Gradient Clipping in RNN Training: Why It Matters
Gradient clipping is a simple yet effective method to prevent exploding gradients during the training of Recurrent Neural Networks (RNNs). Exploding gradients can destabilize training, causing loss values to spike or result in NaN errors. This occurs because RNNs repeatedly multiply weight matrices during backpropagation, which can exponentially amplify gradients, especially in long sequences.
Here’s what gradient clipping does and why it’s important:
- Exploding Gradients: When gradients grow too large, they can destabilize weight updates, leading to erratic training behavior.
- How Clipping Works: Gradient clipping scales down gradients exceeding a set threshold, ensuring updates remain stable without altering their direction.
- Preferred Method: Clipping by norm is widely used as it maintains the gradient’s overall direction while capping its magnitude.
- Implementation: Add clipping after the backward pass (
loss.backward()) and before the optimizer step (optimizer.step()).
For most RNN tasks, start with a clipping threshold of 1.0 and monitor gradient norms to adjust as needed. This technique is especially critical for long-sequence tasks like text generation or speech recognition, where instability risks are higher.
Exploding Gradients: Mechanics and Impact
How Exploding Gradients Occur
Recurrent Neural Networks (RNNs) rely on reusing the same weight matrix ($W_{hh}$) across time steps. This repeated use means the matrix is multiplied by itself repeatedly, which can exponentially amplify gradients. Unlike feedforward networks, where each layer has unique weights, RNNs apply the same transformation at every time step. Mathematically, this is like raising the matrix to the power of the sequence length.
Here’s the catch: if the largest eigenvalue of $W_{hh}$ is even slightly greater than 1.0, gradient norms can grow exponentially during backpropagation. For instance, in a sequence with 1,000 tokens, the gradients undergo over 1,000 multiplications. This can easily lead to exploding gradients. Keeping an eye on key training metrics can help identify this issue early.
Symptoms to Watch For
One of the clearest signs of exploding gradients is when the loss suddenly spikes or starts returning NaN or Inf values. This happens when weights grow so large that they exceed the hardware's representational limits. At this point, the model essentially gets stuck and outputs NaN for all inputs. The rapid growth of gradient norms not only destabilizes the loss but also causes erratic weight updates, erasing any progress the model has made.
"Clipping the output gradients proved vital for numerical stability; even so, the networks sometimes had numerical problems late on in training, after they had started overfitting on the training data." - Alex Graves, Generating Sequences With Recurrent Neural Networks
Another, less obvious, warning sign is a high L2 gradient norm before gradient clipping is applied. Monitoring these pre-clipped norms can reveal exponential growth over training steps, often before the loss visibly diverges. This issue is closely tied to the weight-sharing mechanism in RNNs, making them particularly vulnerable.
Why RNNs Are Especially Prone to This Problem
The core reason RNNs are so susceptible lies in weight tying. Unlike Convolutional Neural Networks (CNNs) or Multilayer Perceptrons (MLPs), where each layer has its own set of weights, RNNs reuse the same weights across all time steps. As a result, gradients pass through the same transformation hundreds or even thousands of times, making the model highly sensitive to the scale of $W_{hh}$.
Even a slight increase above 1.0 in the largest eigenvalue can have a massive impact. This is particularly problematic for tasks like language modeling or speech recognition, where sequences often exceed 1,000 tokens. In such cases, the loss landscape becomes highly irregular, with sharp changes that can cause the optimizer to take erratic steps, undoing substantial progress in a single update. These challenges highlight the importance of implementing gradient clipping when training RNNs to maintain stability.
sbb-itb-903b5f2
Gradient Clipping for Neural Networks | Deep Learning Fundamentals
How Gradient Clipping Works
Gradient Clipping Methods: Clip by Value vs. Clip by Norm
Gradient clipping works like a control mechanism for your model's weight updates, similar to how a speed limiter works on a car. After backpropagation calculates the gradients but before the weights are updated, gradient clipping steps in to scale down any excessively large gradients. Here's the key idea: even when gradients become too large (often referred to as "exploding gradients"), they still point in the right direction. The problem lies in their magnitude, not their direction. As researcher Michael Brenndoerfer explains:
"The fix, therefore, is not to change the direction but to limit the length."
This distinction - keeping the direction while controlling the size - is what underpins the two main approaches to gradient clipping.
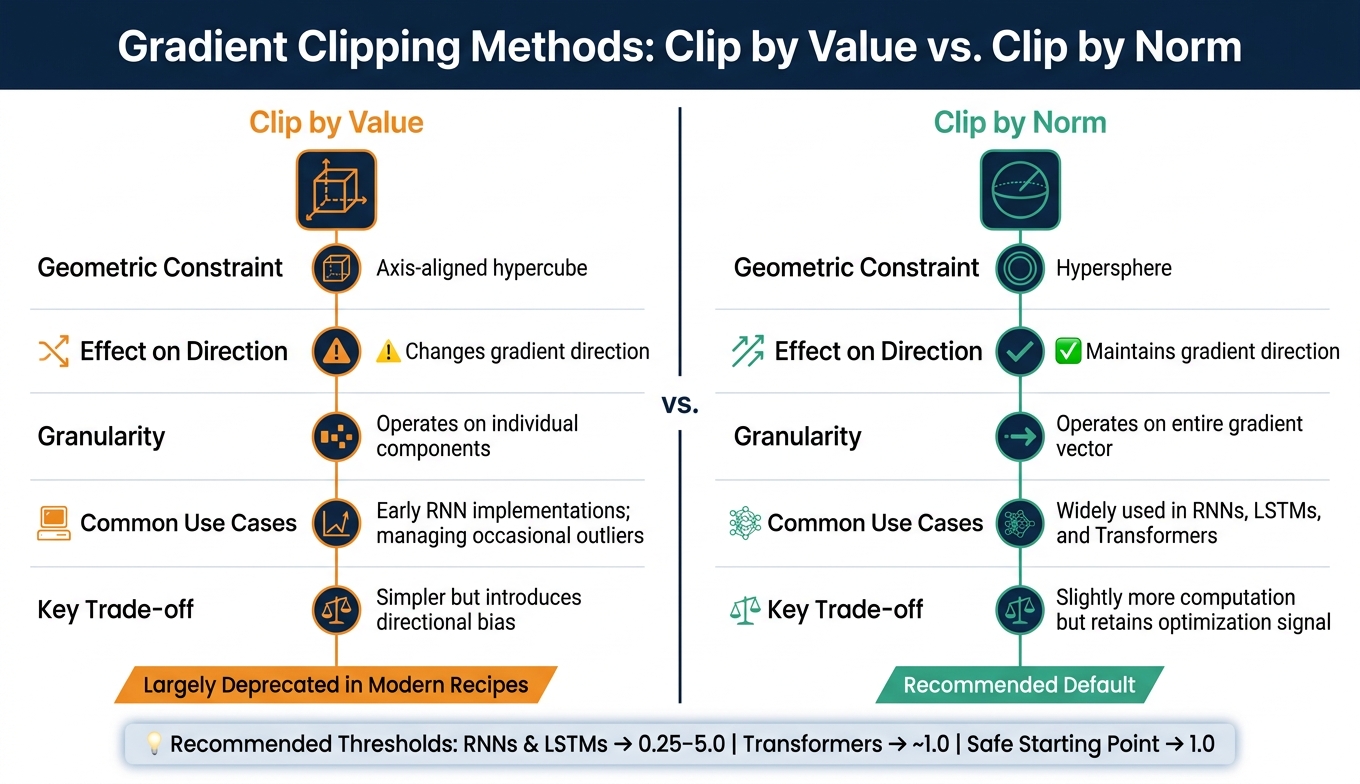
Clipping by Value
Clipping by value handles each component of the gradient vector separately. Essentially, every element is restricted to a predefined range, such as [-τ, τ]. If a component exceeds this range, it is adjusted to the nearest boundary.
While this method is straightforward and can help manage occasional extreme spikes, it introduces a drawback: the relative proportions of the gradient components are altered. This changes the gradient's direction, which can disrupt the optimization process. Because of this, value clipping is rarely used in modern training workflows.
Clipping by Norm
Clipping by norm takes a more holistic approach, treating the gradient as a single vector. If the gradient's overall L2 norm (essentially its length) exceeds a threshold τ, the entire vector is scaled down uniformly by a factor of τ/|g|. This ensures the gradient's direction remains intact while capping its magnitude.
Preserving direction is critical for maintaining the optimizer's effectiveness. In practice, many architectures adopt a global norm threshold of 1.0, while specific models like RNNs and LSTMs often use thresholds between 0.25 and 5.0.
Comparing the Two Clipping Methods
| Feature | Clip by Value | Clip by Norm |
|---|---|---|
| Geometric Constraint | Axis-aligned hypercube | Hypersphere |
| Effect on Direction | Changes gradient direction | Maintains gradient direction |
| Granularity | Operates on individual components | Operates on the entire gradient vector |
| Common Use Cases | Early RNN implementations; managing occasional outliers | Widely used in RNNs and Transformers |
| Key Trade-off | Simpler but introduces bias | Slightly more computational effort but retains optimization signal |
In most modern RNN training setups, clipping by norm is the preferred method. It ensures the optimization process remains stable by preventing gradients from growing uncontrollably, all while preserving the descent direction that drives effective learning.
Next, we’ll explore how to incorporate these clipping techniques into your training loop.
How to Implement Gradient Clipping in RNN Training
Now that you understand how clipping by norm works, let’s walk through how to integrate it into your training loop.
Choosing a Clipping Method and Threshold
For most scenarios, clipping by norm is the go-to method. As Alexander Rocha, Founding Engineer at ZeroEntropy, explains:
"Norm clipping is the default; value clipping is essentially deprecated in modern recipes."
Start with a threshold of 1.0. Adjust this value only if you're working with very long sequences. If clipping activates during 5–10% of your training steps, it's a sign to reduce the learning rate. If clipping occurs on more than 50% of steps, you might need to increase the threshold.
Adding Clipping to Your Training Loop
To effectively apply gradient clipping, do it right after loss.backward() and before optimizer.step(). If you clip gradients after the optimizer step, it won’t have any effect because the gradients will have already been used to update the model's weights.
Here’s how you can implement it in PyTorch using clipping by norm:
optimizer.zero_grad()
loss = model(inputs, targets)
loss.backward()
# Clip gradients after backward pass, before optimizer step
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
For mixed precision training using PyTorch’s GradScaler, you’ll need to unscale the gradients before clipping:
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
scaler.step(optimizer)
scaler.update()
Tracking and Debugging Gradient Clipping
The clip_grad_norm_ function not only clips gradients but also returns their L2 norm before clipping. This can be a useful diagnostic tool to monitor model stability. You can log this value at every training step:
total_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
clipping_activated = total_norm > 1.0 # Indicates if clipping was applied
Tracking the pre-clip gradient norm can provide early warnings about instability. Research from tutorialQ highlights that gradient norms often spike 10–50 steps before a loss spike, giving you time to intervene. A good practice is to flag steps where the norm exceeds three times the rolling 100-step average.
For better insights, log these norm values to visualization tools like TensorBoard or Weights & Biases. This allows you to compare gradient behaviors across experiments. If you notice consistently low norms (e.g., <1e-5), it may signal vanishing gradients, which you can address by adjusting initialization or adding residual connections.
| Observation | Likely Cause | Action |
|---|---|---|
| Clipping fires on >50% of steps | Threshold too low or learning rate too high | Raise max_norm or reduce the learning rate |
| Clipping almost never fires | Threshold too high | Lower max_norm for better gradient control |
| Norm spikes suddenly | Bad data batch | Skip the batch or reduce the learning rate |
| NaN gradients | Numerical overflow (fp16) | Use loss scaling or switch to bfloat16 |
| Norm consistently < 1e-5 | Vanishing gradients | Check initialization or add residuals |
Tuning Gradient Clipping for Better RNN Performance
Tuning Clipping Thresholds Alongside Other Hyperparameters
Gradient clipping works closely with hyperparameters like learning rate, batch size, and sequence length. For example, a higher learning rate amplifies gradient magnitudes, often requiring a lower clipping threshold to maintain stability and avoid overshooting the loss minimum. If you notice gradients being clipped in more than 50% of training steps, it’s a sign the learning rate might be too aggressive. In such cases, reduce the learning rate incrementally (e.g., by 10%) while keeping the clipping threshold constant.
For RNNs and LSTMs, typical thresholds fall between 0.25 and 5.0, whereas Transformer models generally hover around a threshold of 1.0. Razvan Pascanu, a researcher known for his work on exploding gradients, observed:
"In our experiments we have noticed that for a given task and model size, training is not very sensitive to this [gradient norm] hyperparameter and the algorithm behaves well even for rather small thresholds."
A good starting point is a threshold of 1.0. From there, monitor your gradient norm logs and adjust only if the data suggests it’s necessary. This approach becomes even more critical in tasks involving long sequences, which put additional strain on gradient stability.
Gradient Clipping for Long-Sequence Tasks
Long-sequence tasks - like character-level text generation, speech recognition, or machine translation - pose unique challenges for gradient stability. When using Backpropagation Through Time (BPTT) on sequences exceeding 200 tokens, even small gradient excesses can snowball, significantly affecting earlier steps.
In such cases, gradient clipping becomes essential. Alex Graves, a prominent researcher in sequence generation with RNNs, highlighted its importance:
"Clipping the output gradients proved vital for numerical stability; even so, the networks sometimes had numerical problems late on in training, after they had started overfitting."
For long-sequence tasks, you might experiment with layer-specific thresholds. For example, output layers can often handle a wider gradient range (e.g., [-100, 100]), while hidden LSTM layers benefit from tighter bounds (e.g., [-10, 10]) to prevent instability from spreading. However, global-norm clipping is often the preferred default because it reduces gradient magnitude without altering its direction. If you're looking to experiment with these settings, the next section introduces NanoGPT as a practical tool for testing.
Using NanoGPT for RNN Experimentation
NanoGPT is a convenient platform for testing gradient clipping configurations and other training strategies. It allows you to experiment with models like GPT or Llama on text generation tasks, providing insights into how sequence length and architecture affect gradient dynamics. This can save you time and resources before committing to larger-scale training runs.
One of NanoGPT’s advantages is that it stores data locally on your device, which is especially useful when working with proprietary datasets. It offers a low-barrier environment to test real-world scenarios, helping you fine-tune gradient clipping strategies and ensure stable training throughout your experiments. For researchers and developers, this makes it a valuable tool for refining model behavior effectively.
Conclusion
Gradient clipping is a practical and effective tool to stabilize RNN training by addressing the issue of exploding gradients. As Ian Goodfellow, Yoshua Bengio, and Aaron Courville explain:
"When the traditional gradient descent algorithm proposes to make a very large step, the gradient clipping heuristic intervenes to reduce the step size to be small enough that it is less likely to go outside the region where the gradient indicates the direction of approximately steepest descent."
Why does this matter? The math makes it clear. In a 100-timestep sequence, even a small gradient amplification factor of 1.1 per step can compound into a staggering 13,781x increase in magnitude. This kind of runaway growth can lead to NaN loss values, completely derailing your training process.
Among the various methods, clipping by global norm stands out as the go-to choice for most tasks. It scales the entire gradient vector uniformly, maintaining its direction while capping its magnitude. A threshold between 1.0 and 5.0 is generally effective for RNNs and LSTMs, with 1.0 being a safe starting point. However, it’s important to note that while gradient clipping addresses exploding gradients, it doesn’t solve vanishing gradients. For that, architectural solutions like LSTMs or GRUs are necessary.
The key to success lies in monitoring. Keep track of gradient norms before clipping, observe how often clipping is triggered, and treat the threshold as a tunable hyperparameter. Combine this with careful adjustments to your learning rate and sequence length, and you’ll create a stable and predictable training loop that can handle even the most challenging long-sequence tasks.
FAQs
Does gradient clipping slow down learning?
Gradient clipping is designed to prevent training instability without disrupting the usual learning process. It steps in only during rare instances when gradient values spike, ensuring these outliers don’t derail the training. This means under normal circumstances, it doesn’t interfere with optimization. That said, setting the clipping threshold too low can unintentionally limit useful updates, which could slow progress. In essence, gradient clipping is a lightweight safeguard to stabilize training and avoid extreme loss fluctuations, not a mechanism that inherently restricts performance.
How do I choose the right clip norm for my sequence length?
Selecting the right clip norm often requires trial and error. A good starting point is a threshold between 0.25 and 5.0, which you can tweak based on how your training behaves.
Keep an eye on gradient norms during training. If they almost never exceed the threshold, consider lowering it. On the other hand, if gradients frequently hit the limit, you might want to make clipping less aggressive. The goal is to find a sweet spot where clipping only kicks in during occasional spikes - this helps maintain stability without losing valuable gradient information.
Should I clip gradients with Adam and mixed precision too?
Gradient clipping is essential, even when using the Adam optimizer and mixed precision. While Adam's adaptive scaling can manage ongoing parameter differences, it doesn't address sudden spikes in gradients. Clipping acts as a safeguard, providing immediate protection and working alongside Adam to maintain stability.
With mixed precision, it's crucial to unscale the gradients before applying clipping. In PyTorch, this involves using scaler.unscale_() prior to calling torch.nn.utils.clip_grad_norm_(). This ensures the clipping threshold remains valid and helps avoid catastrophic updates during training.