How Word Embeddings Ensure Coherent AI Text
Word embeddings are the backbone of AI text generation. They convert words into numerical vectors that machines can process, placing similar words closer in a multi-dimensional space. This allows AI to understand context, distinguish meanings, and maintain logical flow in text.
Key takeaways:
- Static embeddings (e.g., Word2Vec, GloVe): Assign fixed vectors to words but struggle with context and multiple meanings.
- Contextual embeddings (e.g., BERT, ELMo): Create dynamic vectors influenced by surrounding text, improving accuracy and context handling.
- Modern models, like NanoGPT, use advanced techniques like Context Memory for longer, more detailed outputs.
Word embeddings ensure AI-generated text feels logical and contextually accurate by connecting meaning, grammar, and relationships between words.
A visual guide to Word Embeddings
sbb-itb-903b5f2
Static Word Embeddings: Early Techniques
Before AI could interpret context effectively, static embeddings were the go-to method for representing words numerically. Introduced with Word2Vec in 2013 and GloVe in 2014, these techniques assigned a fixed vector to each word, regardless of how it was used in a sentence.
These models are called "static" because they give each word a single, unchanging vector. For instance, the word "bank" would have the same representation whether it referred to a financial institution or the edge of a river. This lack of flexibility, as we'll see, is a key limitation.
Word2Vec: CBOW and Skip-Gram Models
Google's release of Word2Vec in 2013 introduced a method that used shallow, two-layer neural networks to create high-dimensional word vectors. Word2Vec came in two main approaches: Continuous Bag-of-Words (CBOW) and Skip-Gram.
- CBOW predicts a word based on its surrounding context. For example, in the sentence "The cat sat on the ___", CBOW might predict "mat." This method is faster to train and works well for frequently used words.
- Skip-Gram flips this process, using a single word to predict its surrounding context. For instance, given the word "mat", Skip-Gram might predict words like "the", "cat", "sat", and "on." While slower to train, Skip-Gram excels at capturing relationships for less common words.
"The recently introduced continuous Skip-gram model is an efficient method for learning high-quality distributed vector representations that capture a large number of precise syntactic and semantic word relationships." – Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean
In testing with 6 billion tokens, Skip-Gram achieved 66.1% accuracy on semantic tasks, while CBOW reached 57.3%. However, CBOW slightly outperformed Skip-Gram on syntactic tasks, with 68.9% versus 65.1% accuracy. Researchers recommended a context window size of 5 for CBOW and 10 for Skip-Gram.
Word2Vec's vectors typically ranged between 100 and 1,000 dimensions. Impressively, it could process datasets with over 10 million words and learn representations from a 1.6-billion-word dataset in under a day. This efficiency made it practical for real-world applications.
GloVe: Global Co-occurrence Analysis
In 2014, Stanford researchers introduced GloVe (Global Vectors for Word Representation). Unlike Word2Vec, which focused on local context, GloVe incorporated global co-occurrence statistics to improve semantic representation.
"We use our insights to construct a new model for word representation which we call GloVe, for Global Vectors, because the global corpus statistics are captured directly by the model." – Jeffrey Pennington, Richard Socher, and Christopher Manning
GloVe creates a massive matrix that tracks how often words appear together across an entire corpus. For example, if "coffee" and "cup" frequently co-occur in millions of documents, their relationship is directly encoded in their vector representations. This global perspective complemented Word2Vec's local focus, offering researchers another powerful tool for creating word embeddings.
Limitations of Static Embeddings
While static embeddings were groundbreaking, they came with notable drawbacks. The biggest issue? Polysemy - the inability to distinguish between different meanings of the same word. For instance, the word "club" has the same vector whether referring to a sandwich, a golf club, or a social group.
Other challenges include handling out-of-vocabulary words and ignoring word order. If a word wasn't in the training data, the model assigned it a random vector with no semantic meaning. Additionally, static embeddings treat morphological variations like "walk" and "walking" as entirely separate words unless explicitly trained otherwise. As noted by Word2Vec's creators:
"An inherent limitation of word representations is their indifference to word order and their inability to represent idiomatic phrases." – Tomas Mikolov et al.
Static embeddings also risk amplifying biases present in their training data. For example, research has shown patterns like "Man is to computer programmer as woman is to homemaker", reflecting societal stereotypes that can influence AI-generated outputs.
These limitations highlighted the need for more advanced techniques, paving the way for contextual embeddings.
Contextual Embeddings: Modern Approaches to Coherence
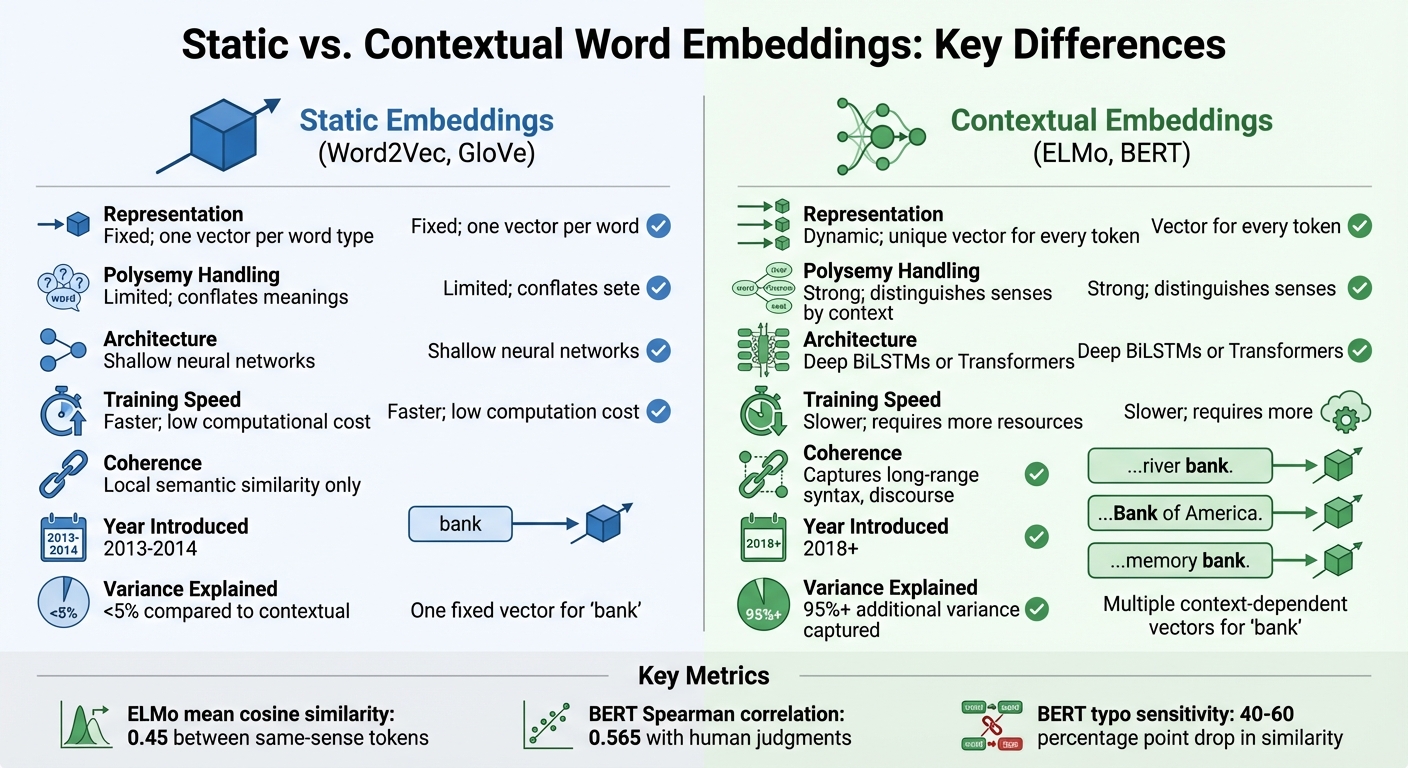
Static vs Contextual Word Embeddings Comparison
Static embeddings fall short when it comes to capturing the nuances of polysemy. These models assign a single, unchanging vector to each word, which doesn’t account for how a word’s meaning shifts depending on context. Contextual embeddings, however, dynamically adjust based on usage. Each token's representation is influenced by the surrounding text, creating high-dimensional vectors that reflect meaning within the given context.
The evolution of contextual embeddings owes much to deep learning architectures capable of processing text bidirectionally. Unlike the shallow neural networks used in static models, contextual approaches leverage bidirectional LSTMs or transformers to better capture the interplay between words and their meanings. Studies show that static embeddings explain less than 5% of the variance found in contextualized representations.
These models work hierarchically. Lower layers capture basic linguistic features like morphology and syntax, while upper layers analyze broader semantics and discourse. This layered structure forms the backbone of successful models like ELMo and BERT, which are explored below.
ELMo: Bidirectional LSTM for Context
ELMo (Embeddings from Language Models), developed by the Allen Institute for AI, uses bidirectional LSTMs to create dynamic word embeddings. Its deep bidirectional language model (biLM) processes text in both forward and backward directions, capturing context from all angles.
"Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus." – Matthew E. Peters, Lead Scientist, Allen Institute for AI
What sets ELMo apart is its method of combining information. It creates final embeddings by taking a learned linear combination of all hidden states from every layer. This approach enables the model to grasp everything from basic word structure to intricate semantic relationships. For example, ELMo achieves a mean cosine similarity of 0.45 between tokens sharing the same sense, demonstrating its ability to differentiate meanings effectively.
BERT: Transformer-Based Embeddings

BERT (Bidirectional Encoder Representations from Transformers), introduced by Google, advanced contextual embeddings further by replacing LSTMs with transformers and incorporating self-attention mechanisms. Using a masked language modeling (MLM) approach, BERT examines all words in a sentence simultaneously, providing a comprehensive understanding of context.
BERT's embeddings align closely with human judgments of word sense distinctions, achieving a Spearman's rank correlation of 0.565. However, it is highly sensitive to variations in input. A single typo can reduce cosine similarity by 40–60 percentage points, as BERT’s subword tokenization (WordPiece) breaks words into smaller units, making it susceptible to surface-level changes.
Static vs. Contextual Embeddings: Key Differences
The transition from static to contextual embeddings marks a major shift in natural language understanding. Static models like Word2Vec assign a fixed vector to each word, collapsing multiple meanings into one representation. Contextual models, on the other hand, generate unique vectors for each token, adapting dynamically to the surrounding text.
| Feature | Static Embeddings | Contextual Embeddings |
|---|---|---|
| Representation | Fixed; one vector per word type | Dynamic; unique vector for every token |
| Polysemy Handling | Limited; conflates meanings | Strong; distinguishes senses by context |
| Architecture | Shallow neural networks | Deep BiLSTMs or Transformers |
| Training Speed | Faster; low computational cost | Slower; requires more resources |
| Coherence | Local semantic similarity only | Captures long-range syntax, discourse |
"Upper layers of contextualizing models produce more context-specific representations, much like how upper layers of LSTMs produce more task-specific representations." – Kawin Ethayarajh, Researcher, Stanford University
Contextual embeddings also show anisotropy, meaning they tend to cluster within a narrow region of the embedding space rather than spreading out evenly. This can result in high raw cosine similarity even between unrelated words, which underscores the need for careful interpretation of these metrics.
How Word Embeddings Work in AI Text Generation
Word embeddings are the backbone of AI text generation, transforming words into numerical vectors within a multi-dimensional space. By calculating the relationships between these vectors, AI models determine how words fit together, ensuring that related words naturally cluster. This system is what allows AI to produce text that feels logical and contextually appropriate.
Semantic Similarity and Context Recognition
These embeddings do more than just link words - they capture both meaning and grammatical structure. This dual capability helps AI models maintain context and even solve analogies by performing vector arithmetic in the embedding space.
"Word embeddings serve as the digital DNA for words in the world of natural language processing (NLP)." – Manish Shivanandhan, freeCodeCamp
Transformer models take this a step further by processing text in layers. The lower layers focus on surface-level features, like basic word patterns. Middle layers handle syntax and local context, while the upper layers dive into deeper meanings and long-range connections. This layered approach ensures that text isn't just grammatically correct but also meaningful and cohesive.
Word Embeddings in NanoGPT Models
NanoGPT builds on these concepts with dynamic embeddings and a unique Context Memory system, tailoring its capabilities for generating longer and more nuanced text. Unlike static models that assign fixed vectors to words, NanoGPT creates specific embeddings for each token instance. This means it can distinguish between different uses of the same word, like "bank" as a financial institution versus a riverbank.
The Context Memory system is another standout feature. Using a B-tree structure for hierarchical compression, it retains key details from earlier parts of a conversation while summarizing less critical information. For example, during a coding session, the system might store an overview of the initial problem while keeping specific error details accessible when needed.
"Large Language Models are limited by their context window. As conversations grow, models forget details, degrade in quality, or hit hard limits. Context Memory solves this with lossless, hierarchical compression." – NanoGPT API Documentation
To activate this feature, users can append :memory to model names (e.g., openai/gpt-5.2:memory). NanoGPT's Context Memory compresses long conversations into 8,000–20,000 tokens - about 10% of the size of a typical large context window - while still allowing access to the full history.
Pricing:
- Non-cached input: $3.75 per 1 million tokens
- Cached input: $1.00 per 1 million tokens
- Output: $1.25 per 1 million tokens
Conclusion: The Future of AI Text Coherence
Key Takeaways
Word embeddings have reshaped how AI generates text that makes sense. The move from static models like Word2Vec and GloVe - which gave each word a single, fixed vector - to contextual embeddings like BERT and ELMo has been a game-changer. Today’s systems create dynamic vectors, allowing words to take on different meanings based on their context.
"Replacing static vectors (e.g., word2vec) with contextualized word representations has led to significant improvements on virtually every NLP task." – Stanford AI Lab
Transformer architectures play a key role here. By processing text in layers, they pick up on everything from simple word patterns to complex semantics. To put it into perspective, traditional static embeddings explain less than 5% of the variance compared to their contextual counterparts, highlighting just how far we’ve come.
Future Developments in Word Embeddings
The next wave of word embeddings is set to go beyond text, incorporating data from visuals, audio, and multiple languages. Imagine a unified system where AI can seamlessly understand language across various formats. Researchers are even exploring quantum-contextual frameworks, which could represent words as unit vectors in Hilbert space - an approach that might better handle words with multiple meanings.
Efficiency and resilience are also major focuses. For example, earlier models struggled with typos - a single character change could cause a 40–60 percentage point drop in cosine similarity. But newer approaches, like tokenizer-free models and character-level processing, are tackling these issues head-on. Techniques such as semantic prompting - where inputs are prefixed with phrases like "meaning: [word]" - are also improving performance, with gains of up to +0.29 in Spearman correlations on similarity tests.
These advancements aim to make AI text generation more dependable, capable of managing longer and more complex conversations while keeping the coherence that modern word embeddings have made possible.
FAQs
How do embeddings make AI text coherent?
Embeddings play a key role in making AI-generated text flow naturally and logically. They work by transforming words into numerical vectors that represent their meanings and relationships. This allows AI models to grasp context, predict the right sequence of words, and maintain coherence. For instance, embeddings place related terms like "king" and "queen" near each other in a vector space, helping the AI identify connections and craft responses that fit the context. With advancements like contextual embeddings, these models can now adapt even better to the surrounding words, improving their understanding and output.
When should I use static vs contextual embeddings?
Static embeddings, such as Word2Vec and GloVe, assign a single, unchanging vector to each word. This makes them fast and resource-efficient, which is great for straightforward tasks or when computational power is limited. However, they face a major limitation: they can’t handle words with multiple meanings (polysemy). For example, the word "bank" would have the same vector whether you're talking about a riverbank or a financial institution.
On the other hand, contextual embeddings - used in models like BERT or GPT - generate word vectors that adapt based on the surrounding context. This makes them perfect for more complex language tasks, such as sentiment analysis or translation, where understanding nuance is key.
If you’re working on a project where speed and simplicity are priorities, static embeddings are the way to go. But for tasks that demand deeper language comprehension, contextual embeddings are the better choice.
How can embeddings handle long conversations without forgetting?
Embeddings handle extended conversations by employing techniques like memory-augmented architectures, gradient modulation, and long-context embedding models. These approaches work together to maintain coherence throughout lengthy interactions.
For example, long-context models are capable of encoding thousands of tokens, allowing them to process and recall larger chunks of information. Meanwhile, memory-augmented systems are designed to retain semantic details across multiple turns in a conversation. By combining these methods, AI can effectively preserve context and reduce the chances of losing track during extended discussions.