How Horizontal Partitioning Improves AI Data Scaling
Horizontal partitioning, or sharding, is a method of splitting large databases into smaller, manageable parts by rows. This approach helps AI systems handle massive datasets efficiently, especially when a single machine's storage and processing capacity isn't enough. By distributing data across multiple servers, horizontal partitioning:
- Improves query speed by skipping irrelevant data using partition pruning.
- Handles large-scale datasets by enabling simultaneous processing across nodes.
- Boosts write throughput by distributing data evenly, avoiding bottlenecks.
- Simplifies scaling by adding more nodes instead of upgrading a single server.
- Enhances fault tolerance as failures affect only a small part of the system.
For AI workloads with billions of rows or high transaction rates, horizontal partitioning is essential. It ensures faster queries, better performance, and seamless growth, making it a cornerstone for scaling AI data systems.
Benefits of Horizontal Partitioning for AI Workloads
Better Query Performance and Concurrency
Horizontal partitioning can significantly improve query speed by allowing the database to bypass irrelevant data. When querying a partitioned table, the optimizer uses the partition key to skip over unnecessary segments of data - a method called partition pruning. This can turn a 30-second full-table scan into a quick 200-millisecond read by avoiding 95% of the data before even considering an index.
These performance boosts are even more noticeable at scale. For example, in a table with 48 partitions, a query targeting just one partition reduces input/output operations by a factor of 48 before an index even comes into play. For AI workloads managing billions of rows - like vector embeddings or training logs - this approach reduces index size, making it easier to keep indexes in memory. Without partitioning, massive tables with billions of rows can create enormous B-Tree indexes, which are slow to navigate. Partitioning breaks these down into smaller, more manageable pieces that stay in the buffer pool [8, 12].
Partitioning also addresses write hotspots, which can occur during high-speed data ingestion. Hash partitioning evenly distributes writes across all partitions, preventing any single node from being overwhelmed. This is especially useful for real-time sensor data or model telemetry [2, 8]. Additionally, multiple nodes can handle different partitions simultaneously, enabling true parallel processing and reducing query times proportionally.
Easier Scaling and Fault Tolerance
Scaling becomes much simpler with horizontal partitioning. Instead of upgrading to a more powerful server (vertical scaling), you can add more nodes and distribute partitions among them. This horizontal scaling approach has no practical limits - doubling the number of nodes roughly doubles the system's capacity [2, 12]. Systems that use consistent hashing can add new nodes without reshuffling all the data, as only about 1/N of the data needs to be moved, avoiding the inefficiencies of naive sharding.
Fault tolerance is another major advantage. If one partition or node fails, the other partitions remain fully operational. This isolation ensures that a single node failure impacts only a small fraction (1/N) of users, rather than causing a complete system outage. For AI inference services, this means models can continue running even if part of the cluster goes offline. Additionally, smaller partitions allow for faster recovery since they can be backed up and restored independently, reducing the time needed to recover compared to restoring a massive monolithic database.
Comparison Table: Horizontal Partitioning Benefits
| Benefit | Non-Partitioned Database | Horizontally Partitioned Database |
|---|---|---|
| Scaling Limit | Restricted by the CPU/RAM of a single server | Expands by adding more nodes |
| Query Performance | Slows down as table size grows | Stays consistent by querying only relevant partitions |
| Fault Tolerance | Entire system goes down if the server crashes | Affects only a small fraction (1/N) of data |
| Write Throughput | Limited by the disk I/O of a single node | Spread across multiple nodes for higher throughput |
| Maintenance | Large operations may lock the entire table | Can perform maintenance on individual partitions |
sbb-itb-903b5f2
Horizontal vs Vertical Database Partitioning
When to Use Horizontal Partitioning for AI Data
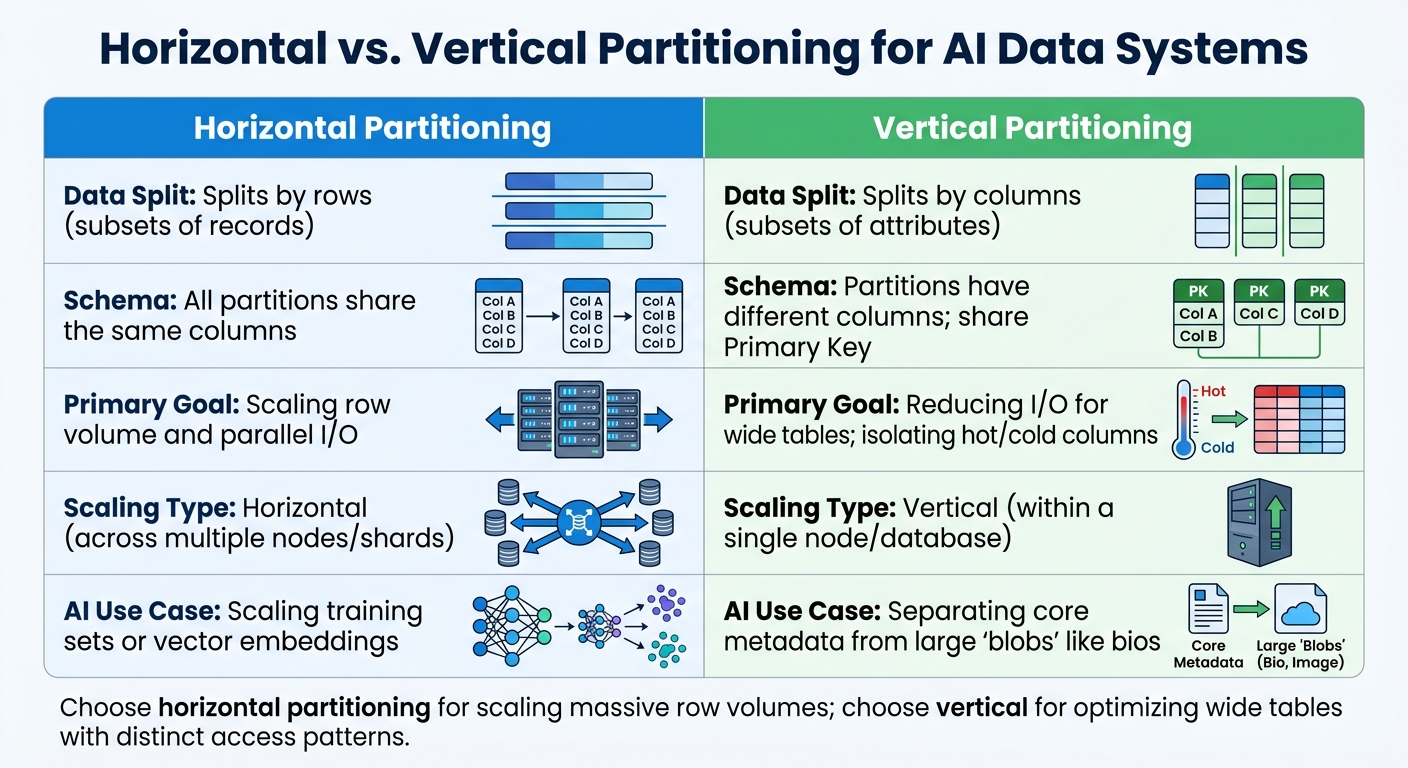
Horizontal vs Vertical Partitioning for AI Data Systems
Evaluating AI Workload Characteristics
Horizontal partitioning is particularly effective when your AI workload exhibits certain traits. One of the most obvious indicators is row count. When tables grow to 50 million rows or more, traditional B-Tree indexes struggle to keep up, leading to slower query performance. At the scale of billions of rows, partitioning becomes a necessity to maintain efficiency.
For write-heavy AI applications, horizontal partitioning can be a game-changer. Tasks like real-time event logging, model telemetry, and sensor data ingestion can overwhelm a single node. By using hash-based partitioning, these writes are distributed across multiple partitions, ensuring no single node becomes a bottleneck. If your system handles thousands of records per second, this distribution is critical to maintaining performance.
Query patterns also play a significant role. If your queries often filter by specific attributes - such as user_id, timestamp, or region - horizontal partitioning enables partition pruning. This allows the database to skip irrelevant partitions entirely. A great example is Airbnb, which partitions its search listings by geographic region. When someone searches for "Paris apartments", only the EU partition is queried, reducing the dataset from 7 million global listings to just 800,000 - a 9x reduction in data scanned.
Another factor is storage and memory limitations. When a dataset grows beyond what a single machine can manage, horizontal partitioning (or sharding) spreads the load across a cluster. Discord, for instance, uses channel_id as a partition key in Cassandra to store billions of messages. When a user requests "the last 50 messages", the query targets a single partition on one node, delivering sub-millisecond response times despite the enormous data volume.
To summarize, the decision to use horizontal partitioning often depends on these workload characteristics. The table below provides a clear comparison of horizontal and vertical partitioning to help guide your decision-making process.
Decision Table: Horizontal vs. Vertical Partitioning
| Feature | Horizontal Partitioning | Vertical Partitioning |
|---|---|---|
| Data Split | Splits by rows (subsets of records) | Splits by columns (subsets of attributes) |
| Schema | All partitions share the same columns | Partitions have different columns; share Primary Key |
| Primary Goal | Scaling row volume and parallel I/O | Reducing I/O for wide tables; isolating hot/cold columns |
| Scaling Type | Horizontal (across multiple nodes/shards) | Vertical (within a single node/database) |
| AI Use Case | Scaling training sets or vector embeddings | Separating core metadata from large "blobs" like bios |
How to Implement Horizontal Partitioning
Choosing the Right Partition Key
Picking the right partition key is a cornerstone of successful partitioning. A strong key should have high cardinality, meaning it contains plenty of unique values. This helps spread data evenly across partitions, avoiding situations where one node gets overloaded - commonly known as "hotspots". Additionally, the key should align with frequent query patterns, ensuring it appears in the WHERE clauses of these queries. This minimizes the need for scatter-gather operations, which can be costly.
For write-heavy AI applications, steer clear of sequential values like auto-incrementing IDs or timestamps in range-based partitioning. These can funnel all new writes into the "latest" partition, creating bottlenecks that slow everything down.
"The cost of resharding is proportional to how well you chose your initial shard key. A correctly chosen shard key - one aligned with your dominant access pattern and chosen to distribute writes evenly - is worth weeks of design time upfront." - Md Sanwar Hossain, Software Engineer
Real-world examples make this clear. Stripe, for instance, uses settlement dates to partition its transaction ledger. This setup allows monthly reports to access a single partition and enables lightning-fast deletion of outdated data with a single command. Similarly, Discord partitions message histories by channel_id across Cassandra clusters. However, when massive "celebrity guilds" created hotspots, they introduced manual overrides to allocate these high-traffic guilds to dedicated nodes.
Once your partition key is set, the next step is to design a shard structure that supports growth and ensures reliability.
Designing and Distributing Shards
With a solid partition key in hand, the next focus is on shard design. A good strategy here is pre-sharding, which involves creating several times more logical shards than physical nodes at the outset - often four to eight times more. This approach makes it easier to scale later by simply redistributing logical shards to new hardware without needing to alter your application's routing logic.
For systems where nodes are frequently added or removed, consistent hashing is a better option than basic modulo hashing. Consistent hashing minimizes data movement when scaling. For example, adding a new node only requires redistributing about 1/N of the data, whereas modulo hashing might require moving the majority of the dataset. In production setups like Cassandra, it's common to configure 150–200 virtual nodes per physical node. This balances the load effectively without overwhelming memory resources.
To further optimize, avoid cross-shard joins by denormalizing your data. For instance, instead of storing user metadata in a separate table, embed it directly within the partitioned table. For small reference data that rarely changes, replicate it across all shards as "Global Tables" to improve access speed.
Testing, Monitoring, and Scaling
Once your shards are structured, rigorous testing and monitoring are critical to ensure the system performs as expected. Test with realistic datasets and closely monitor per-shard metrics like queries per second (QPS), latency, and disk usage. These metrics help you quickly identify and address any "hot shards". Tools like EXPLAIN (ANALYZE, VERBOSE) can confirm whether the query optimizer is effectively pruning irrelevant partitions, which is key for efficiency.
For best results, keep individual partitions under 100GB. In PostgreSQL, aim to keep the total partition count below 500 to avoid query planner slowdowns. Exceeding 5,000 partitions can add hundreds of milliseconds to planning time.
To handle scatter-gather queries that touch all shards, use circuit breakers. These can return partial results instead of letting a single slow shard delay the entire query. Automate partition maintenance by pre-creating future partitions (e.g., monthly ranges) to prevent errors during data insertion. If you ever need to change shard keys, a dual-write pattern can help. This involves writing data to both the old and new schemes during migration, ensuring a smooth transition without downtime.
Examples of Horizontal Partitioning in AI
Sharding Vector Databases for Embeddings
Vector databases rely on horizontal sharding to distribute vectors, often based on document IDs or hashes. A central coordinator sends queries to all shards, where each shard performs a local approximate nearest neighbor search. The results are then merged to identify the global "Top K" matches .
This setup can drastically boost performance. For instance, splitting 10 million vectors across 10 shards means each shard processes only 1 million vectors in parallel, potentially cutting query times by up to 10×. Systems also separate query nodes (optimized for reading) from index nodes (which handle HNSW graph construction), allowing independent scaling .
Of course, sharding comes with challenges. Partitioning HNSW graphs can lead to a recall drop ranging from 0.2% to 3.6%, depending on the strategy used. A major factor here is "in-degree defects", where vectors lose connections post-partitioning - this alone accounts for 84.6% of recall loss in distributed setups. Additionally, over 80% of search steps in distributed HNSW queries involve cross-shard remote procedure calls, adding network overhead.
When planning capacity, storing 10 million 768-dimensional float32 vectors requires roughly 42 GB of RAM, taking into account HNSW graph overhead and system buffers. Industry experts recommend keeping individual shards within a range of 10–30 million vectors to maintain optimal performance. To minimize the need for frequent re-sharding, it's wise to initially shard at 2× the current capacity requirements.
These methods are a cornerstone for scaling large AI training datasets, which is explored further in the next section.
Scaling Training Data for Large AI Models
Training large AI models often involves distributing massive datasets across multiple nodes using horizontal partitioning. The key is selecting a shard key with high cardinality and even distribution to avoid data skew and hotspots . Pre-sharding with logical shards - typically 4–8× more than the available physical nodes - is a common practice. This approach allows logical shards to migrate seamlessly to new hardware as the dataset grows, without requiring changes to application routing logic .
Consistent hashing is critical for elastic scaling. When nodes are added or removed, only about 1/N of the data needs to migrate - far less than the nearly 90% required with simple modulo hashing. For example, adding one shard to a 10-shard cluster using consistent hashing moves just 10% of the data, making scaling smoother and more cost-efficient. This method is particularly useful when systems hit write ceilings of around 8,000 transactions per second (TPS) on a single large instance and need horizontal scaling to reach targets like 50,000 TPS.
Proper data model design is equally important. To avoid costly cross-shard joins, related entities should be co-located on the same shard by using the same shard key. Queries should also include the shard key in their WHERE clause to prevent scatter-gather execution, which can negate scalability benefits . For range-based sharding, using UUID v4 or Snowflake IDs instead of auto-incrementing integers ensures uniform distribution of new inserts and prevents write hotspots.
Avoiding Hotspots in AI Data Retrieval
Efficiently managing query load is critical to avoiding hotspots, where one node becomes overloaded while others are underutilized. Consistent hashing helps evenly distribute vectors across the cluster, preventing any single node from handling a disproportionate amount of data .
Modern systems often separate query nodes from indexing nodes. This allows teams to scale read-heavy query nodes independently, ensuring high traffic doesn't interfere with CPU-intensive indexing tasks. Shard-aware routing further optimizes query processing by directing queries to the shards most likely to contain relevant results. Techniques like semantic clustering or centroid-based routing are commonly used for this purpose .
"Neighbor relationships are defined by position in high-dimensional space, not by any key or partition scheme you control." – Tian Pan
Monitoring plays a vital role in maintaining balance. Tracking metrics like queries per second and latency for individual shards, rather than relying on aggregate data, helps identify "hot shards" caused by popular data entities . It's also crucial to watch for the "memory cliff", where performance drops sharply if the index no longer fits in RAM. Re-clustering should be triggered before available memory falls below 20–30%. In a sharded system, the slowest shard dictates overall query latency, so even one overloaded shard can degrade the performance of the entire cluster .
Conclusion
Horizontal partitioning offers a clear path to overcoming performance bottlenecks in AI systems by transforming operations into scalable, distributed processes. This method achieves near-linear scalability, with partition pruning drastically cutting full-table scan times - from 30 seconds to just 200 milliseconds - by filtering out up to 95% of unnecessary data. Its ability to enable parallel processing across multiple nodes ensures that even massive datasets won't overwhelm a single machine.
By evenly distributing workloads, horizontal partitioning prevents server hotspots from becoming a problem. For example, optimized partitioning architectures have been shown to reduce server footprints by 90% while still maintaining high availability.
However, regular monitoring is essential to avoid partition skew. If 60–80% of traffic starts to concentrate on a small number of partitions, rebalancing becomes critical. A smart approach is to pre-shard with four to eight times more logical shards than physical nodes, allowing room for future growth without the need for a complete system overhaul.
Whether you're scaling vector databases or managing training datasets, horizontal partitioning ensures that your AI systems can grow seamlessly and stay resilient as data scales from gigabytes to petabytes. While it requires thoughtful initial design, the long-term benefits are undeniable.
FAQs
What’s the best shard key for my AI data?
A great shard key for your AI data is one that has high-cardinality (lots of unique values) and is evenly distributed. It should also align with your most common query patterns. For instance, using attributes like a user ID or other unique identifiers often works well. This approach helps maintain balanced data distribution and ensures your queries perform efficiently.
How many shards should I start with?
Start by choosing a number of shards that aligns with your data size, query patterns, and hardware capacity. A typical starting point is 4 to 8 shards, which helps distribute the workload effectively while keeping things manageable. You can always adjust this setup later to better fit your scaling needs.
How do I prevent hot shards and uneven load?
When designing for even data distribution and avoiding performance hiccups like hot shards, it's crucial to pick a partition key with high cardinality. Keys like user ID or timestamp work well because they naturally spread data across partitions.
Using hash partitioning is another smart move. By distributing data uniformly, it helps prevent write hotspots that can bog down performance. On the other hand, range partitioning might lead to imbalances if your data isn't evenly distributed - like when data clusters around specific ranges.
These strategies are especially important in large-scale AI setups, where uneven loads can quickly spiral into serious performance problems.