses this issue by ensuring that activations, gradients, and weight updates remain consistent, regardless of sparsity levels. This method allows hyperparameters optimized for small dense networks to be applied effectively to large sparse models. Using S$\mu$Par, researchers achieved an 11.9% relative improvement in loss at 99.2% sparsity compared to standard parameterization.
Studies have also shown that masking up to 95–99% of attention weights in Transformer models can result in negligible changes - or even improvements - in metrics like F1 score and perplexity. The key lies in using data-driven assessments rather than relying on arbitrary thresholds. This allows models to adapt their sparsity based on the specific needs of each input, ensuring optimal performance.
sbb-itb-903b5f2
Elastic Attention: Dynamic Sparsity for LLMs
Implementing Dynamic Sparse Data in AI Models
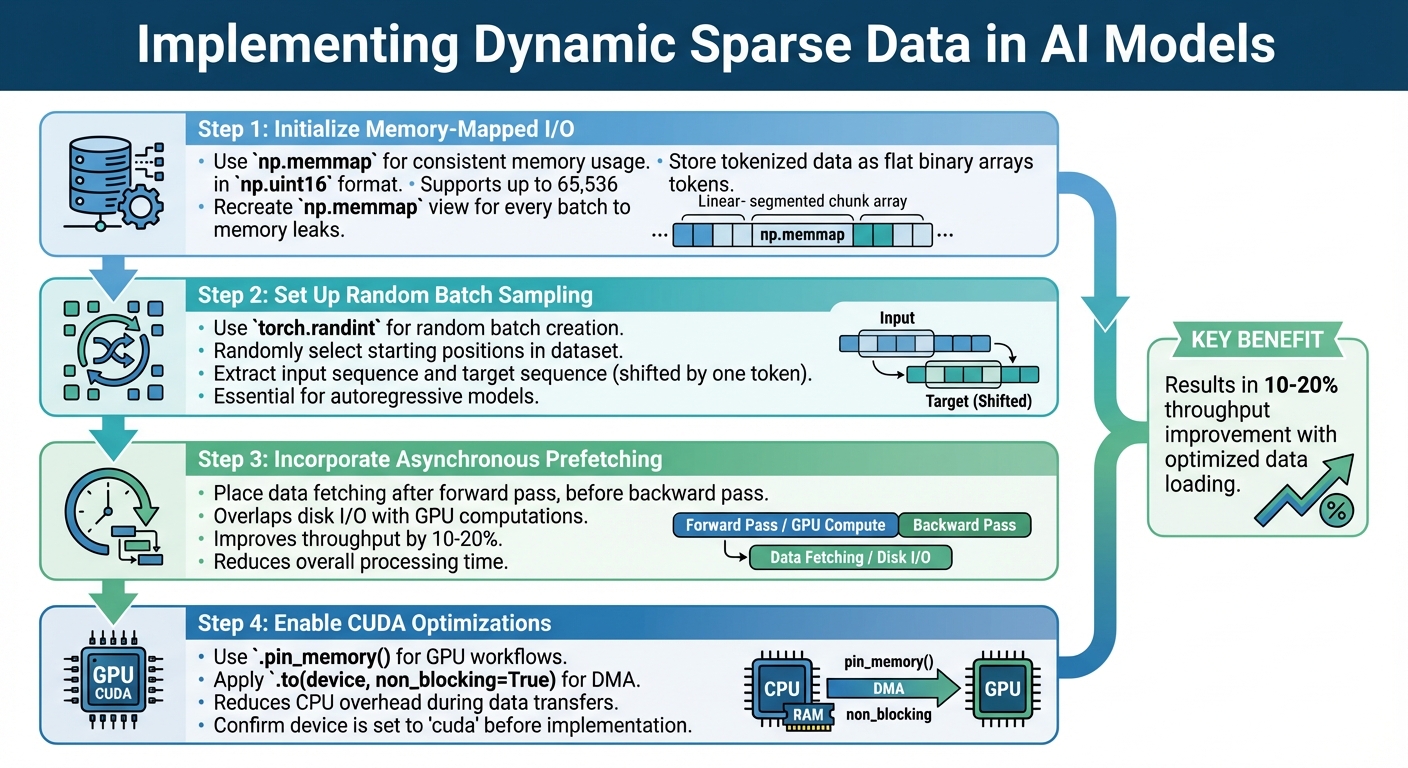
Steps to Implement Dynamic Sparse Data in AI Models
Steps for Implementation
Start by initializing memory-mapped I/O using np.memmap. This approach ensures your memory usage remains consistent no matter how large the dataset is. Tokenized data should be stored as flat binary arrays in np.uint16 format. This method supports up to 65,536 tokens while keeping storage efficient.
Next, set up random batch sampling with torch.randint. This allows you to create training batches by randomly selecting starting positions in the dataset. For autoregressive models, you'll need to extract an input sequence and a target sequence shifted by one token. To avoid memory leaks, recreate the np.memmap view for every batch. This ensures your process memory footprint stays stable.
Incorporate asynchronous prefetching to improve performance. Place data fetching calls right after the forward pass begins but before the backward pass. This overlaps disk I/O operations with GPU computations, saving time. For CUDA workflows, use .pin_memory() and .to(device, non_blocking=True) to enable Direct Memory Access (DMA). This reduces CPU overhead during data transfers.
By following these steps, you can build a solid foundation for managing dynamic sparse data efficiently. Specialized frameworks can further streamline this process.
Tools and Frameworks for Sparse Data Management
Certain frameworks are designed to simplify the integration of dynamic sparse data into AI workflows.
nanoGPT is a lightweight framework tailored for training GPT models while efficiently handling sparse data. Its data loading system is straightforward, relying on a single get_batch() function with roughly 15 lines of code, eliminating the need for PyTorch's more complex DataLoader abstraction. This streamlined approach avoids the overhead of multiprocessing and provides better control over the data pipeline. Impressively, nanoGPT can replicate GPT-2 (124M parameters) on a single 8xA100 node in about four days.
For managing context limits, nanoGPT includes a Context Memory API. This feature compresses entire conversation histories into single "memory messages", targeting an output of 8,000–20,000 tokens - roughly 10% of a standard large context window - while still retaining access to the full history. Pricing for the standalone endpoint is as follows: $5.00 per 1 million non-cached input tokens, $2.50 per 1 million cached tokens, and $10.00 per 1 million output tokens.
Another tool, SμPar (Sparse maximal update parameterization), ensures stable scaling of activations, gradients, and weight updates across varying sparsity levels. This allows hyperparameters from smaller dense networks to be directly applied to larger sparse models, simplifying the training process. SμPar integrates seamlessly into training pipelines to maintain consistent dynamics during sparsification.
Best Practices for Integration
To ensure efficient implementation, follow these best practices:
- Confirm that your device is set to 'cuda' before using
.pin_memory()for GPU optimizations. - Store dataset-specific details, such as
vocab_size, in ameta.pklfile during data preparation. This allows the model to configure its architecture automatically during initialization. - For privacy-conscious setups, adjust retention policies for dynamic sparse context data. By default, these systems retain data for 30 days, but you can customize this window (from 1 to 365 days) using headers like
memory_expiration_days. If conversations are deleted locally, ensure the associated compressed memory state is also removed from provider systems.
To enhance execution speed, utilize torch.compile. This can significantly reduce iteration times - for instance, from 250ms to 135ms per iteration. In API implementations, you can enable dynamic context management by appending suffixes (e.g., :memory) or setting headers (e.g., memory: true) without requiring changes to the core architecture.
These strategies can help you integrate dynamic sparse data into your AI models effectively while maintaining flexibility and performance.
Use Cases and Applications of Dynamic Sparse Data
Dynamic sparse data is a game-changer when it comes to improving performance in various AI applications. Here's how it makes an impact across different areas:
Improving Text Generation Models
Dynamic sparse data helps text generation models deliver high-quality results while cutting down on computational demands. For instance, Sparse maximal update parameterization (SμPar) allows developers to fine-tune hyperparameters on smaller dense networks and then apply those settings to larger sparse models. This eliminates the need for expensive, large-scale tuning efforts.
The key to success here is maintaining stable training dynamics. As Nolan Dey, Shane Bergsma, and Joel Hestness emphasize:
"Without stable dynamics and effective training recipes, it is costly to test sparsity at scale, which is key to surpassing dense networks and making the business case for sparsity acceleration in hardware".
This stability ensures that models like ChatGPT and Gemini can operate efficiently without sacrificing the quality of their text outputs.
Optimizing Image Generation Systems
Dynamic sparse data also shines in image generation. Tools like Dall‑E and Stable Diffusion can maintain exceptional performance even at sparsity levels as high as 99.2%. By leveraging sparse training dynamics, developers don’t need to retune hyperparameters for different model sizes or sparsity configurations, saving both time and computational resources.
These efficiency benefits are particularly valuable in privacy-sensitive settings, where reducing computational overhead can also help maintain user privacy.
Applications in Privacy‑Focused AI Systems
Dynamic sparse data is particularly useful for privacy-first AI systems. Its ability to streamline computation aligns perfectly with data minimization practices. For instance, platforms that store data locally on user devices use dynamic sparse data alongside hierarchical compression methods. Systems like Context Memory employ a B‑tree architecture: upper levels summarize data, while lower levels retain detailed information. This structure allows the system to expand relevant sections only when needed, keeping the overall data footprint small.
The focus on data minimization is clear: only conversation messages are compressed, while sensitive metadata (like IP addresses, emails, or browser cookies) is excluded from processing. Typically, these systems aim for a compressed output of 8,000–20,000 tokens - roughly 10% of a standard large context window - while still preserving access to the entire history. If users delete conversations locally, the associated compressed memory data is immediately removed from servers, ensuring data remains synchronized. Default retention is set at 30 days, but users can adjust this window from 1 to 365 days, offering greater control over their data.
NanoGPT takes this a step further with its pay‑as‑you‑go model. By allowing data to remain stored locally and providing access to models like ChatGPT, Gemini, and Dall‑E without requiring subscriptions, NanoGPT empowers users to manage their data while benefiting from efficient sparse data operations.
Conclusion and Key Takeaways
Benefits at a Glance
Dynamic sparse data brings a new level of efficiency to AI models. It allows for preserving over 500,000 tokens of historical context while focusing on 8,000–20,000 tokens of key information. This hierarchical compression method ensures no loss of quality or context awareness, even with large datasets.
By incorporating asynchronous prefetching, throughput improves by 10–20%. Additionally, optimized data loaders and memory-mapped I/O ensure smooth and efficient training processes, keeping input/output operations effective.
From a cost perspective, dynamic sparse data is budget-friendly. Context Memory pricing stands at $1.00 per 1M cached input tokens and $1.25 per 1M output tokens. These features make it a practical choice for scaling AI projects without breaking the bank.
How to Start Using Dynamic Sparse Data
Ready to integrate dynamic sparse data into your AI workflows? Here’s how you can begin:
-
Enable Context Memory: Use NanoGPT by appending
:memoryto model names (e.g.,openai/gpt-5.2:memory) or include amemory: trueheader in API requests. You can also manage data retention periods from 1 to 365 days by adding suffixes like:memory-90for a 90-day retention window. -
Optimize Training Pipelines: Use
np.memmap()for memory-mapped files when working with large datasets. If you're using CUDA devices, applying.pin_memory()allows faster CPU-to-GPU data transfers via Direct Memory Access. These steps ensure your data loading processes stay efficient as your projects grow.
With NanoGPT's pay-as-you-go pricing and local data storage options, you can experiment with models like ChatGPT, Gemini, and Dall-E while keeping costs under control and maintaining data privacy - no subscriptions required. These tools and techniques make it easier than ever to scale your AI projects effectively.
FAQs
When should I use dynamic sparsity instead of static sparsity?
Dynamic sparsity shines when your AI tasks demand input-specific adaptation or real-time decision-making. It's particularly useful in situations where the importance of data changes with each input - think large output spaces or tasks involving long contexts. By creating run-time masks, dynamic sparsity hones in on the most relevant parts of the data, boosting efficiency while maintaining accuracy.
In contrast, static sparsity relies on fixed patterns. While it works in more predictable settings, it can struggle in dynamic environments where input importance constantly shifts.
How do I keep accuracy stable as sparsity increases during training?
To keep accuracy intact as sparsity increases during training, it’s crucial to use effective initialization and adapt dynamically. ER initialization stands out over random methods because it maintains signal flow in sparse networks. On top of that, dynamic sparse training reshapes the network’s structure during training to align with changing data patterns, reducing the risk of accuracy drops. These approaches play a key role in addressing performance challenges caused by higher sparsity.
What’s the safest way to avoid accidentally densifying sparse data in my pipeline?
To avoid accidentally increasing the density of sparse data, consider using dynamic sparse training techniques. These methods adjust the model's structure during training, ensuring it remains efficient and effective. Approaches like dynamic sparse heads and topology evolution modify connectivity based on the data and signals, keeping sparsity intact while enhancing performance. Another useful strategy is parameter-freezing during training, which helps maintain sparsity and prevents unnecessary density increases. Together, these adaptive methods ensure that sparsity is preserved throughout the training process.