How to Detect and Block Malicious Bots in APIs
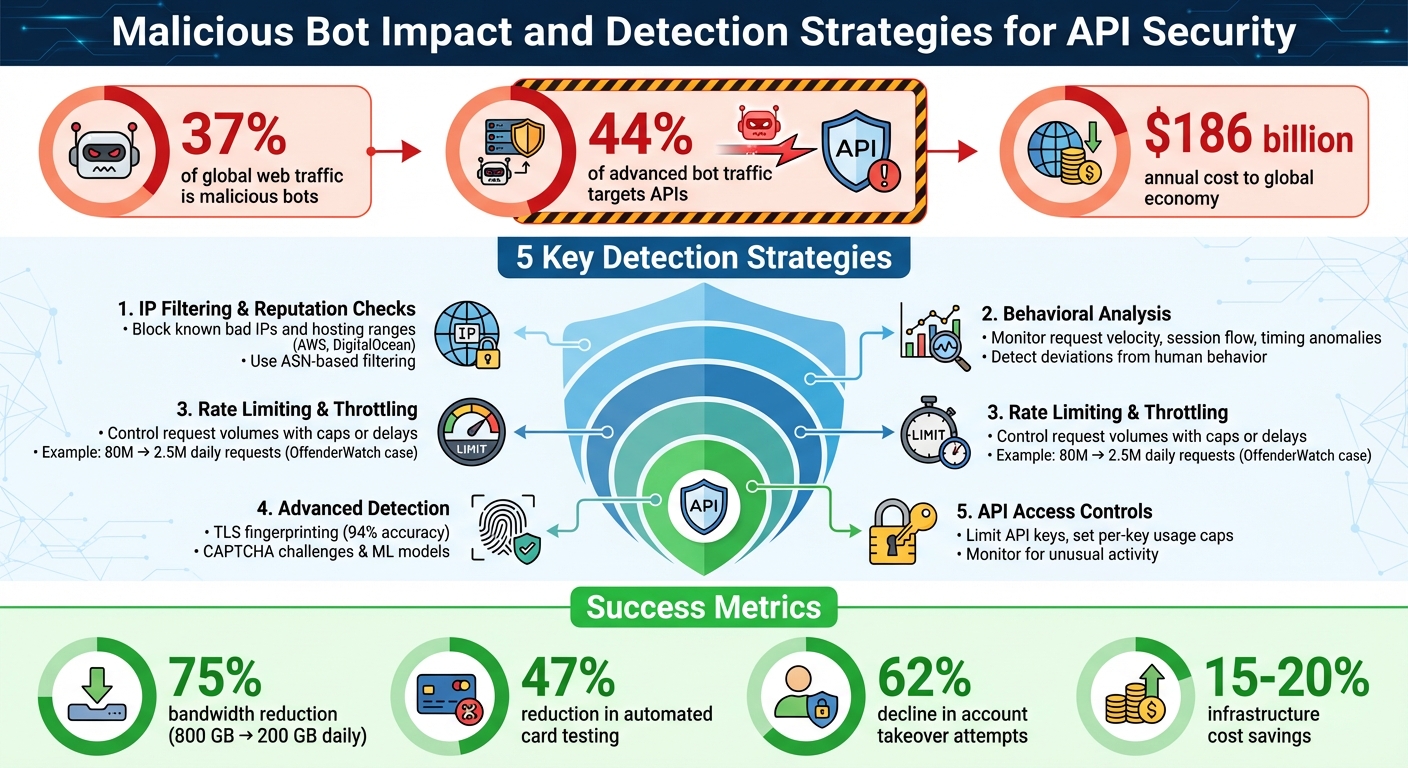
Malicious bots are a growing problem, accounting for 37% of global web traffic and 44% of advanced bot traffic targeting APIs. These bots exploit APIs to steal data, overload systems, and bypass usage limits, costing the global economy $186 billion annually. Modern bots are highly sophisticated, using AI to mimic human behavior, bypass CAPTCHAs, and adapt to defenses.
To protect your APIs, focus on these key strategies:
- IP Filtering & Reputation Checks: Block known bad IPs or entire hosting ranges (e.g., AWS, DigitalOcean) using ASN-based filtering.
- Behavioral Analysis: Monitor traffic patterns like request velocity, session flow, and timing anomalies to identify bots.
- Rate Limiting & Throttling: Control request volumes with caps or delays, ensuring systems remain functional under attack.
- Advanced Detection: Use TLS fingerprinting, CAPTCHA challenges, and machine learning to detect bots mimicking human actions.
- API Access Controls: Limit API keys, set per-key usage caps, and monitor for unusual activity.
Malicious Bot Impact and Detection Strategies for API Security
API Bites Episode 35 | AI vs. Bots: The Future of API Security
sbb-itb-903b5f2
IP Filtering and Reputation Checks
IP filtering works by blocking malicious traffic based on specific IP addresses or network ranges. Blacklisting involves denying access to IPs or CIDR ranges known for malicious activities, making it effective against unsophisticated bots and high-volume attackers. On the other hand, whitelisting allows only trusted traffic - such as search engine crawlers or partner APIs - to bypass security measures. However, whitelisting should always include additional checks, like verifying headers or paths, to guard against spoofing attempts.
One issue with relying solely on individual IP addresses is their instability. Bot operators can easily rotate IPs to bypass filters. To counter this, use ASN-based filtering, which blocks entire infrastructure ranges rather than single IPs. Since bots often operate from low-cost cloud hosting providers like AWS, DigitalOcean, or Hetzner, filtering by Autonomous System Number (ASN) can disrupt large-scale bot operations. Vijay Prajapati, Founder of IP2GeoAPI, highlights this approach:
"ASN-based detection is a practical, low-cost method for identifying bot traffic patterns. By understanding which networks requests originate from, backend systems gain valuable context before deeper analysis."
The next step is implementing these IP-based filters effectively.
Using IP Blacklists and Whitelists
Balancing security and usability is key when setting up blacklist and whitelist rules. For blacklists, automate the process with Web Application Firewall (WAF) rules that deny IPs after they exceed certain request thresholds or attempt to access sensitive endpoints. For instance, in Nginx, you could configure a rule like this:
deny 123.45.67.0/24;
Instead of relying on static blocks, integrate real-time reputation data to improve accuracy. Combining IP filtering with other checks - like analyzing user-agent strings, TLS fingerprints, or behavioral patterns - can make these defenses even more effective.
To strengthen these measures, adding reputation checks is a natural next step.
Using IP Reputation Services
IP reputation services evaluate the trustworthiness of an IP address based on its historical behavior, such as involvement in spam, scraping, or brute-force attacks. These services also categorize IPs by network type, helping distinguish legitimate residential users from higher-risk cloud-hosted traffic. They often provide risk metrics, sometimes called "Abuser Scores", which allow your API to programmatically decide whether to allow, challenge, or block a request.
Key signals in these evaluations include ASN data, Tor exit node status, and the use of commercial VPNs or open proxies. Some providers maintain comprehensive intelligence lists, with databases containing over 600 million known malicious IPs.
Reputation scores can also trigger additional security measures, such as CAPTCHAs or temporary rate limits, especially for sensitive endpoints. For example, a sudden surge in traffic from hosting-provider ASNs targeting a "human-only" API route like /login is a strong indicator of bot activity. This approach helps curb automated attacks while minimizing disruptions for legitimate users, even those accessing your API through VPNs or corporate networks.
Behavioral Analysis and Traffic Patterns
IP filtering can handle basic threats, but more advanced bots use tactics like rotating residential proxies and mimicking legitimate user behavior. That’s where behavioral analysis steps in, focusing on how clients interact with your API.
Humans and bots don’t act the same way. For example, real users usually follow a logical flow - starting on the homepage and browsing through product pages. Bots, on the other hand, often skip these steps and head straight for endpoints like /login or /checkout instead. Their timing patterns also stand out: bots might send hundreds of requests per second or stick to oddly consistent intervals. By moving from origin-based checks to behavior-driven insights, API protection becomes much stronger.
Identifying Unusual Traffic Patterns
Keep an eye on request velocity and session flow. Legitimate users naturally pause and vary their activity, but bots tend to send requests at high, steady rates or show unexpected traffic spikes during off-peak hours. Patterns like these can reveal bot activity, along with a high number of 403 (Forbidden) or 404 (Not Found) responses from the same client, which often signals probing or scraping attempts.
Session flow analysis can also uncover suspicious behavior. For instance, bots might systematically request product pages or use sessions with irregular authentication tokens - behaviors that don’t match those of real users. If a client keeps making requests after receiving a 429 (Too Many Requests) response, it’s another red flag for bot activity.
Using Machine Learning for Bot Detection
Machine learning takes bot detection to the next level by going beyond simple rules and analyzing entire sessions. These models evaluate data like request timing, error rates, traffic volume, payload size, and network latency to create behavioral baselines for different types of users.
One of the standout advantages of machine learning is its ability to detect "zero-day" bot behavior. By identifying deviations from established baselines, these models can spot new evasion techniques that bots might employ. They rely on aggregated patterns and detailed session data to make precise classifications.
For NanoGPT API providers, machine learning models can adapt defenses to specific usage patterns across endpoints like text generation, image creation, or model switching. By establishing baseline behaviors for each endpoint, you can quickly flag any deviations. These analytical tools work hand-in-hand with other security measures to keep APIs secure.
Rate Limiting and Traffic Throttling
Behavioral analysis is great for spotting suspicious activity, but to truly stop bot abuse, you need enforcement tools like rate limiting and throttling. These methods set boundaries on how many requests a client can make, ensuring your system stays functional. Rate limiting puts a hard cap on requests (e.g., 100 per minute), blocking excess traffic with a 429 error. Throttling, on the other hand, slows or queues requests to better manage traffic flow. Together, these techniques work with behavioral analytics to catch and curb anomalies before they cause problems.
The difference between these strategies becomes clear in real-world examples. OffenderWatch, for instance, faced 80 million daily API requests - mostly from scrapers. After implementing tiered rate limiting, they slashed that number to 2.5 million requests per day while keeping legitimate users unaffected. Similarly, Ladders cut infrastructure costs by 15–20% by using throttling tailored to actual usage patterns, all without upsetting their customers.
Setting Up Rate Limits
If you only rely on IP-based limits, you're leaving yourself vulnerable to rotating botnets. Instead, track users through API keys, user IDs, or JWT claims to enforce limits more effectively.
Implement limits at multiple levels for better control:
- API gateways: These handle external traffic efficiently, blocking excess requests before they reach your backend.
- Application code: This can enforce business-specific limits, though it may add some latency.
- Service mesh: For internal communication, this prevents cascading failures by managing service-to-service traffic.
Take NanoGPT as an example: it enforces a global limit of 25 requests per second, with optional per-key controls on daily requests or spending, resetting at midnight UTC.
"One size fits nobody when usage patterns vary by three orders of magnitude." – Vryndaris Krylok, Lapwinglabs
For AI APIs, it's important to track both requests per minute (RPM) and tokens per minute (TPM). A single large request can consume the quota of many smaller ones, so both metrics matter. OpenAI, for instance, enforces a limit of 60,000 requests per minute as 1,000 requests per second - a detail that often surprises developers.
Make sure your API responses include rate limit headers like X-RateLimit-Limit, X-RateLimit-Remaining, and X-RateLimit-Reset. This lets developers manage their requests more effectively.
Throttling Suspicious Requests
Static limits can sometimes block legitimate traffic spikes. Throttling offers a more flexible approach by adapting to real-time traffic patterns. Using behavioral insights, adaptive throttling adjusts controls based on deviations in traffic behavior.
One method, progressive throttling, delays requests more as a client's suspicion score increases. For example, if a client shows signs of abuse - like perfectly timed requests or access from implausible locations - delays might escalate from 1 second to 5 seconds to 30 seconds before a full block is applied.
Adaptive rate limiting takes this further by using unsupervised learning to establish traffic baselines for specific endpoints. This is especially helpful when different endpoints, like /login and /reset-password, have vastly different usage patterns. Instead of relying on static thresholds, this approach detects abuse by spotting deviations from typical behavior.
For handling legitimate batch operations, the Token Bucket algorithm works well. It allows short bursts of activity while maintaining a steady average rate, reducing the risk of false positives during bulk actions.
Client-side practices are equally important. Use exponential backoff with random jitter to avoid overwhelming a recovering system. For example, retry delays could increase from 1 to 2 to 4 seconds, with random variations added. A poorly configured API client without proper backoff once caused a retry storm that racked up $15,000 in costs over just 48 hours.
"The goal isn't perfect detection - it's making bot operations expensive and unreliable while keeping the experience smooth for real users." – Sathish Saravanan
Before enforcing new throttling rules, test them in "log" mode for at least two weeks. This lets you observe typical usage patterns and fine-tune thresholds to avoid false positives. DataDome, for instance, keeps its false positive rate below 0.01% by continuously monitoring legitimate requests that trigger limits. However, overly strict controls can backfire - blocking real transactions led to a 48% churn rate in one case.
Advanced Bot Detection Methods
While rate limiting and throttling can manage obvious abuse, more sophisticated measures are needed to counter bots that mimic human behavior. These methods delve into detailed protocol analysis to verify whether a client is genuine.
CAPTCHA and JavaScript Challenges
CAPTCHA challenges are a step up from basic behavioral detection, as they require actual user interaction to weed out bots. reCAPTCHA v3 is a popular solution that operates in the background, assigning a score to each request from 0.0 (likely a bot) to 1.0 (likely a human). This allows you to set thresholds for different actions - for example, a score of 0.8 might be required for payment processing, while a lower score like 0.3 could suffice for newsletter signups.
To maintain security, your backend must validate the client-side token with the provider's servers. This ensures that the token corresponds to the intended action (e.g., login_submit for a login attempt) and was generated on your domain. Tokens typically expire after 30 minutes, adding another layer of protection.
Low-risk sessions can proceed without interruption, while medium-risk ones may trigger additional verification, such as a v2 checkbox or email confirmation. High-risk traffic (scores below 0.44) is often blocked outright with a 403 error. JavaScript challenges further complicate things for bots by requiring cryptographic operations or DOM manipulations that basic scripts can't handle.
Given that bots are estimated to make up 42% of all web traffic - and two-thirds of that is malicious - relying on behavioral signals like mouse movements and keystroke timing has become increasingly important. These methods go beyond traditional visual puzzles to detect automated activity.
TLS Fingerprinting and Client-Side Detection
TLS fingerprinting takes a closer look at connection details to verify authenticity. By analyzing the unencrypted "Client Hello" message, this method examines specifics like supported cipher suites, TLS extensions, elliptic curves, and their sequence. This approach identifies the actual software making the request, instead of relying on the easily spoofed User-Agent header.
The JA4 fingerprint has largely replaced JA3, offering better accuracy by capturing more precise connection details, such as the number of ciphers and extensions. Research from Istanbul Technical University shows that TLS fingerprinting can detect automated traffic with up to 94% accuracy.
"A spoofed User-Agent backed by a mismatched Client Hello is detectable with high confidence by comparing expected TLS patterns for the claimed platform against the observed handshake." – Ghalia Jarad and Kemal Bıçakcı, Istanbul Technical University
Modern systems often combine TLS fingerprinting with HTTP/2 fingerprinting, which evaluates elements like the SETTINGS frame and WINDOW_UPDATE values. For instance, Chrome uses a 6MB initial window size, while default libraries stick to 64KB. Services like Amazon CloudFront can even add a CloudFront-Viewer-JA3-Fingerprint header to requests, enabling APIs to block clients with suspicious TLS signatures. One large e-commerce platform reported a 47% drop in automated card testing and a 62% decline in account takeover attempts after adopting TLS fingerprinting. This type of detection blocks malicious traffic early, even before application data loads.
Tiered Bot Classification and Blocking
A tiered approach categorizes bots by their risk level and applies responses based on the threat they pose. Start with low-cost checks like HTTP headers, move to harder-to-spoof data like IP reputation and TLS fingerprints, and escalate to active challenges like CAPTCHAs when necessary.
| Bot Category | Purpose | Recommended Action |
|---|---|---|
| Verified Search Engines | Indexing for search traffic | Allow (verify via reverse DNS) |
| AI Search Bots | Powering AI-driven search results | Allow (if referral traffic is desired) |
| AI Training Crawlers | Collecting data for model training | Block or throttle (high resource cost) |
| Malicious Scrapers | Data theft/credential stuffing | Immediate block |
| Suspicious/Unknown | Automated tools/proxies | Challenge (CAPTCHA/JS challenge) |
To ensure only verified bots are allowed, use reverse DNS checks instead of relying on User-Agent strings. For suspicious traffic, look for signs of headless browsers, such as navigator.webdriver or unusual lengths in the eval function. Tailor rules to specific endpoints - for example, allow search indexing on content pages but block automated activity on signup or login forms. Temporary blocking with a time-to-live (TTL) can also be effective, preventing long-term blocks of legitimate users who might inherit flagged IP addresses. One project successfully reduced bandwidth usage from 800 GB/day to 200 GB/day by blocking aggressive AI crawlers.
"The best scrapers don't fight the detection system. They become indistinguishable from a real user at every protocol layer." – Ijaz Ur Rahim
Setting Up Bot Management in NanoGPT APIs

Configuring API Access Controls
NanoGPT allows you to manage up to 10 separate API keys through its dashboard. This setup helps reduce risks by isolating access - if one key is compromised, the others remain unaffected. You can customize each key with specific daily request and spending limits. For instance, a testing key might be capped at 100 requests per day with a $5 daily spend limit, while a production key for trusted partners could allow up to 1,000 requests per day with a $50 cap.
The API imposes a global limit of 25 requests per second across all keys. Authentication is handled via HTTP headers, using either Authorization: Bearer <API_KEY> or x-api-key: <API_KEY>. If a key exceeds its daily limits, the system returns a 429 error, such as daily_rpd_limit_exceeded or daily_usd_limit_exceeded, along with a Retry-After header set to midnight UTC. To stay ahead of potential issues, log affected keys and program your application to handle these errors effectively. Monitoring real-time usage metrics is crucial for spotting unusual activity, allowing you to address problems quickly.
Monitoring API Usage Metrics
Use the /api/subscription/v1/usage endpoint to keep tabs on API consumption. The response includes fields like daily.used, daily.remaining, and daily.resetAt, which you can use to set up alerts for unexpected spikes in activity that could indicate bot abuse. Keep an eye on logs for warning signs such as repeated 429 errors, generic User-Agent strings, or large bursts of requests from a single IP. Additionally, review API response details for anomalies. For example, if prompt_tokens_details.cached_tokens consistently shows zero on repeated, identical requests, it might signal a bot intentionally altering inputs to bypass caching.
NanoGPT also enforces a minimum deposit requirement - $1.00 for fiat or $0.10 for cryptocurrency - to create a financial hurdle that discourages low-cost bot spam. This small but effective barrier helps reduce the likelihood of abuse.
Protecting User Privacy While Blocking Bots
While monitoring for bot activity, it’s essential to prioritize user privacy. NanoGPT keeps data local, ensuring privacy is maintained while enabling efficient bot detection. For sensitive data, use TEE/-prefixed models, which process information within secure enclaves. You can verify these privacy features by requesting attestation reports through GET /api/v1/tee/attestation. These reports provide cryptographic proof that your data remains secure, even when enforcing rate limits or throttling.
When implementing bot detection, focus on collecting only the data necessary for risk assessment. NanoGPT’s per-key quota system tracks API key usage rather than individual user behavior, aligning with its privacy-first approach. If you use prompt caching, enabling the stickyProvider: true option ensures requests stay with the primary provider, even during failovers. This gives you more control over data handling, striking a balance between blocking malicious bots and respecting user privacy.
Conclusion
Summary of Bot Detection Strategies
Protecting your API from malicious bots isn't about relying on a single solution - it's about layering multiple defenses. Start with IP filtering and reputation checks to block known bad actors and traffic from data centers. Add behavioral analysis to spot patterns like unusual request sequences or timing anomalies that hint at bot activity. For more advanced threats, techniques such as TLS fingerprinting, CAPTCHA challenges, and device identification can catch bots that slip through simpler controls. On top of that, rate limiting and throttling help prevent overloads, while in-app runtime detection tackles threats that bypass perimeter defenses.
"Bot detection isn't a single technology decision. It's a layered strategy where each layer addresses the evasion capabilities of a specific class of attacker." - ByteHide
The key is combining different approaches: signature-based detection (like User-Agent and IP reputation), behavioral signals (such as mouse movements or keystroke patterns), fingerprinting (using TLS and browser characteristics), and machine learning for spotting anomalies. Together, these layers create a system that adapts to evolving threats, ensuring stronger protection.
Benefits of Protecting APIs Against Bots
Effective bot protection doesn't just secure your API - it also improves performance and preserves resources. For instance, one platform cut its bandwidth usage by 75%, dropping from 800 GB per day to just 200 GB, simply by blocking AI crawlers.
Beyond resource savings, bot mitigation ensures data integrity and accurate analytics, even when bots dominate web traffic. It also prevents major security risks like credential stuffing, account takeovers, and unauthorized data harvesting, which can erode user trust and compromise sensitive information.
Next Steps for NanoGPT Users
To protect your NanoGPT API, start by focusing on high-value endpoints - login pages, search functions, and resource-heavy API calls are common targets for bots. Set daily request and spending limits on your NanoGPT API keys. If you’re using prompt caching, enable stickyProvider: true to avoid failovers that might invalidate your cache and lead to unexpected costs.
Keep an eye on your usage metrics through the /api/subscription/v1/usage endpoint, and set alerts for unusual traffic spikes. Look for patterns like repeated 429 errors, generic User-Agent strings, or sudden surges in activity. Integrating IP reputation services can also help flag malicious actors in real time.
For an added layer of security, implement edge-based enforcement to block threats in under 10 milliseconds, stopping them before they can even reach your infrastructure. By following these steps, NanoGPT users can establish a strong, cost-effective defense against malicious bots, ensuring both security and reliability.
FAQs
What’s the best way to spot bots when they rotate IPs?
To spot bots that frequently switch IPs, pay attention to ASN patterns. These patterns can uncover stable network details, such as whether the IPs originate from cloud providers or residential ISPs. Pair this with behavior analysis, looking for signs like unusually fast request rates or geographic inconsistencies, and use IP reputation checks to flag suspicious activity. Together, these approaches strengthen detection efforts, even when IPs are constantly changing.
How do I set rate limits for both requests and tokens?
To manage request and token rate limits in NanoGPT, you'll need to dive into the API documentation. It outlines how to set up limits that help regulate request traffic and token consumption. This is crucial for keeping costs in check and preventing misuse. Generally, this process involves setting maximum thresholds for requests and token usage in your API configuration. For step-by-step instructions, refer to the NanoGPT API documentation, which provides specific guidance based on your requirements.
Which signals should trigger CAPTCHA or a JS challenge?
Signals such as unusual device fingerprints, automated behavior patterns, high request volumes, and poor IP reputation are key red flags. When these appear, it’s a good idea to implement CAPTCHA or JavaScript challenges. By analyzing browser details, user behavior patterns, and reputation data, these measures help determine whether the activity is legitimate or suspicious.