Fact-Checking Frameworks for AI Models
AI-generated content often sounds convincing but can be factually incorrect. This has led to real-world issues like lawyers citing fake cases, patients receiving flawed advice, and buggy code being deployed. Fact-checking frameworks are crucial to address these challenges, especially as AI becomes more integrated into daily life.
Here’s what you need to know:
- Why Fact-Checking Matters: By 2025, AI-driven disinformation surged, making it harder to identify truth. Inaccurate content also risks visibility on search engines prioritizing reliability.
- Key Problems: AI models often "hallucinate" facts, with error rates reaching 65.5%. Outdated or insufficient training data worsens the issue.
- Solutions: Fact-checking frameworks follow three steps: breaking down claims, retrieving evidence, and verifying accuracy. Techniques like Retrieval-Augmented Generation (RAG) and tools like NanoGPT are reducing error rates and costs.
Popular frameworks like FacTool, OpenFactCheck, RARR, and Factcheck-GPT offer tailored solutions for different needs, from verifying scientific literature to evaluating entire documents. Combining automation with human oversight remains the most reliable approach.
Bottom Line: Effective fact-checking frameworks are essential to ensure AI-generated content is accurate, reliable, and trustworthy.
Towards real-world fact-checking with large language models
Core Components of Fact-Checking Frameworks
Fact-checking relies on three main steps: identifying precise claims, gathering evidence, and verifying the claims. These steps are essential to ensure AI-generated outputs are accurate and reliable.
Claim Detection and Extraction
The first step is breaking down AI-generated text into atomic claims, which are the smallest units that can be independently verified. For instance, a sentence like "The company's CEO announced record profits in Q4" contains multiple atomic claims: one about who made the announcement, another about the timing, and a third about the financial performance.
Decontextualization plays a key role in this process. It ensures claims are self-contained by replacing ambiguous references with specific details. For example, "It is used for treating infections" becomes "Java tea is used for treating infections". This adjustment allows search engines to locate relevant evidence without relying on additional context. In fact, the University of Washington's Facts&Evidence tool showed that skipping this step led to a significant drop in performance, with the F1 score falling from 0.68 to 0.40.
Modern frameworks also incorporate check-worthiness filtering to focus on claims that are either of public interest or have the potential to cause harm. This approach not only improves efficiency but also reduces the cost of automated fact-checking to around $0.02 per atomic claim when using models like GPT-3.5-Turbo.
Evidence Retrieval Methods
After claims are identified, the next step is finding relevant supporting or contradicting information. Tools like web search APIs (e.g., Serper) enable real-time Google queries, while vector databases (such as Facebook AI Similarity Search, or FAISS) perform rapid semantic searches across large datasets. Depending on the task, systems may choose between dense retrieval (embedding-based semantic matching) and sparse retrieval (keyword-based methods like BM25) to either grasp concepts or locate exact terms.
Some frameworks go a step further with iterative retrieval, where initial search results inform and refine follow-up queries. The FIRE (Fact-checking with Iterative REtrieval) framework mirrors the approach of human fact-checkers by building on previous searches. When paired with GPT-4o-mini, FIRE reduced search costs by a factor of 16.5 compared to traditional methods.
"We've tried to develop an iterative process that is similar to the way a human fact-checker would verify a claim." – Zhuohan Xie, postdoctoral researcher at MBZUAI.
Source credibility is another critical factor. Systems categorize sources - government websites, scientific papers, news outlets, blogs - and assign reliability scores accordingly. For training purposes, datasets like VERIFAID, which includes over 33,000 verified articles from trusted sources such as PolitiFact and Snopes, are commonly used.
Claim Verification Processes
The final step involves cross-checking extracted claims against the retrieved evidence. This is often done using a verifier, typically a large language model (LLM), with techniques like Chain-of-Thought (CoT) prompting. The model then determines whether the evidence supports, refutes, or fails to address the claim.
Verification results are often summarized as a credibility score, which reflects the percentage of evidence supporting the claims in a given text. For example, the Facts&Evidence system demonstrated a 44-percentage-point improvement in error prediction accuracy over baseline methods. Additionally, smaller models like MiniCheck-FT5 (with 770 million parameters) have matched GPT-4's accuracy while operating at a fraction of the cost - up to 400 times cheaper.
Despite these advancements, human-in-the-loop verification remains the most reliable approach. Integrating expert review into the process significantly reduces hallucinations - by as much as 59% in benchmark tests - compared to fully automated systems. Tools like NanoGPT support this workflow while ensuring data remains stored locally on users' devices to maintain privacy.
Key Fact-Checking Frameworks
These specialized frameworks provide tools tailored to specific tasks, ensuring accuracy in AI-generated content across various domains.
FacTool
FacTool focuses on four key areas: knowledge-based question answering, code generation, mathematical reasoning, and scientific literature reviews. Unlike general-purpose fact-checking tools, it excels at identifying specific issues like coding errors and calculation mistakes. In benchmark tests, FacTool showed impressive results, with GPT-4 achieving a weighted claim-level accuracy of 75.60% and a response-level accuracy of 43.33%. To function, the framework requires an OpenAI API key for reasoning tasks, a Serper API key for knowledge-based queries, and a Scraper API key for verifying scientific content. For those concerned about costs, using GPT-3.5-Turbo as the backend keeps expenses manageable. Next, let’s dive into OpenFactCheck, which offers a modular approach for more tailored fact-checking workflows.
OpenFactCheck
OpenFactCheck is an open-source framework with a modular design, allowing developers to build personalized fact-checking systems by combining interchangeable components. It features three main modules: CustChecker for creating custom workflows, LLMEval for benchmarking against seven datasets, and CheckerEval for evaluating the reliability of fact-checking tools. The framework includes the FactQA dataset, which compiles 6,480 examples from seven corpora to test a wide range of factual vulnerabilities. Developers can choose between offline methods like BM25 on Wikipedia or real-time web APIs for claim processing, retrieval, and verification, depending on their needs. For a different perspective, let’s explore how RARR and Factcheck-GPT handle fact-checking at varying levels of granularity.
RARR and Factcheck-GPT

RARR (Retrofitting Attribution using Research and Revision) takes a document-level approach, verifying entire texts and generating detailed attribution reports to pinpoint factual errors. On the other hand, Factcheck-GPT opts for a more granular method. It isolates intermediate errors by aggressively decontextualizing sentences and claims, ensuring they’re evaluated independently of their original context. Interestingly, research shows that GPT-4 can identify 87% of its own factual mistakes when asked to justify its prior outputs. This comparison highlights the strengths of both document-level and fine-grained fact-checking strategies.
Framework Performance Comparison
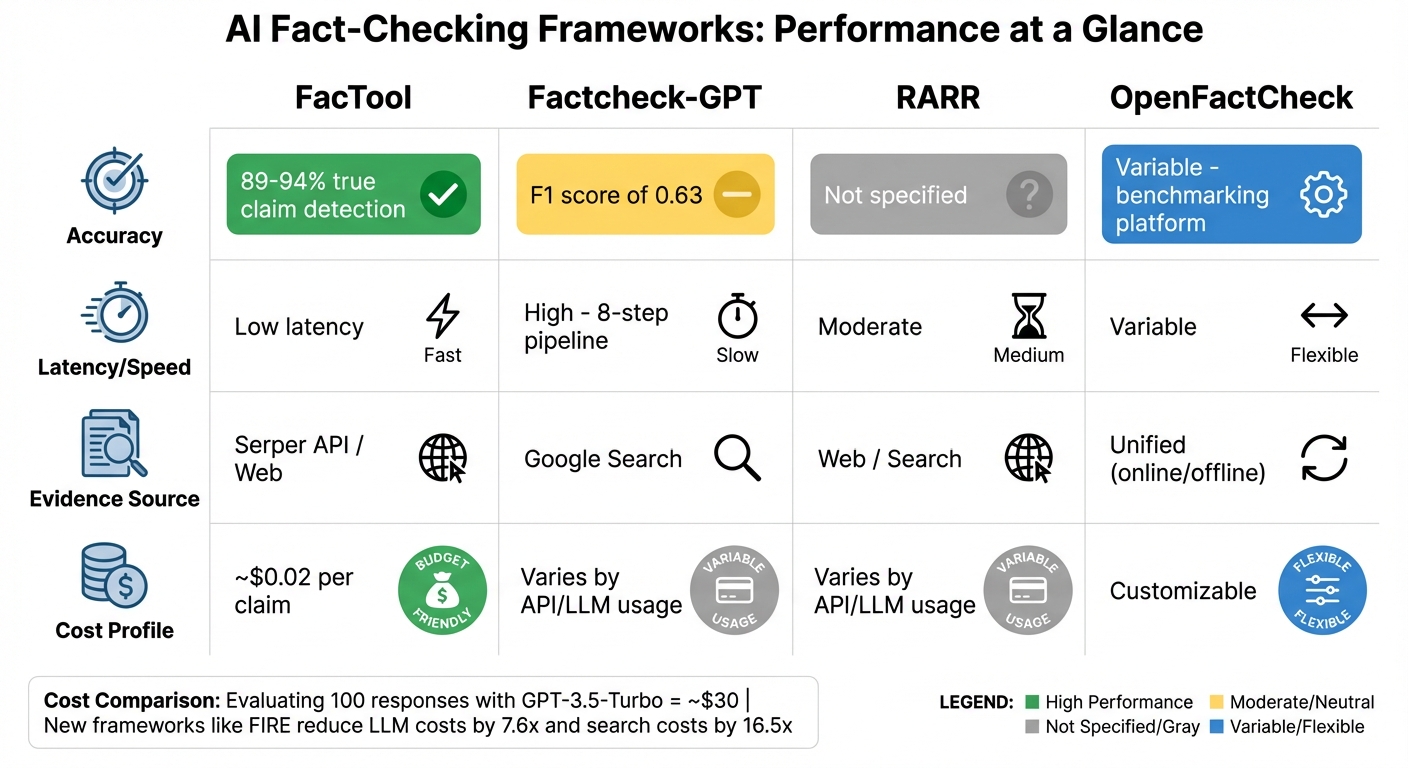
AI Fact-Checking Frameworks Performance Comparison: Accuracy, Speed and Cost
When choosing a fact-checking framework, understanding how each one performs is key. FacTool stands out for its speed, as it’s specifically designed for quick responses across various domains like code generation and mathematical reasoning. It successfully identifies 89–94% of true claims but faces difficulties with more complex datasets. Below, we break down key differences in latency, accuracy, and cost among popular frameworks.
Factcheck-GPT uses a detailed 8-step pipeline to catch intermediate errors that others might miss. While this method is thorough, it slows down processing and can pose accuracy challenges. Yuxia Wang, Lead Author, highlighted the limitations of current tools:
"Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims, with the best F1=0.63 by this annotation solution based on GPT-4".
The framework relies heavily on Google Search for evidence, which increases computational demands.
Some frameworks take a more holistic approach to evaluation. RARR, for instance, focuses on verifying entire documents rather than breaking text into smaller claims. It generates attribution reports to explain factual errors in context, offering deeper insights but requiring moderate computational resources.
On the other hand, OpenFactCheck acts as a benchmarking platform, allowing users to combine components from different frameworks. It supports both high-cost, real-time web APIs and budget-friendly offline retrievers like Wikipedia dumps paired with BM25, making it highly flexible.
Here’s a summary of the key performance metrics for each framework:
| Framework | Accuracy | Latency | Evidence Source | Cost Profile |
|---|---|---|---|---|
| FacTool | 89–94% true claim detection | Low latency | Serper API / Web | ~$0.02 per claim |
| Factcheck-GPT | F1 score of 0.63 | High (8-step pipeline) | Google Search | Varies by API/LLM usage |
| RARR | Not specified | Moderate | Web / Search | Varies by API/LLM usage |
| OpenFactCheck | Variable (benchmarking) | Variable | Unified (online/offline) | Customizable |
To put costs into perspective, evaluating 100 open-domain responses with GPT-3.5-Turbo costs around $30. Meanwhile, newer frameworks like FIRE are driving down expenses, cutting LLM costs by an average of 7.6 times and search costs by 16.5 times compared to traditional methods.
sbb-itb-903b5f2
Implementing Fact-Checking with Retrieval-Augmented Generation
How RAG Works in Fact-Checking
Retrieval-Augmented Generation (RAG) tackles the challenge of AI models producing overly confident but inaccurate responses by grounding their outputs in verified external data. Here's how it works: First, trusted data sources - like news archives or verified databases - are cleaned, segmented, and transformed into vector embeddings stored in a searchable database. When a claim is made, it's converted into a vector, and the system retrieves the most relevant data chunks. These retrieved facts are then combined with the original claim in a prompt that directs the model to respond strictly based on the provided context. The result? A response rooted in evidence, not conjecture. This method builds on traditional fact-checking techniques by anchoring AI outputs in verified information.
The impact of RAG is clear: it boosts factual accuracy from 58% to over 90% in relevant tasks. Jenna Pederson, Developer Advocate at Pinecone, sums it up perfectly:
"The question is no longer whether to implement RAG, but how to architect it most effectively for your unique use case and data requirements."
Modern implementations often use "Agentic RAG", where AI agents take an active role in the process. These agents decide what questions to ask, assess whether retrieved data is relevant, and apply reasoning to validate information before generating responses. This ensures the system doesn't blindly rely on every retrieved result.
Implementation Steps
RAG builds on the principles of claim verification and evidence retrieval, taking fact-checking to a new level of accuracy through dynamic evidence processing. If you're ready to implement RAG, here’s a practical guide to get started.
Begin with claim decontextualization - breaking down complex statements into simple, verifiable facts. For emotionally charged or social media content, smaller models like Llama-2-13b can help extract these facts before retrieval.
Next, opt for a hybrid search approach that combines semantic understanding (dense vectors) with keyword matching (sparse vectors). This ensures the system handles both general queries and niche, domain-specific terminology effectively. After retrieving initial results, use a reranking model like monoT5 to prioritize the most relevant documents for your generator.
When presenting multiple data chunks to the model, strategically place the most relevant pieces at the beginning and end of the prompt. This "sides" method helps the model stay focused. Additionally, set a citation threshold - around 0.6 - to control confidence levels. This approach prioritizes fewer but stronger citations, ensuring higher reliability.
For cost-effective implementation, consider smaller specialized models like MiniCheck-FT5, which can achieve GPT-4-level performance at a fraction of the cost - 400 times lower, to be exact. Platforms like NanoGPT offer access to multiple AI models, such as ChatGPT, Deepseek, and Gemini, on a pay-as-you-go basis. This flexibility allows you to experiment with different models and strike the right balance between accuracy and budget without committing to subscriptions.
Finally, rigorous testing is essential. Use golden reference datasets, and tweak one variable at a time - such as chunk size, embedding models, or the number of neighbors - to pinpoint what enhances performance. Combine automated metrics with human evaluation to catch subtleties that algorithms might overlook. This methodical approach reinforces the fundamental steps of claim detection, evidence retrieval, and verification, ensuring a robust fact-checking system.
Challenges and Evaluation Benchmarks
Common Fact-Checking Challenges
Fact-checking systems face plenty of hurdles in practice. One of the biggest issues is source reliability - deciding whether to trust human-written documents, reference databases, search results, or even the AI model's internal knowledge. These sources aren’t always interchangeable, which complicates the process. Then there’s the matter of computational costs. Automated evaluations can get pricey, running around $0.02 per atomic claim.
Another tricky problem is the cascading effect of early hallucinations. Once errors creep in, they can snowball into larger inaccuracies. Adding to that, models often lack self-awareness about their own knowledge gaps. The numbers are troubling: on the Snowball dataset, error rates climb above 80% for LLaMA-2 and hit 65.5% for GPT-4.
Keeping up with rapidly changing information is another sticking point. Fact-checking frameworks struggle with this because they have limited access to real-time data. Scalability is also a major concern. For example, evaluating 6,500 AI-generated outputs with human reviewers would cost around $26,000, making it an impractical solution for the sheer volume of content these models produce. To make matters worse, research papers often rely on different benchmarks, making it tough to compare the effectiveness of various frameworks.
These challenges highlight why precise evaluation metrics are so important, as detailed below.
Key Evaluation Metrics
Assessing how well fact-checking frameworks perform requires a mix of metrics. Precision measures how accurately claims are labeled as true or false, while recall evaluates how well the framework identifies all factual errors within a document. Coverage ensures that responses include every key fact from trusted sources, and no-contradiction checks that responses don’t conflict with source material or widely accepted knowledge. For real-world use, latency is critical - response times for some frameworks range from 2.8 to 4.1 seconds.
Modern benchmarks like the FACTS Leaderboard Suite, introduced in late 2025, assess factuality across four areas: multimodal (image-based), parametric (internal knowledge), search (web tool usage), and grounding (document-based). Another tool, the SAFE evaluator, breaks down responses into individual facts, verifying them through search queries. It aligns with human annotators 72% of the time and even outperforms them in 76% of disagreement cases - all while being over 20 times cheaper than human crowdsourcing. For budget-conscious setups, smaller models like MiniCheck-FT5 deliver GPT-4-level accuracy at a fraction of the cost - 400 times less, to be exact.
To get the most accurate results, use a combination of automated metrics and human evaluations. This approach captures subtleties that algorithms might miss. Additionally, applying tools like Expected Calibration Error (ECE) ensures that confidence scores align with actual accuracy.
Conclusion
After exploring the processes of claim extraction, evidence retrieval, and verification, one thing is undeniable: the demand for effective fact-checking systems has never been greater. According to the 2024 World Economic Forum Global Risk Report, misinformation and disinformation rank as the most dangerous short-term global risks. Additionally, a significant 74% of U.S. adults express concern that AI might make spreading false information even easier. As LexisNexis aptly states:
"AI is not able to make complex judgements about the truthfulness of its created statements and articles".
Fortunately, advancements in verification frameworks have made automated fact-checking not only feasible but also affordable. Specialized models have slashed verification costs - up to 766 times cheaper - and achieved GPT-4–level accuracy while reducing costs by 400 times. This shift makes high-quality fact-checking accessible to a much broader audience.
Tools like NanoGPT simplify the adoption of these frameworks with their flexible pay-as-you-go pricing. This model allows organizations to experiment with a range of fact-checking solutions without the burden of subscription fees. NanoGPT also supports critical evidence retrieval workflows while safeguarding data privacy, making it a practical choice for businesses looking to balance efficiency and security.
The path forward is clear: combining automation with human oversight is the most effective way to tackle issues like hallucinations in AI-generated content. Start with smaller, cost-efficient models for high-volume tasks, use confidence thresholds to trigger more resource-intensive searches when needed, and always rely on verified external data sources to bolster accuracy. As Cathy Li from the World Economic Forum highlights:
"AI is not a villain in this story. It also plays a crucial role in combating disinformation and misinformation".
FAQs
How do fact-checking frameworks enhance the reliability of AI-generated content?
Fact-checking frameworks play a key role in improving the accuracy of AI-generated content. By cross-checking claims against reliable data sources or reference materials, these systems help ensure the information provided is grounded in truth. They rely on advanced tools such as customizable verification systems, graph-based reasoning, and unified evaluation approaches to detect and correct errors or misinformation.
One of their critical functions is addressing hallucinations - situations where AI produces false or fabricated details. By comparing AI outputs with verified evidence, these frameworks help deliver more precise and reliable results, making AI tools a safer and more trustworthy option for users.
What are the main steps to fact-check AI-generated content?
Fact-checking AI-generated content requires a methodical approach to ensure the information is accurate and dependable. The process begins by breaking the text into specific claims that can be individually analyzed. Each claim is then transformed into a search query to find supporting or contradictory evidence, either from external sources or the AI model’s internal knowledge.
Once the evidence is gathered, a verification step comes into play. This typically involves using AI tools or classifiers to evaluate the evidence and judge the truthfulness of each claim. Afterward, the findings are compiled into an overall credibility score. In some cases, a human reviewer steps in to double-check and validate the results.
This structured approach helps ensure AI-generated outputs are grounded in evidence, with clear metrics for confidence. It’s a key step in building trust and accountability in the use of AI systems.
Why is human oversight crucial in automated fact-checking systems?
Human involvement plays a crucial role in automated fact-checking because AI systems, on their own, lack the ability to fully grasp context, maintain transparency, or uphold accountability. While AI can sift through enormous amounts of data efficiently, it often falters when faced with nuanced decisions or ambiguous situations that demand human judgment.
By integrating human expertise, AI findings can be validated, errors minimized, and trust in the process reinforced. Specialists bring their knowledge to verify evidence, provide insights specific to their field, and address any shortcomings in the AI's logic. This partnership ensures that fact-checking systems stay dependable, precise, and relevant to the complexities of the real world.