How Style Transfer Works in AI Image Generation
Style transfer lets you transform images by combining the structure of one image with the artistic style of another. Using AI, particularly convolutional neural networks (CNNs), this process identifies key features in both images and merges them into a single, stylized result. Whether it’s turning a cityscape into a Van Gogh-inspired painting or simulating weather conditions for self-driving cars, style transfer has applications in art, gaming, and even autonomous technology.
Here’s the process in simple terms:
- Input Images: You provide a content image (structure) and a style image (artistic flair).
- Feature Analysis: CNNs extract content details (shapes, objects) and style features (textures, colors).
- Loss Calculation: AI balances content and style through mathematical functions like Gram matrices.
- Image Refinement: The pixels of the output image are adjusted iteratively or in one pass, depending on the method used.
Modern methods like GANs and diffusion models enhance results with sharper details and higher resolutions. Platforms such as NanoGPT make it accessible, offering tools like Stable Diffusion and DALL-E for both image-to-image and text-driven workflows. With these advancements, anyone can create visually stunning results quickly and affordably.
How to turn paintings into photos (and vice versa) with style transfer AI workflows.
sbb-itb-903b5f2
How Neural Style Transfer Works
Neural Style Transfer (NST) uses fixed weights from Convolutional Neural Networks (CNNs) to separate and blend the visual features of two images. The process begins by initializing the pixel values - either with random noise or the content image - and iteratively adjusting them until the desired balance between content and style is achieved.
The VGG-19 architecture, originally designed for object recognition tasks on ImageNet, is the preferred model for NST. In the groundbreaking 2015 Gatys paper, the conv4_2 layer was used to extract content features, while style information was drawn from multiple layers: conv1_1, conv2_1, conv3_1, conv4_1, and conv5_1. This multi-layer approach ensures the algorithm captures both fine details, like brushstrokes, and broader elements, such as color patterns. Let’s dive deeper into how CNN layers contribute to this process.
The Role of Convolutional Neural Networks
CNNs analyze images through a series of layers, each focusing on different visual features. Lower layers identify basic elements like edges and textures, while higher layers capture more complex structures and object-level details.
Content is represented by the raw activations in deeper layers, such as conv4_2, which retain the spatial arrangement of objects. Style, on the other hand, is derived from a Gram matrix - a mathematical tool that captures the relationships between features in a given layer, without regard to their exact positions. As AI researcher Thushan Ganegedara explains:
"The Gram matrix essentially captures the 'distribution of features' of a set of feature maps in a given layer. Minimizing the style loss aligns the feature distributions of the images".
This understanding of feature hierarchies is key to balancing content and style in the final output.
Balancing Content Loss and Style Loss
NST relies on two main loss functions to guide the transformation. Content loss measures how much the generated image deviates from the structure of the original photo. This is calculated as the squared difference between feature maps in a specific deep layer. Style loss, by contrast, compares the Gram matrices from multiple layers to ensure the output adopts the textures, colors, and patterns of the reference image.
These two losses are combined into a weighted sum, with the ratio between them determining the final look. The original research suggests a content-to-style weight ratio between 0.0005 and 0.005. A lower content weight results in more abstract, artistic outputs, while a higher content weight preserves the original image’s structure. Additionally, a total variation loss is sometimes included to smooth out noise and artifacts.
| Component | CNN Layer Used | What It Measures | Visual Impact |
|---|---|---|---|
| Content Loss | Higher layers (e.g., conv4_2) |
Feature activation differences | Maintains object structure and layout |
| Style Loss | Multiple layers (low to high) | Gram matrix correlations | Transfers textures, colors, and patterns |
| Total Variation Loss | N/A | Spatial smoothness | Reduces noise and artifacts |
Together, these loss functions refine the stylized image, enabling modern implementations of style transfer to produce visually striking results.
Modern Style Transfer Technology
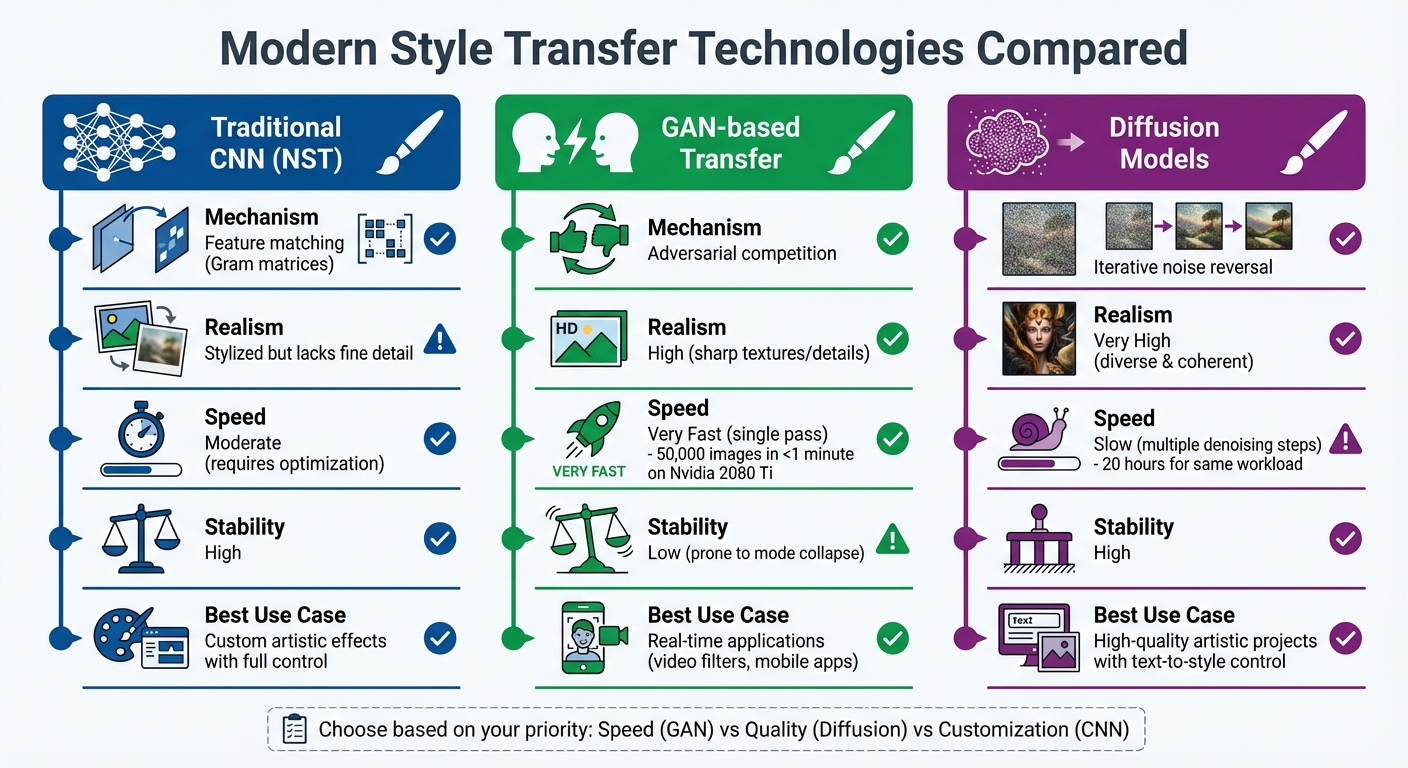
Comparison of Style Transfer Technologies: CNN vs GAN vs Diffusion Models
Modern style transfer has progressed far beyond traditional neural style transfer (NST). Techniques like GANs (Generative Adversarial Networks) and diffusion models now deliver sharper details and higher resolutions, each bringing distinct advantages to the table.
GANs introduced a competitive learning framework that transformed style transfer. This method uses a generator to create images and a discriminator to judge their realism. The result? A creative tug-of-war that pushes the generator to produce highly detailed, authentic textures. For instance, GANs can generate 50,000 small images in under a minute on an Nvidia 2080 Ti GPU, whereas traditional Denoising Diffusion Probabilistic Models (DDPM) require about 20 hours for the same workload.
Diffusion models, on the other hand, take a more deliberate approach. They generate images through iterative denoising steps, capturing intricate textures and high-frequency details that other methods might overlook. A standout example is the StyDiff framework, introduced in January 2026. Researchers tested it using 100,000 images from the COCO dataset as content and 68,669 images from WikiArt as style references. The results? It outperformed on metrics like Structural Similarity Index (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS). Unlike GANs, diffusion models avoid pitfalls like mode collapse.
Choosing between these technologies depends on your goals. GANs are ideal for real-time applications like video filters, producing results in milliseconds. Diffusion models are better suited for projects requiring top-tier artistic quality, offering control through text prompts and reference images. Modern diffusion pipelines now achieve 4K resolution with precise semantic control, though they demand more computational steps during generation.
GANs for Realistic Style Transfer
GANs achieve their lifelike results through advanced architectural designs that go beyond basic adversarial training. A great example is StyleGAN, which maps input data into an intermediate latent space. This mapping allows the model to separate attributes, enabling changes to lighting or texture without distorting facial structures or object layouts - essential for maintaining content integrity during dramatic style shifts.
StyleGAN has evolved significantly. StyleGAN2 tackled "water droplet" artifacts in high-resolution images by introducing Adaptive Instance Normalization (AdaIN), eliminating these flaws. StyleGAN3 took it further by reducing aliasing in the neural network, ensuring that fine details like hair or skin pores transform naturally rather than sticking to specific pixels.
The discriminator in GANs acts as a quality control system, ensuring the generator produces outputs indistinguishable from real training data. This feedback loop has revolutionized image generation and video synthesis, delivering a level of realism previously unattainable.
For practical applications, GANs are unmatched in efficiency. They are particularly useful for mobile apps or live video filters, where computational resources are limited. Optimizations like pruning convolution blocks and using quantization can shrink model size by a factor of four or more. StyleGAN-T, for example, was developed to provide GAN-level speeds for text-to-image synthesis, using CLIP guidance to ensure generated images align with user text prompts.
| Feature | Traditional CNN (NST) | GAN-based Transfer | Diffusion Models |
|---|---|---|---|
| Mechanism | Feature matching (Gram matrices) | Adversarial competition | Iterative noise reversal |
| Realism | Stylized but lacks fine detail | High (sharp textures/details) | Very High (diverse & coherent) |
| Speed | Moderate (requires optimization) | Very Fast (single pass) | Slow (multiple denoising steps) |
| Stability | High | Low (prone to mode collapse) | High |
Diffusion Models for Text-to-Style Transfers
While GANs have paved the way, diffusion models take artistic control to another level. These models start with random noise and refine it step by step, capturing intricate details and textures that are challenging for other methods. As noted in Scientific Reports:
"Due to their progressive denoising property, diffusion models can capture fine details and textures during image generation, producing more detailed and refined images".
In 2024, researchers introduced a breakthrough at CVPR. They adapted large-scale diffusion models for style transfer by modifying self-attention layers. By replacing the "key" and "value" features of the content image with those of the style image, this method preserved the content structure while transferring styles based on local texture similarities, like matching edges. Jiwoo Chung et al. explained:
"This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images".
Text prompts further expand the creative possibilities. Paired with encoders like CLIP, diffusion models allow users to describe the desired style in plain language - think "watercolor sunset" or "cyberpunk neon" - eliminating the need for a perfect reference image.
The trade-off? Computational demands. While GANs produce results in milliseconds, diffusion models require dozens or even hundreds of steps. However, newer approaches like flow-matching (FM) models are narrowing this gap, generating samples in just tens of steps. If artistic quality and diversity matter more than speed, diffusion models are a compelling choice.
Step-by-Step Style Transfer Workflow
Style transfer typically unfolds in three main steps. This process forms the backbone of both traditional and modern approaches, offering a clear roadmap regardless of the specific technology used.
Step 1: Choose Content and Style Images
Start by selecting two images - one to provide the structure (content) and the other for the artistic flair (style). For example, your content image could be a photo of your dog, a cityscape, or a portrait, while the style image might be a Van Gogh painting, a watercolor design, or any artwork with a distinct visual aesthetic.
Both images need to be resized to the same dimensions. For most consumer hardware, 512 pixels is a good balance between image quality and processing speed. If you're using a mobile device or a computer without a dedicated GPU, you might want to go smaller, like 256 pixels, to keep things running smoothly. Be sure to resize without distortion - stretching an image can ruin the artistic effect.
Step 2: Feature Extraction and Loss Calculation
A pre-trained convolutional neural network (CNN) is used to extract features from the images. It captures content details - like shapes and structures - in deeper layers and style details - like textures, colors, and patterns - in earlier layers.
Next, the algorithm calculates two types of loss:
- Content loss: This measures how different the structure of the generated image is from the original content image. It uses Mean Squared Error to compare feature maps.
- Style loss: This evaluates how well the textures and patterns of the style image are represented. It uses Gram matrices, which summarize how patterns and textures co-occur in the image.
The total loss is a combination of these two, weighted by parameters α (content) and β (style). You can tweak these weights to adjust the result - if the output looks too much like the original photo, increase β; if it becomes overly abstract, increase α.
Once the losses are calculated, the algorithm moves on to adjust the image pixels.
Step 3: Generate and Refine the Stylized Image
This step sets style transfer apart from typical neural network training. Instead of updating the network’s weights, the algorithm updates the pixels of the image itself using gradient descent. The L-BFGS optimizer is often preferred here because it converges quickly and reliably.
The process usually starts with either random noise or a copy of the content image. Using the content image for initialization often speeds things up. Over hundreds or even thousands of iterations, the algorithm fine-tunes the pixels to minimize the total loss. Checking the image every 50–100 steps can help you catch the moment when the style is applied just right.
To smooth out pixel transitions and reduce noise, total variation loss is applied. As François Chollet, the creator of Keras, explains:
"The total variation loss imposes local spatial continuity between the pixels of the combination image, giving it visual coherence."
Modern feed-forward models simplify this process, applying styles in a single pass. However, these models are usually limited to specific pre-trained styles. For fully customized artistic effects, the traditional iterative approach remains the go-to method.
Using NanoGPT for Style Transfer

NanoGPT simplifies the style transfer process, offering tools that are both accessible and packed with features.
The platform operates on a pay-as-you-go model, meaning no monthly fees. You gain access to a broad selection of AI models for image generation and style transfer - this includes popular options like Stable Diffusion, DALL-E, Flux Pro, and over 400 others. Pricing starts at just $0.10 (crypto) or $1.00 (credit card) per use, so you only pay for what you need.
Key Features of NanoGPT for Image Generation
NanoGPT combines the strengths of models like Stable Diffusion and DALL-E to create a user-friendly style transfer experience.
- Stable Diffusion: This model supports image-to-image (img2img) workflows, where you can fine-tune the balance between the original image and the new style by adjusting the strength parameter (typically between 0.5 and 0.6). For more detailed control, tools like the IP-Adapter allow you to replicate specific styles and compositions, while ControlNet lets you lock in poses or layouts.
- DALL-E 3: Unlike Stable Diffusion, DALL-E 3 relies on detailed prompts for style transfer since its public API doesn’t allow direct image references. You’ll need to describe the desired elements - such as color palettes, brushstrokes, and lighting - to achieve your vision.
NanoGPT also prioritizes privacy. All data, including conversations and generated images, is stored locally in your browser. This means you can use the platform anonymously without creating an account, and you retain full ownership of any images you create.
With its robust features and privacy-focused design, NanoGPT is easy to set up and use.
Getting Started with NanoGPT
Getting started is straightforward. When choosing a model, look for those labeled "IMG2IMG" to perform image-based style transfers. You can tweak settings like resolution and aspect ratio before running your task. Since images are stored locally in your browser, make sure to download your stylized creations to save them.
Users often praise the platform’s simplicity. One user, Lynn, shared:
"Everything looks and feels so clean and easy to use! Imo the easiest to use gen AI website".
Another user, John D., highlighted the cost-effectiveness:
"Nice to be able to use GPT4 for just a few questions, instead of paying the $20 monthly subscription to OpenAI".
For those using Nano cryptocurrency, there’s an added perk: a 5% discount on all model usage.
Conclusion
Style transfer has come a long way, transforming from a resource-heavy process into a fast, accessible tool that makes it easy to create visually stunning content. By leveraging Convolutional Neural Networks to separate an image's structure from its artistic textures, this technology allows you to combine the content of one image with the style of another. The result? Everyday photos can be turned into artwork that feels gallery-worthy.
The field keeps moving forward. Modern advancements in GANs and diffusion models now enable photorealistic, text-guided style transfers, producing professional-level results without requiring any specialized skills. Single-pass methods, in particular, have drastically sped up the process, delivering results thousands of times faster than older optimization techniques.
These breakthroughs have given rise to user-friendly platforms. Take NanoGPT, for example - it offers an affordable, no-commitment pricing model starting at just $0.10 per use for crypto payments or $1.00 via credit card. With tools like Stable Diffusion and Dall-E integrated, the platform supports both image-to-image workflows and text-driven style applications, offering flexibility for a wide range of creative needs.
Whether you're creating for social media, gaming, or personal art projects, style transfer puts creativity in your hands. It balances preserving the essence of your content with stylistic transformation, all while ensuring your data stays private with local storage options. This accessibility and control signal exciting possibilities for the future of AI-powered image generation.
As the technology continues to grow, style transfer will remain a powerful tool for unlocking creative potential.
FAQs
What distinguishes an image’s “content” from its “style”?
An image’s content refers to its tangible elements - objects, shapes, and the overall arrangement or structure within the image. On the other hand, its style captures the visual essence, including textures, colors, and patterns that shape its appearance.
How do I choose the best content and style images for good results?
To achieve the best results in style transfer, start by picking a content image that features clear and well-defined objects or structures. This ensures the original elements of the image remain recognizable. For the style image, go for one with a bold artistic texture, distinctive color schemes, or noticeable patterns. Images with high contrast and sharp textures - like those found in renowned paintings or unified artistic styles - tend to produce more visually appealing and balanced outcomes.
Should I use a GAN or a diffusion model for style transfer?
Diffusion models, such as StyDiff, have been highlighted in recent studies as offering more refined and effective results for style transfer. While GANs (Generative Adversarial Networks) remain a popular choice, they often struggle with issues related to quality and stability. This makes diffusion models a more dependable option in many scenarios.