Guide to Traffic Anomaly Detection with AI
Traffic anomaly detection helps identify unusual patterns in network activity, like traffic spikes or unauthorized behavior, which could signal security risks or operational issues. Traditional tools often struggle with encrypted data and unknown threats, but AI offers a solution. By learning a network's behavior, AI can detect deviations in real-time, reducing response times and improving accuracy.
Key points:
- Types of anomalies: Volume (traffic spikes), protocol (unusual port use), temporal (odd timing), and behavioral (unexpected device activity).
- AI's role: Adapts to network changes, processes large data volumes, and reduces false positives.
- Detection methods:
- Unsupervised: Finds unknown threats without labeled data (e.g., clustering, autoencoders).
- Supervised: Pinpoints known threats using labeled datasets (e.g., SVM, LightGBM).
- Best practices: Combine methods for a balanced approach, preprocess data for quality, and use scalable systems for real-time detection.
AI-driven systems are reshaping network security by identifying both known and new threats, offering faster and more precise detection.
Detecting Network Anomalies with Machine Learning | Exclusive Lesson
sbb-itb-903b5f2
Main Approaches to Traffic Anomaly Detection
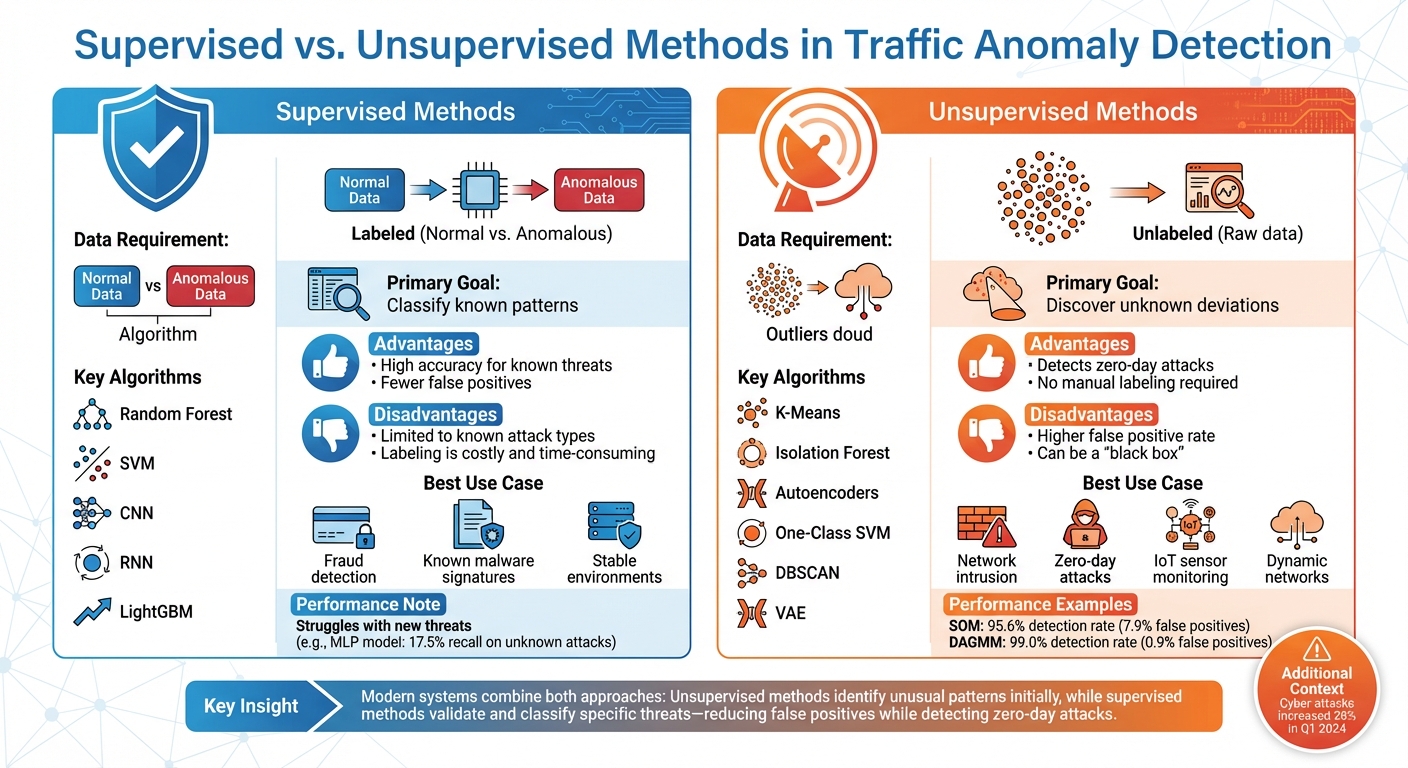
Supervised vs Unsupervised AI Methods for Traffic Anomaly Detection
AI-driven anomaly detection typically relies on two main approaches: supervised and unsupervised methods. Each has its unique strengths, and knowing when to apply them is key to spotting zero-day threats.
Unsupervised Methods
Unsupervised methods work without needing labeled examples of "bad" traffic. Instead, they focus on modeling what normal network activity looks like and flagging anything that strays too far from this baseline. This makes them particularly effective at identifying zero-day attacks - threats that have never been seen before.
Techniques like clustering (e.g., K-Means, SOM, DBSCAN) and density-based models (e.g., Isolation Forest, LOF) detect anomalies by identifying data points that don't fit into established clusters or are found in sparse regions. For instance, SOM achieved a 95.6% detection rate on the ISCX dataset for botnet identification, though it had a 7.9% false positive rate.
Deep learning has further advanced unsupervised detection. Models like autoencoders and Variational Autoencoders (VAEs) learn normal traffic patterns, flagging anomalies based on high reconstruction errors. An example is DAGMM, which achieved a 99.0% detection rate with only a 0.9% false positive rate on the KDD dataset.
"Unsupervised systems are able to detect unknown attacks, e.g. 0-day attacks. Remark that supervised systems are not good at this task."
– Alberto Miguel-Diez, Researcher, University of León
However, unsupervised methods aren't without flaws. They can produce more false positives, often flagging benign events like legitimate traffic spikes from marketing campaigns as anomalies.
While these methods excel at uncovering novel threats, supervised methods offer precision in identifying known attack patterns.
Supervised Methods
Supervised methods rely on labeled datasets that include examples of both normal and anomalous traffic. They are highly effective at identifying known threats with precision, making them ideal when detailed attack signatures and historical data are available.
Algorithms like LightGBM, SVM, and ensemble models are commonly used in supervised detection. Ensemble models, in particular, combine multiple algorithms through techniques like bagging and boosting to balance accuracy and minimize false positives and negatives. Deep learning also plays a role here: Convolutional Neural Networks (CNNs) can analyze traffic data transformed into 2D images to capture spatial patterns, while Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks are excellent at detecting temporal anomalies in time-series data.
Despite their accuracy, supervised methods have limitations. They depend heavily on high-quality labeled data, which can be both time-consuming and expensive to produce. Additionally, they struggle to detect new attack types that weren’t part of their training data.
"Machine learning-based fraud detection models can reduce expected financial losses by up to 52% compared to traditional rule-based methods."
– Financial Innovation Study
Unsupervised vs. Supervised Methods
Deciding between these two approaches depends on factors like the type of environment, data availability, and the nature of threats being addressed. Here's a quick comparison:
| Feature | Supervised Methods | Unsupervised Methods |
|---|---|---|
| Data Requirement | Labeled (Normal vs. Anomalous) | Unlabeled (Raw data) |
| Primary Goal | Classify known patterns | Discover unknown deviations |
| Algorithms | Random Forest, SVM, CNN, RNN | K-Means, Isolation Forest, Autoencoders, One-Class SVM |
| Advantages | High accuracy for known threats; fewer false positives | Detects zero-day attacks; no manual labeling required |
| Disadvantages | Limited to known attack types; labeling is costly | Higher false positive rate; can be a "black box" |
| Best Use Case | Fraud detection, known malware signatures | Network intrusion, zero-day attacks, IoT sensor monitoring |
Supervised learning works best in stable environments where historical attack data is well-documented, such as financial institutions needing precise fraud detection.
On the other hand, unsupervised learning is better suited for dynamic networks where new attack types frequently arise or when labeling data is impractical. With cyber-attacks reportedly rising by 28% in the first quarter of 2024, the ability to detect unknown threats without prior examples has become increasingly important.
Many modern systems now combine both approaches. Unsupervised methods are used to identify unusual patterns initially, with supervised methods - fine-tuned through human oversight - validating and classifying specific threats. This hybrid technique reduces false positives while retaining the flexibility to detect zero-day attacks.
Building an AI Anomaly Detection System
Creating an effective anomaly detection system requires meticulous data preparation and scalable deployment. This section dives into the process of turning raw data into actionable insights and deploying real-time models that handle large-scale operations seamlessly.
Data Preprocessing and Feature Engineering
Raw network data is often messy - it can include missing values, inconsistent formats, and extreme outliers. Cleaning and normalizing this data is step one. Interestingly, outliers should generally be kept, as they might represent anomalies.
Start by gathering telemetry from sources like NetFlow, sFlow, or IPFIX. These flow records are lightweight and fast, making them well-suited for large-scale monitoring. In contrast, Deep Packet Inspection (DPI) is slower and more resource-intensive. Address missing values and apply log transformations to highly skewed features like "Source Bytes" or "Duration" to make distributions more uniform.
Feature engineering plays a huge role in improving detection accuracy. Key features include protocol types, service flags, connection counts, and temporal metrics like inter-packet delays and packets per second. For TCP traffic, focus on SYN/ACK ratios and window size changes. For UDP traffic, look at source port entropy and packet size distributions. When dealing with encrypted traffic (like TLS 1.3), shift your attention to metadata, such as handshake timing patterns and certificate chain details, since payload data is inaccessible.
Handling high-dimensional data is another challenge. Network flows often include over 100 features, so dimensionality reduction techniques like Principal Component Analysis (PCA) are essential. PCA can shrink dimensionality by up to 10× while maintaining model performance. Retaining components that explain 95% of the variance can keep false negative rates under 2%.
Privacy is another critical factor. Before storing data, sensitive information must be de-identified. For example, some systems process 150 GB of network logs every 10 minutes using streaming platforms and machine learning services. In these cases, subscriber IDs are often encrypted deterministically, allowing secure re-identification for forensic purposes. To avoid API quota issues when using external de-identification services, microbatching can be a helpful strategy.
Since malicious traffic typically accounts for less than 1% of total traffic, resampling techniques like SMOTE (Synthetic Minority Oversampling Technique) or ADASYN can help balance your dataset and prevent the model from favoring normal behavior.
Deploying Real-Time Detection Systems
Once you've engineered robust features, the next step is deploying them in a way that ensures real-time anomaly detection with minimal delay. The goal is to build low-latency pipelines that can process massive data volumes without slowing down.
"Speed of detection means recognizing the anomaly (the attack traffic) instantaneously or within seconds, allowing automated mitigations to kick in or for operators to take action."
– Kentik DDoS Experts
Streaming architectures like Apache Kafka or Google Cloud Pub/Sub are excellent for high-throughput data ingestion. These platforms decouple data producers from consumers, ensuring smoother workflows. Once data is ingested, distributed processing frameworks like Apache Beam can extract features and generate predictions in real time. Adaptive baselining - where models adjust to daily and seasonal variations - helps reduce false positives compared to static thresholds.
A hybrid detection approach works best for deployment. Use unsupervised methods like k-means clustering or Isolation Forest to establish dynamic baselines, then flag outliers exceeding thresholds (usually three standard deviations from the mean). For periodic anomalies, such as DDoS attacks, preprocessing with Fast Fourier Transform (FFT) can reveal frequency-domain patterns that time-domain analysis might miss.
When an anomaly is detected, integrate the system with SIEM/SOAR platforms to enable immediate responses, such as automated IP blocking or rate-limiting. Modern systems often include AI advisors that let analysts query anomalies using natural language. For instance, you might ask, "What changed in BGP routing?" - a feature that helps combat alert fatigue.
Research shows that many organizations still take over an hour to detect DDoS attacks, while real-time AI systems aim to reduce this to near zero. To achieve this, collect telemetry directly from network hardware (like switches and access points) to avoid bottlenecks caused by external collectors or sampling loss. Storing data in ingestion-time partitioned tables can also speed up model retraining and data selection.
Finally, incorporate feedback loops where human validation checks flagged anomalies. This feedback should be used to refine the model, continuously improving accuracy and tuning thresholds.
"Real-time AI solutions have the biggest impact when approached with the end-goal in mind (How will this help us meet our business goals?) and the flexibility to adapt as needs change."
– Masud Hasan and Cody Irwin, Google Cloud
Evaluating AI Models for Anomaly Detection
Measuring the performance of AI models is crucial in anomaly detection. Without proper evaluation, it’s impossible to determine whether your system is effectively identifying threats or simply flooding your security team with false alarms. The key challenge lies in balancing thorough detection of anomalies with minimizing alert fatigue.
Model Evaluation Metrics
Once deployed, AI models need ongoing evaluation to ensure they are effectively identifying threats. This process starts with four fundamental metrics: True Positives (correctly flagged anomalies), True Negatives (normal traffic accurately identified), False Positives (normal traffic mistakenly flagged), and False Negatives (missed anomalies). These metrics form the foundation for calculating performance indicators.
- Precision measures how many flagged alerts are actually threats, using the formula: TP / (TP + FP).
- Recall determines how many real threats were detected, calculated as TP / (TP + FN). In security, recall often takes priority to avoid missing actual attacks, even if it means tolerating more false positives.
- The F1-score combines precision and recall into a single value: 2 × (Precision × Recall) / (Precision + Recall). This is especially useful for comparing models.
| Metric | Formula | What It Measures |
|---|---|---|
| Accuracy | (TP + TN) / (TP + TN + FP + FN) | Overall percentage of correct predictions |
| Precision | TP / (TP + FP) | Proportion of alerts that are real threats |
| Recall | TP / (TP + FN) | Proportion of actual threats detected |
| F1-Score | 2 × (Precision × Recall) / (Precision + Recall) | Balance between precision and recall |
Even models that perform well on paper can struggle in real-world situations. For instance, a Multi-Layer Perceptron (MLP) model tested on the CICIDS2017 dataset achieved near-perfect accuracy on known attacks. However, its recall dropped dramatically to 17.5% when faced with new, unknown threats. In contrast, a boundary-based unsupervised model like One-Class SVM demonstrated greater robustness in the same scenario, achieving an F1-score of 0.7575 compared to the MLP’s 0.2973.
"Anomaly detection models defining decision boundaries based only on benign data can be more robust to unseen attacks than supervised models relying on known attack patterns." – Zhaoyang Xu and Yunbo Liu
Some algorithms provide an "outlier score", allowing users to adjust thresholds based on their tolerance for false alarms.
Another critical metric is Mean Time to Detect (MTTD), which measures how quickly an anomaly is identified. Speed is vital in real-time systems, especially as many organizations still take over an hour to detect DDoS attacks. Advanced AI systems aim to shrink this response time to near-zero. At network speeds of 10 Gbps, decision-making must occur in under 100 nanoseconds per packet. These metrics help refine model selection and system tuning to meet operational needs.
Balancing Accuracy and Scalability
Once performance is evaluated, the next step is addressing the trade-offs between accuracy and scalability. High-accuracy models, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, excel at capturing complex patterns over time. However, their hardware demands make them difficult to scale for high-speed network environments. In such cases, simpler statistical methods often provide a more practical solution.
For networks frequently encountering new attack types, boundary-based unsupervised models like One-Class SVM tend to outperform density-based or supervised models in detecting previously unseen threats. Techniques like Focal Loss can also help when training Convolutional Neural Networks (CNNs) for traffic detection, preventing the model from being overwhelmed by benign traffic.
Scalability also hinges on where the models are deployed. In-network computation, which integrates models directly into hardware like switches or smartNICs, enables inference at speeds of 10 Gbps or more. Additionally, intelligent sampling strategies - such as focusing on protocol handshakes - can reduce data volume without sacrificing detection accuracy.
Ultimately, the choice of model depends on the specific network environment and threat profile. Supervised models with high precision work well against known DDoS patterns, while unsupervised models excel at identifying zero-day threats. For high-speed backbone networks, flow-based detection paired with adaptive baselining often strikes the best balance between scalability and effectiveness.
Conclusion
Creating an effective AI-based traffic anomaly detection system is about more than just deploying technology. It requires ongoing human expertise to validate alerts and refine models. As Victoria Shutenko aptly points out:
"The precision of detection depends on how well the model was trained and how representative the training data was".
When it comes to detection methods, the choice between supervised and unsupervised models hinges on your specific threat landscape. Supervised models are excellent at identifying known attack patterns with precision, but unsupervised models become indispensable for spotting zero-day threats where labeled training data is unavailable. For high-speed environments, flow-based analysis offers a scalable solution for continuous monitoring.
Hybrid models, which merge statistical methods with machine learning, provide a balanced approach - combining the reliability of rule-based systems with the adaptability of AI-driven detection. Organizations should also explore in-network computation to enable real-time threat analysis.
To get started, establish behavioral baselines using historical data, factoring in variables such as time of day and device type. Models should prioritize explainability, allowing SOC analysts to quickly identify triggers like unusual port activity or irregular packet sizes. A layered detection strategy is key: use lightweight flow data for constant monitoring while reserving resource-heavy Deep Packet Inspection for high-risk areas. These measures are increasingly essential as the threat landscape continues to evolve.
With cyber-attacks surging by 28% in the first quarter of 2024 and the global AI market projected to hit $1.01 trillion by 2031, investing in AI-driven anomaly detection systems is becoming a cornerstone of modern network security.
FAQs
What makes AI better than traditional methods for detecting traffic anomalies?
AI brings a new level of efficiency and precision to traffic anomaly detection, leaving traditional methods in the dust. Instead of relying on rigid, rule-based systems, AI dives deep into complex patterns in real time, spotting subtle or even unknown anomalies. It evolves alongside network behavior, cutting down on false positives and reducing unnecessary alerts.
Another major perk? AI can handle massive amounts of data at lightning speed, delivering results almost instantly - even in high-traffic situations. Plus, it works with both supervised and unsupervised techniques. This means it can pinpoint known threats with accuracy or uncover new ones without needing pre-labeled data. Advanced AI models even have the edge when it comes to identifying malicious activity in encrypted data - something traditional methods just can’t do.
For those designing custom detection systems, NanoGPT is a game-changer. It offers on-demand access to a variety of AI models, keeps your data local for privacy, and operates on a flexible, pay-as-you-go plan.
How can unsupervised AI methods detect zero-day attacks?
Unsupervised AI techniques excel at identifying zero-day attacks because they don't depend on pre-labeled malicious data or familiar attack signatures. Instead, these methods focus on analyzing normal network traffic patterns - whether that's flow records, packet statistics, or even traffic visualized as image-like data - and create a baseline of what "normal" looks like. When something deviates significantly from this established baseline, it’s flagged as suspicious, even if the threat is brand new.
Using methods like clustering, statistical modeling, and deep learning (such as autoencoders), these systems can spot unusual activity quickly while keeping false positives to a minimum. This makes them particularly effective in real-time or high-traffic environments where new threats are constantly appearing, providing strong defense against previously unseen exploits.
What are the main challenges of using AI for real-time traffic anomaly detection?
Real-time traffic anomaly detection using AI comes with its fair share of challenges. For starters, modern networks generate enormous volumes of high-speed data, much of which is encrypted. This encryption complicates the process for AI models, as they can’t easily analyze payload-level details. On top of that, these systems need to process data in mere microseconds - any delay could make alerts ineffective.
Accuracy is another hurdle, especially at scale. High false-positive rates can overwhelm teams with unnecessary alerts, leading to alert fatigue and wasted resources. Add to that the ever-changing nature of network traffic and the limited availability of labeled data, and supervised learning becomes a tough approach to rely on. While unsupervised methods offer an alternative, they demand highly reliable systems to avoid generating excessive false alarms.
And then there’s the question of scalability and reliability. Processing billions of data points every day calls for efficient, distributed architectures that can handle the load. At the same time, these systems must prioritize privacy and ensure compliance when dealing with sensitive data. Successfully deploying AI-driven solutions means striking the right balance between speed, accuracy, and seamless integration into existing workflows.