Impact of Compression on AI Model Scalability
Compression is a game-changer for scaling AI models. By reducing model sizes by 80–95% while maintaining over 95% accuracy, compression slashes costs, speeds up deployment, and makes AI accessible on devices with limited resources, like smartphones or IoT systems. Here’s why it matters:
- Smaller Models, Big Savings: Compression reduces storage, memory, and processing needs, cutting inference costs by up to 70% and increasing deployment speeds by 10×.
- Edge Device Compatibility: Compressed models run efficiently on devices with limited RAM and processing power.
- Key Techniques: Pruning, quantization, knowledge distillation, and low-rank decomposition are the primary methods used to shrink models while retaining performance.
- Challenges: Accuracy loss, retraining costs, and hardware-specific optimizations require careful balancing.
Compression isn't just about saving space - it's about making AI scalable, cost-effective, and deployable across diverse platforms.
Model Optimization & Compression Techniques: Faster, Smaller & Smarter AI | Uplatz
Main Challenges in AI Model Compression
Compression plays a key role in making AI models scalable, but it’s not without its hurdles. While it improves scalability, it also introduces challenges like accuracy loss, retraining costs, and increased complexity in scaling. Let’s break down these three main challenges in more detail.
Performance Loss from Heavy Compression
Compressing AI models too aggressively can lead to significant drops in accuracy, especially when pushing beyond safe limits. For example, moving from 32-bit to 8-bit quantization reduces model size by 75%, but can result in a 1–5% accuracy loss. Attempting even lower precisions without proper calibration can cause much steeper declines. Similarly, pruning models to 80–90% sparsity often leads to a noticeable drop in accuracy. What’s tricky here is that the performance loss isn’t uniform - while the model might work well on average, it could fail on edge cases or rare inputs.
For large language models, over-compression can hurt nuanced capabilities like reasoning or following instructions. Even if standard benchmarks show acceptable results, the model might struggle in real-world scenarios. The challenge lies in finding the right balance between reducing size and maintaining acceptable levels of accuracy.
Time and Cost of Retraining Compressed Models
Once a model is compressed, fine-tuning is usually required to recover lost accuracy, and this process can be both time-consuming and expensive. Retraining billion-parameter models often takes multiple GPU-days and racks up significant cloud computing costs in the U.S. Each iteration adds to the expense, and restoring performance after pruning or quantization is often more complex than the initial training[5].
Additionally, distributed setups - common for handling large models - bring their own overhead, even after compression. Fine-tuning is essential to make compression worthwhile, but the cost-benefit trade-off only makes sense if compression delivers at least 70–80% savings in inference costs.
Compression Difficulties with Large Models
Compressing large models presents unique challenges. For starters, their sheer size demands significant memory, often requiring distributed pipelines. This increases complexity and raises the risk of failures during the compression process. Moreover, the intricate representations in these models mean that naive compression methods can disrupt critical capabilities.
Validating compressed large models is also more demanding. Beyond standard metrics, they must be tested across multiple benchmarks, safety checks, and real-world scenarios to catch potential regressions that traditional tests might overlook. Certain architectural components, such as attention layers in long-context transformers, are particularly vulnerable to low-precision or structural pruning. In such cases, selective strategies - like keeping critical layers in higher precision while compressing others - are necessary to maintain functionality.
Primary Compression Techniques for Scalable AI
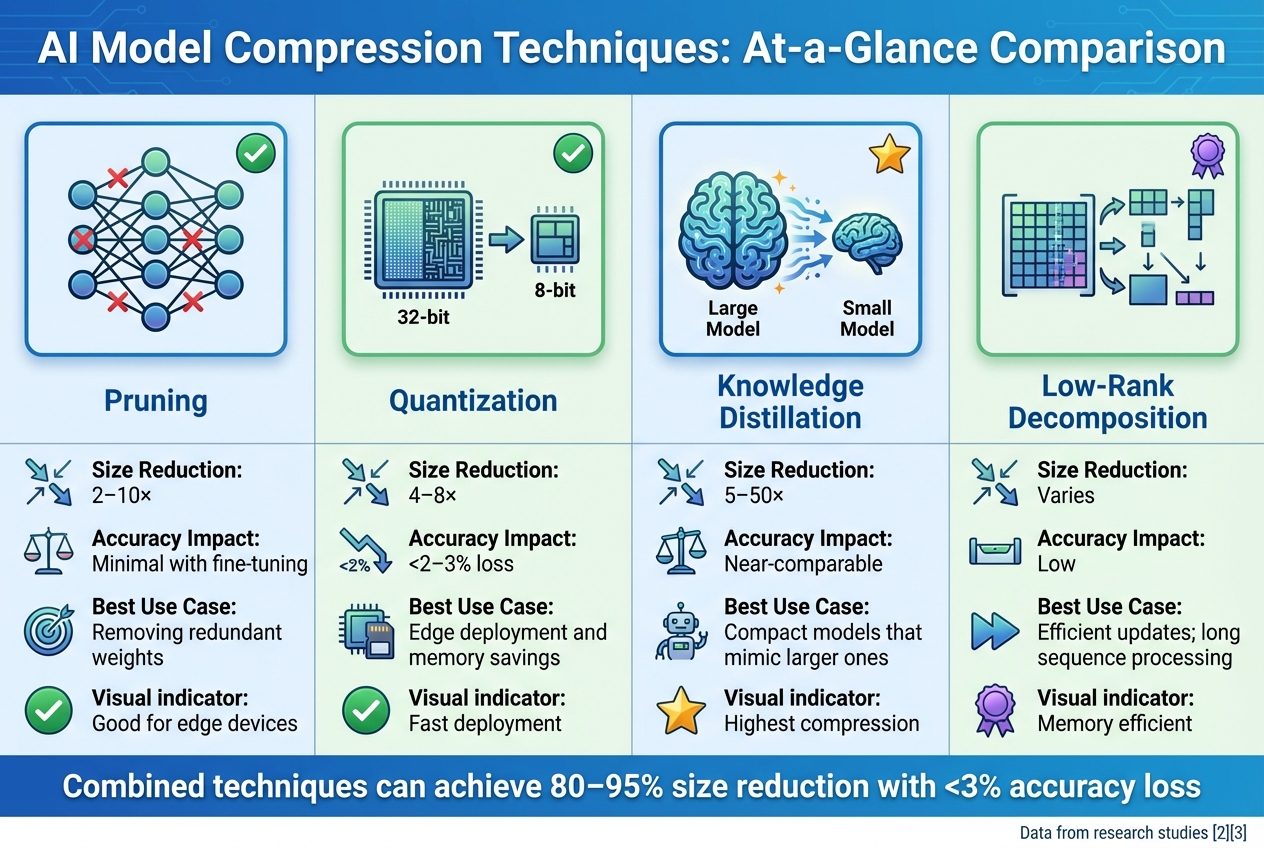
AI Model Compression Techniques Comparison: Size Reduction, Accuracy Impact, and Use Cases
To address scalability challenges in AI models, several key techniques are employed to streamline models while maintaining their performance. These methods focus on eliminating unnecessary components, reducing precision, transferring knowledge, and simplifying structures. Here’s a closer look at these techniques.
Pruning and Quantization
Pruning involves removing parameters in a neural network that contribute the least to overall performance. By carefully fine-tuning after pruning, models can achieve size reductions of 2–10x while retaining most of their original accuracy.
Quantization lowers the precision of model weights and activations, such as converting 32-bit floating-point values to 8-bit or even 4-bit integers. This approach can reduce model sizes by 4–8x with minimal accuracy loss (typically under 2–3%). Post-training quantization (PTQ) is especially practical, as it compresses models without requiring full retraining.
When combined, pruning and quantization can shrink model sizes by as much as 80–95%, with accuracy degradation kept under 2–3%. These techniques also significantly enhance deployment speed, making them ideal for edge devices and mobile applications. For example, models optimized with pruning and quantization have demonstrated up to 10x faster deployment speeds across various hardware platforms.
Knowledge Distillation
In knowledge distillation, a smaller "student" model is trained to replicate the behavior of a larger "teacher" model. Instead of starting from scratch, the student learns by mimicking the teacher's outputs, resulting in a more compact model that retains similar performance. This method can achieve size reductions ranging from 5–50x.
One example of this technique in action is the compression of EON models, which are based on open-source large language models. By applying domain-specific adaptations, these models achieved a 30% reduction in prompt size, faster inference speeds, and notable cost savings - all while maintaining high accuracy in tasks like AI-driven candidate–job matching.
Low-Rank Decomposition
Low-rank decomposition offers another way to simplify AI models by breaking down large weight matrices into smaller, lower-rank components. Techniques like singular value decomposition (SVD) reduce the number of parameters and computational demands while preserving the model’s essential capabilities. This approach is similar to Low-Rank Adaptation (LoRA), commonly used in fine-tuning large language models.
This method is particularly effective for transformers dealing with long sequences. Models like Longformer and BigBird incorporate low-rank attention mechanisms to handle extended contexts with reduced memory requirements, making them more scalable for practical applications.
| Technique | Typical Size Reduction | Accuracy Impact | Best Use Case |
|---|---|---|---|
| Pruning | 2–10x | Minimal with fine-tuning | Removing redundant weights |
| Quantization | 4–8x | <2–3% loss | Edge deployment and memory savings |
| Knowledge Distillation | 5–50x | Near-comparable | Compact models that mimic larger ones |
| Low-Rank Decomposition | Varies | Low | Efficient updates; long sequence processing |
sbb-itb-903b5f2
Advanced Methods for Compression and Scalability
Using Multiple Compression Methods Together
Blending several compression techniques often outperforms relying on just one. A typical process might begin with structured pruning, which eliminates unnecessary weights, followed by quantization to lower numerical precision, and then knowledge distillation, which transfers the capabilities of the original model into a more compact version. Together, these steps can shrink the model's size significantly while keeping accuracy intact.
For large language models, this strategy goes a step further. Teams often compress input prompts to ease memory demands during deployment. Some organizations have reported cutting operational costs by as much as 80% and achieving nearly 10× higher inference throughput. This is possible because fewer GPUs are needed, and batch sizes can be increased. By combining these methods and applying compression gradually, accuracy can be preserved even as the model becomes leaner.
Gradual Compression Schedules
Compressing a model all at once risks harming its accuracy. Instead, gradual schedules break the process into smaller steps, with retraining after each phase [5]. For instance, weight sparsity might be increased incrementally - from 10% to 80% - to maintain performance. Similarly, quantization can start at higher precision (like 16-bit) and then gradually move to 8-bit or even 4-bit, all while monitoring validation metrics.
This incremental approach can achieve compression rates of 80–90% with minimal impact on accuracy, especially for deep transformers, which are sensitive to sudden changes [5]. Teams typically define a compression schedule with targets for sparsity or bit-width per epoch and set early-stop rules, such as halting compression if accuracy drops by more than 0.5% between steps. These small, measured adjustments, combined with periodic fine-tuning, help maintain accuracy throughout the process [5]. This staged approach also aligns well with hardware-specific optimizations, ensuring the model performs efficiently in real-world applications.
Hardware-Specific Optimization
The effectiveness of a compressed model can vary greatly depending on the hardware it runs on. For example, data centers might benefit from mixed-precision formats, while mobile and edge devices often rely on int8 quantization for better performance and cost efficiency [5].
To optimize for specific hardware, teams profile the device's latency and throughput, then fine-tune aspects like precision, sparsity patterns, and architecture to strike the best balance. For instance, using structured 2:4 sparsity can double the speed of pruned models when aligned with hardware-preferred patterns. These targeted optimizations not only lower deployment costs but also improve scalability, making them essential for production environments in the U.S. and beyond.
Deployment and Testing for Scalable AI Models
Adapting Models for Target Platforms
When it comes to deploying AI models, the process doesn’t stop at compression. The next step is tailoring these models to work seamlessly with the target hardware.
Start by exporting the compressed model in a standard format like ONNX. From there, apply optimizations specific to the platform. For instance, NVIDIA GPUs often benefit from TensorRT, while iOS devices use Core ML, and Android systems rely on NNAPI.
Cloud deployments emphasize containerization and efficient GPU usage. Compressed models can cut GPU demand by 2–3× while maintaining up to 99% of their original accuracy. On the other hand, edge devices require models that are drastically smaller - up to 80–95% - with only a minimal accuracy trade-off of 2–3%. For mobile apps, low RAM usage and inference latency under 200–300 milliseconds are critical.
Different hardware types require specific tweaks:
- CPUs: Techniques like int8 quantization and operator fusion can reduce latency by 2–4×.
- GPUs: Leveraging mixed precision formats (FP16 or BF16) and tensor cores significantly increases throughput, enabling more concurrent requests per GPU [5].
- NPUs and Edge Accelerators: These often demand models to align with a narrow set of supported operations and quantization schemes. This may involve minor redesigns to ensure all layers take full advantage of hardware-optimized operations.
Testing and Validating Performance
Before rolling out a model, rigorous testing is essential to ensure it performs as expected under various conditions.
Start by comparing the compressed model to the original using the same validation datasets. Break down the results by segments like user demographics, languages, or content types to identify any localized drops in accuracy.
Stress tests are another critical step. These tests involve running the model on large datasets, adversarial inputs, or extended sequences to evaluate its robustness. Ideally, compressed models should stay within a ≤2% difference in key metrics compared to the original. For generative models, human evaluation on real-world tasks can help confirm that subjective quality hasn’t been compromised during compression.
Realistic benchmarking is equally important. Use synthetic load tests to simulate expected traffic, including concurrent requests, varying input sizes, and sequence lengths. During these tests, monitor metrics like median and tail latency (95th and 99th percentiles), requests per second, memory usage, CPU/GPU utilization, and cost per 1,000 inferences in USD.
Once deployed, continuous monitoring ensures the model meets performance targets. This includes validating the 2–10× throughput improvements and 70–80% cost savings achieved through compression. A/B testing is a practical way to compare the compressed model against the original. By routing 5–10% of live traffic to the compressed model, you can directly measure user engagement, conversion rates, and task success.
Conclusion: Improving Scalability Through Compression
Main Points to Remember
Compression plays a pivotal role in scaling AI effectively. By shrinking model sizes by 80–95% while maintaining over 95% accuracy, compression can slash inference costs by 70–80% and speed up deployment by as much as 10×. These numbers aren't just impressive - they're game-changing for making AI models more accessible and efficient.
What makes compression successful is treating it as a data-driven, iterative process rather than an afterthought. Combining techniques like pruning, quantization, and knowledge distillation, and tailoring them to specific hardware, delivers far better results than relying on a single method. For U.S. businesses working with limited budgets, this approach translates into major GPU cost savings while still meeting accuracy goals and service-level agreements.
Compression also opens up deployment possibilities in a big way. Models that once demanded high-powered cloud GPUs can now run on everyday devices like laptops, smartphones, and edge devices, with only a 2–3% accuracy trade-off. This flexibility is invaluable for teams supporting diverse user bases across a range of hardware environments - without having to overhaul their infrastructure. Tools like NanoGPT take these benefits a step further, offering practical solutions for scalable and cost-effective AI deployment.
How NanoGPT Supports Scalable AI Solutions

The advantages of compression highlight why it’s so critical - and NanoGPT is designed to make scalable AI both achievable and affordable. Its pay-as-you-go pricing model ensures users only pay for the tokens or images they generate, eliminating the need for fixed monthly fees or over-provisioned infrastructure. This flexibility is especially useful for U.S.-based startups, small businesses, and individuals experimenting with different models or handling fluctuating workloads.
NanoGPT also enhances privacy and cost efficiency through local data storage, reducing the need for data transmission. For teams managing sensitive business documents or proprietary research, this setup simplifies compliance with privacy standards while still providing access to over 400 cutting-edge AI models. Organizations can compress and optimize their own models for latency-sensitive tasks and rely on NanoGPT for occasional, resource-heavy workloads. This hybrid approach offers the best of both worlds - balancing cost, performance, and privacy.
With its flexible pricing and localized storage options, NanoGPT empowers users to implement and monitor compression strategies in real time, making scalable AI solutions accessible to a broader audience.
FAQs
What are the benefits of model compression for deploying AI on edge devices?
Model compression plays a key role in preparing AI models for use on edge devices by shrinking their size. This reduction cuts down on computational demands and memory consumption, allowing these models to run more efficiently on devices with limited resources.
By compressing models, you can achieve better latency, improved energy efficiency, and faster operational speeds. This makes real-time AI applications feasible on hardware like smartphones, IoT gadgets, and embedded systems. Compression ensures AI systems can operate effectively even in environments where power and processing capabilities are tight.
What challenges arise in preserving accuracy when compressing AI models?
Compressing AI models comes with its own set of hurdles, particularly when it comes to preserving accuracy. One major concern is the loss of important information, which can hinder the model’s ability to deliver precise predictions. Another issue is a reduced capacity to represent data, making it harder for the model to handle complex or intricate tasks. These challenges often lead to a noticeable drop in performance, especially in scenarios that demand detailed or nuanced analysis.
Overcoming these obstacles requires thoughtful optimization and rigorous testing. Striking the right balance between compression and performance is crucial to ensure the model continues to perform reliably and effectively.
What are the most effective compression techniques for scaling large AI models?
When it comes to scaling large AI models, techniques like pruning, quantization, knowledge distillation, and low-rank factorization play a crucial role. These methods are designed to shrink the model's size and reduce its computational demands, all while keeping performance levels intact.
By simplifying the model, these approaches make it more efficient and easier to deploy - whether you're working with resource-constrained devices or rolling out AI systems for large-scale applications.