How GraphQL Simplifies AI Model Integration
GraphQL is changing how AI models interact with APIs by solving common challenges like over-fetching, under-fetching, and inefficiencies in traditional REST APIs. Its single-endpoint structure, precise data fetching, and schema-driven design allow AI systems to request only the exact data they need, reducing costs, token usage, and errors. Key benefits include:
- Single Endpoint: Consolidates multiple data sources into one endpoint, reducing complexity.
- Precise Data Fetching: Fetches only required fields, cutting payload sizes by 30–50%.
- Schema-Driven Development: Strongly typed schemas ensure data consistency and reduce ambiguity.
GraphQL also supports introspection, enabling AI models to dynamically explore API structures and relationships, simplifying integration without relying on external documentation. Real-world examples, like Advisor360° and Oracle Database 26ai, show how GraphQL enhances AI workflows by improving data accuracy, reducing fabrication risks, and optimizing performance.
Quick Example: Advisor360° used GraphQL to fix data gaps in AI-generated meeting agendas, reducing fabrication rates caused by incomplete CRM data. Meanwhile, NanoGPT showcases how a single endpoint can manage access to over 900 AI models efficiently.
GraphQL's ability to deliver precise, structured data makes it a strong choice for AI model integration, saving time, reducing errors, and lowering costs.
An AI-enabled Supergraph: From Text-to-Query to Conversational Agents
sbb-itb-903b5f2
Key GraphQL Features for AI Model Integration
GraphQL offers three standout features that make it an excellent choice for integrating AI models: a single endpoint architecture, precise data fetching, and schema-driven development. These features tackle many of the challenges AI systems encounter when working with traditional APIs.
Single Endpoint Architecture
GraphQL simplifies data access by consolidating multiple data sources into a single endpoint. This eliminates the hassle of managing multiple connections or URLs, which is often required with REST APIs. Instead of making 3–5 separate calls to gather data like REST, GraphQL consolidates everything into a single request.
This unified setup allows AI models to discover available data types and relationships at runtime without relying on external documentation. The result? Less orchestration complexity and faster response times - key benefits for real-time AI applications. By streamlining the data retrieval process, GraphQL ensures that AI models can access the precise information they need without unnecessary overhead.
Precise Data Fetching
GraphQL takes its single endpoint design a step further by allowing users to request only the specific fields they need. This precision eliminates the inefficiencies seen in REST, where unneeded data often inflates payload sizes. By reducing token usage and bandwidth waste, GraphQL optimizes both cost and performance.
"GraphQL's built-in relationship handling and query structure eliminate guesswork for AI models. The graph defines clear paths between data types, ensuring AI agents execute operations in the correct sequence without complex prompt engineering." - Zakk Smail, Fuuz
Studies predict that by 2026, GraphQL’s single-request model could reduce payload sizes by 30% to 50% compared to REST. This efficiency not only cuts costs but also lowers latency, making GraphQL a strong choice for AI workloads where speed and accuracy are critical.
Schema-Driven Development
GraphQL's schema-driven design adds another layer of reliability by formalizing data contracts. Its strongly typed schema explicitly defines the data type for each field - whether it's a Float, Enum, String, or a custom object. This clarity removes the guesswork often associated with REST, where data types are inferred from JSON responses. By doing so, it reduces the chances of AI models misinterpreting data or generating errors due to unexpected formats.
GraphQL also self-documents its API through field descriptions and directives like @aiHint, providing AI agents with clear instructions without extra prompt engineering. Organizations adopting GraphQL have reported an 82% boost in developer productivity and overall satisfaction.
"If REST was the API for human-readable systems, GraphQL is the API for machine-reasonable ones." - Michael Lukaszczyk, CEO, Hygraph
GraphQL vs REST for AI Models
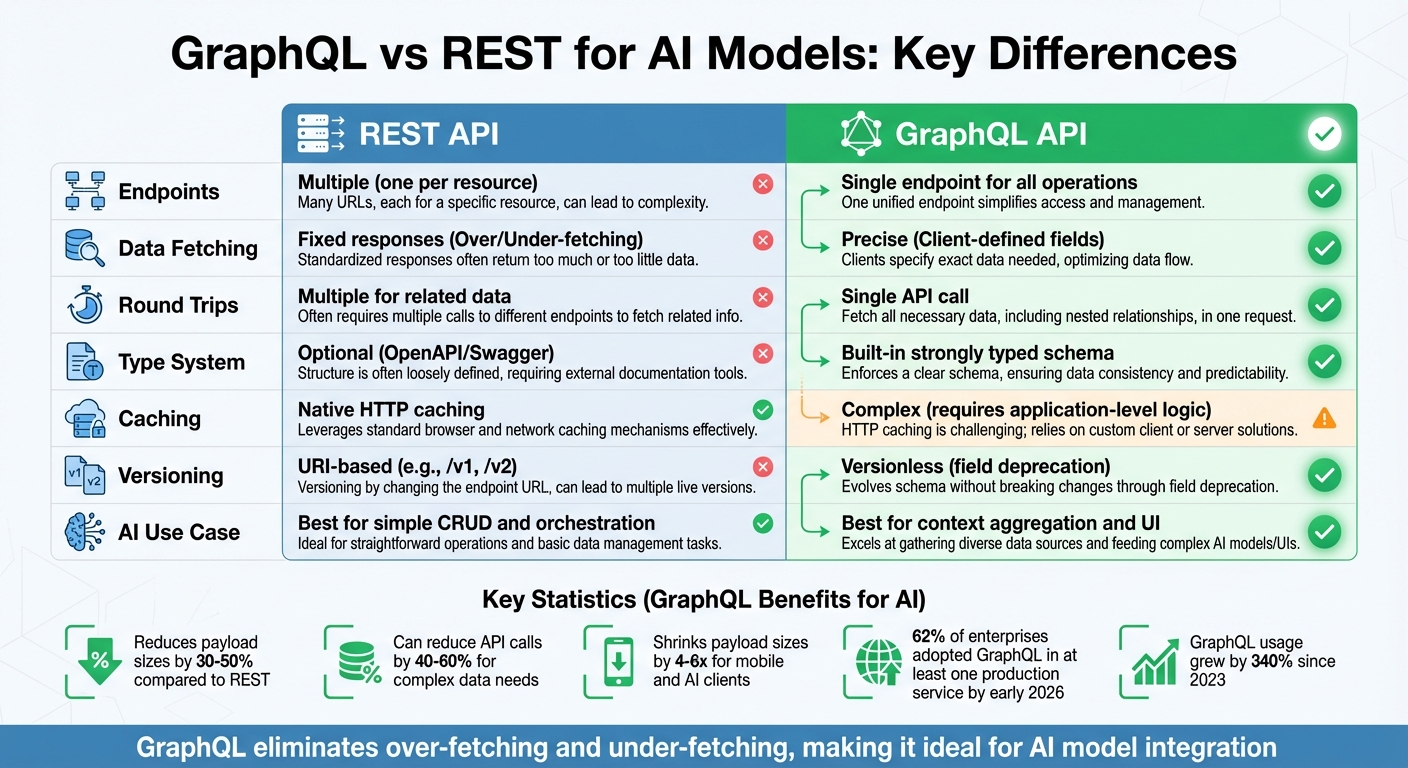
GraphQL vs REST API Comparison for AI Model Integration
When integrating AI models, the choice between GraphQL and REST can significantly impact performance and efficiency. REST has long been the go-to option, but GraphQL offers solutions to some of REST's common challenges, making it a strong contender for AI applications. Here's how the two compare.
Avoiding Over-Fetching and Under-Fetching
REST APIs often return static responses, which can lead to two major issues. Over-fetching happens when you receive extra fields you don't need, wasting bandwidth and processing power - problems that can be especially costly for AI models. On the other hand, under-fetching requires making multiple requests to gather related data, which slows down response times.
GraphQL solves this by allowing AI models to request only the specific fields they need. For mobile and AI clients, this precision can shrink payload sizes by 4-6x compared to REST, with typical bandwidth savings ranging from 30% to 50% in constrained environments. This not only boosts efficiency but also cuts costs by reducing unnecessary token usage.
"GraphQL is not just nicer. It's the right tool for LLM development." - Madhan Karthik Ramasamy, Principal Technologist, GoPenAI
Simplified Query Predictability
GraphQL's strongly typed schema acts as a clear contract between clients and servers. It defines field names, argument structures, and return types explicitly, reducing the chances of AI models making incorrect assumptions or running into errors. This is particularly helpful for AI agents that generate their own queries.
GraphQL also includes an introspection feature, which allows AI systems to explore the API's schema, types, and relationships. This enables them to auto-generate queries without needing external documentation - something REST can't achieve as seamlessly. By early 2026, about 62% of enterprises had adopted GraphQL in at least one production service, with usage growing by more than 340% since 2023.
REST vs GraphQL Comparison Table
The following table highlights key differences between REST and GraphQL:
| Metric | REST APIs | GraphQL |
|---|---|---|
| Endpoints | Multiple (one per resource) | Single endpoint for all operations |
| Data Fetching | Fixed responses (Over/Under-fetching) | Precise (Client-defined fields) |
| Round Trips | Multiple for related data | Single API call |
| Type System | Optional (OpenAPI/Swagger) | Built-in strongly typed schema |
| Caching | Native HTTP caching | Complex (requires application-level logic) |
| Versioning | URI-based (e.g., /v1, /v2) | Versionless (field deprecation) |
| AI Use Case | Best for simple CRUD and orchestration | Best for context aggregation and UI |
For scenarios involving complex data needs, GraphQL can reduce the number of API calls by 40% to 60%. This makes it an excellent choice for AI models that need to gather data from various sources to generate prompts or responses efficiently.
How GraphQL Schema Introspection Improves AI Model Usability
GraphQL's introspection feature transforms the way AI models interact with APIs. Instead of depending on external documentation - which can quickly become outdated - AI systems can query the API directly to uncover its full structure at runtime. This includes details like types, fields, relationships, and arguments. By enabling this level of runtime discovery, GraphQL allows AI systems to navigate and understand the API autonomously. The schema's inherent clarity further boosts the reliability of AI models.
Self-Documenting APIs with Strong Typing
GraphQL schemas are naturally self-documenting. Each field and type can include description strings, embedding instructions directly into the schema. For example, descriptions might include notes like "Do not sum across portfolios" or "Internal use only", providing AI agents with essential context. The strong typing system in GraphQL also acts as a dependable framework for reasoning. For instance, if a field is defined as an Enum like RiskProfile.CONSERVATIVE, the AI immediately knows the set of valid values, reducing ambiguity and helping to prevent errors like hallucinations.
A real-world example of this was seen in April 2026, when Advisor360° tackled a major issue with AI-generated wealth management meeting agendas. When CRM data was incomplete, the AI had a 100% fabrication rate, inventing false but plausible client details. Venkat Peri and his team solved this by introducing a "trust contract" pattern within their GraphQL schema. They added a __trust sidecar field that flagged missing data with coverage: ABSENT, ensuring the AI could distinguish between valid and absent information.
This built-in documentation and clarity significantly reduce the complexity of prompt engineering, as explained below.
Reduced Need for Prompt Engineering
GraphQL schema introspection also streamlines how developers work with AI models. Custom directives, such as @aiHint, can embed structured metadata into fields - like units of measurement, aggregation rules, or safety constraints. These annotations are automatically retrieved during introspection, ensuring consistent application of guidelines without extra effort.
In addition, the machine-readable format of GraphQL introspection exposes all API capabilities, effectively turning the schema into a built-in tool definition. This eliminates much of the "glue code" typically required for REST APIs, making integration smoother and more efficient. By embedding critical instructions directly into the schema, developers can focus less on manual prompt engineering and more on building effective solutions.
Practical Applications of GraphQL in AI Model Integration
GraphQL's capabilities have reshaped how industries integrate AI workflows, offering efficiency and precision in handling complex data. Let’s dive into how this is playing out in practice.
Case Study: Oracle Database 26ai and GraphQL
In January 2026, Oracle introduced GraphQL support within Oracle Database 26ai, making it easier to handle relational queries using GraphQL syntax. This update included a built-in GraphQL parser and the graphql() table function, enabling developers to query relational data without writing custom resolvers.
The standout feature here is the use of JSON-relational duality views, which combine the structure of relational databases with the flexibility of JSON. Developers can query normalized relational data as hierarchical JSON using GraphQL. For example, by creating a team_dv view, they can nest driver data into team objects using directives like @insert, @update, and @delete. The database takes care of inferring joins based on foreign keys, presenting the data as hierarchical JSON (e.g., {"_id": 301, "name": "Red Bull", "driver": [...]}), all without duplicating the underlying data.
Oracle also ensures that GraphQL queries integrate seamlessly with its existing SQL diagnostic tools, such as AWR, SQL Monitor, and SQL Tracing. This allows developers to fine-tune their GraphQL queries using familiar performance optimization techniques.
"Through Oracle Database Support for GraphQL Queries, you can effortlessly create, introspect, and query complex data objects without sacrificing the performance, scalability, or optimization provided by relational databases".
This integration underscores GraphQL's ability to deliver structured, efficient data access while maintaining the strengths of relational databases.
Industrial Use Case: Fuuz Intelligence Platform

Fuuz, an industrial intelligence platform, offers another compelling example of GraphQL in action. In August 2024, Fuuz adopted GraphQL to unify fragmented industrial data sources, particularly for equipment performance analysis. Previously, AI systems required five separate REST calls to gather data from endpoints like /api/equipment, /sensors, /maintenance, /production, and /quality. With GraphQL, a single query retrieves a comprehensive view of equipment status, sensor trends, and maintenance history.
This shift reduced confusion by clearly defining relationships between data points. For instance, AI systems now link sensor variability directly to defect rates, thanks to GraphQL schemas that establish explicit connections between data types.
Fuuz also normalizes data from various sources - such as Modbus sensors, OPC-UA devices, MQTT feeds, and ERP systems - into a unified data graph accessible via GraphQL. To ensure security, the platform implemented role-based access control (RBAC) within the GraphQL context. This means operators can view real-time data, while executives access broader performance trends, all within the same system.
Efficiency Gains in AI Workloads with AWS GraphQL
AWS AppSync illustrates how GraphQL can streamline AI workloads. By replacing multiple microservice calls with a single query, AWS AppSync reduces both CPU usage and network overhead.
This targeted data fetching ensures AI models get only the relevant, structured information they need, avoiding the inefficiencies of processing unnecessary fields. These enhancements align perfectly with the earlier discussion of GraphQL’s ability to optimize data delivery for AI systems.
NanoGPT: Simplified AI Model Access
NanoGPT demonstrates how a unified API setup can make accessing AI models much simpler, reflecting the streamlined efficiency often associated with GraphQL.
Through NanoGPT, developers can access 916 AI models using just one endpoint: https://nano-gpt.com/api/v1. This setup eliminates the need to juggle multiple integrations for models like ChatGPT, Deepseek, Gemini, Flux Pro, Dall-E, and Stable Diffusion. Instead, developers can easily query details about model capabilities and pricing using the /v1/models?detailed=true endpoint. It's a straightforward way to manage various AI tools without the usual complexity, offering a practical solution for developers.
Privacy-First AI Model Access
NanoGPT places a strong focus on security and privacy, giving developers access to models with advanced confidentiality features.
For example, NanoGPT supports Trusted Execution Environment (TEE) technology, which ensures secure and verifiable computing. Developers can access TEE-backed models and even request attestation reports through the /api/v1/tee/attestation endpoint to confirm the integrity of the hardware environment.
The platform also uses Bring Your Own Key (BYOK) encryption, allowing users to store data securely. By adding their encryption key through the x-encryption-key header, users ensure that only they can access their encrypted data. For added privacy, developers can set a retention_days value of 0 for specific requests, ensuring no interaction data is stored by the platform. These features make NanoGPT an appealing option for privacy-conscious users.
Cost Efficiency with Flexible Pricing
NanoGPT doesn’t just prioritize security - it also helps developers manage costs effectively.
The platform operates on a pay-as-you-go model, requiring only a $1.00 minimum deposit (or $0.10 if using cryptocurrency). This setup is ideal for developers with sporadic or low-volume usage, avoiding the financial strain of fixed costs.
NanoGPT provides detailed pricing information through its API, helping developers make cost-effective decisions. For instance, Amazon Nova Micro 1.0 is priced at $0.04 per 1 million input tokens and $0.14 per 1 million output tokens, while Aion 1.0, a more advanced model, costs $4.00 per 1 million input tokens and $7.99 per 1 million output tokens. By using the ?detailed=true parameter with the /api/v1/models endpoint, developers can access up-to-date pricing and feature flags - such as vision or reasoning capabilities - ensuring they choose the best model for their needs.
Conclusion
GraphQL is transforming the way AI systems interact with APIs by offering interfaces that are easy for machines to navigate in real time. Unlike REST APIs, which are built with human readability in mind, GraphQL's self-describing schema allows AI agents to dynamically uncover capabilities and understand complex data structures - all without needing to rely on potentially outdated or incomplete external documentation.
The efficiency gains are just as noteworthy. GraphQL's use of selection sets ensures that only the required data fields are fetched, which avoids over-fetching and helps cut down on token usage and associated costs. Venkat Peri from Advisor360° captured this shift perfectly: "The context window is the new network bandwidth. Design your APIs accordingly".
"In the age of AI, structure matters. And GraphQL delivers structure, composability, and introspection like nothing else." – Stephen Spalding, July 3, 2025
This structured approach creates a solid foundation for AI reasoning and smooth integration. Strong typing further enhances this by ensuring data consistency, reducing ambiguity, and minimizing the risk of AI-generated errors. For example, when Advisor360° implemented schema-based trust signaling through GraphQL in April 2026, they successfully tackled issues like fabrication without needing to modify their underlying AI model or resort to additional prompt engineering.
A practical example of these principles in action is NanoGPT. With a single API endpoint, it offers access to 916 models. Developers can even retrieve detailed pricing and model capabilities using parameters like ?detailed=true. On top of that, NanoGPT supports Trusted Execution Environment (TEE) technology to safeguard user privacy and operates on a pay-as-you-go pricing model starting at just $0.10 - showing how GraphQL-inspired designs can simplify AI integration while keeping costs manageable.
GraphQL's ability to fetch precise data, enforce strong typing, and consolidate functionality into a single endpoint paves the way for streamlined and cost-efficient AI model integration, setting a new standard for how AI and APIs work together.
FAQs
How does GraphQL cut LLM token usage?
GraphQL helps cut down on token usage when working with large language models (LLMs) by allowing clients to request only the exact data fields they need. This approach avoids over-fetching unnecessary information, keeps response sizes smaller, and saves tokens - leading to reduced costs. By simplifying queries, GraphQL ensures smoother and more efficient communication between clients and AI models.
Is GraphQL introspection safe to expose?
Leaving GraphQL introspection enabled in production can pose a security risk. Why? It exposes schema details that attackers could exploit to find vulnerabilities or sensitive information within your system.
To strengthen your application's security, it's a good practice to disable introspection in production environments. This precaution limits the information available to potential malicious actors, reducing the chances of misuse. While introspection is helpful during development for debugging and understanding your schema, it's not something you want to leave open in a live, public-facing environment.
How do you cache GraphQL for AI workloads?
When dealing with AI workloads, caching in GraphQL can significantly boost performance and reduce latency. There are three main approaches to consider:
- Resolver-level caching: This method stores results for specific fields, reducing repetitive backend calls for the same data.
- Request-level caching: By batching repeated backend access, this technique helps streamline data retrieval.
- Operation result caching: Entire query responses are cached, allowing for reuse without re-executing the query.
These caching strategies not only enhance response times but also optimize resource usage, making them particularly effective when integrating AI models.