Infrastructure for Churn Prediction: Key Features
When building churn prediction systems, the right infrastructure is key to moving from a simple experiment to a scalable solution that reduces customer attrition. The two main approaches - batch processing and streaming systems - each have strengths and trade-offs, depending on how quickly you need to act on churn signals.
- Batch Processing: Works on scheduled intervals (e.g., daily or weekly). It’s cost-effective, easier to manage, and ideal for businesses where churn actions don’t require immediate responses, like email campaigns or monthly retention strategies.
- Streaming Systems: Processes data in real-time, enabling instant churn predictions and actions. This approach suits businesses needing fast interventions, such as offering discounts during cancellations, but it’s more complex and expensive to maintain.
- Hybrid Models: Combine batch and streaming to balance costs and responsiveness. For example, batch updates can handle broader customer groups, while streaming focuses on high-value accounts.
Quick Comparison:
| Aspect | Batch Processing | Streaming Systems |
|---|---|---|
| Speed | Delayed (e.g., 24+ hours) | Real-time |
| Cost | Lower | Higher |
| Complexity | Simpler | More complex |
| Best Use Case | Periodic churn actions (e.g., emails) | Immediate actions (e.g., in-app offers) |
Choosing the right setup depends on your business needs: slower, scheduled actions or instant, real-time responses. Below, we’ll explore how each system works, their pros and cons, and how to decide which is right for you.
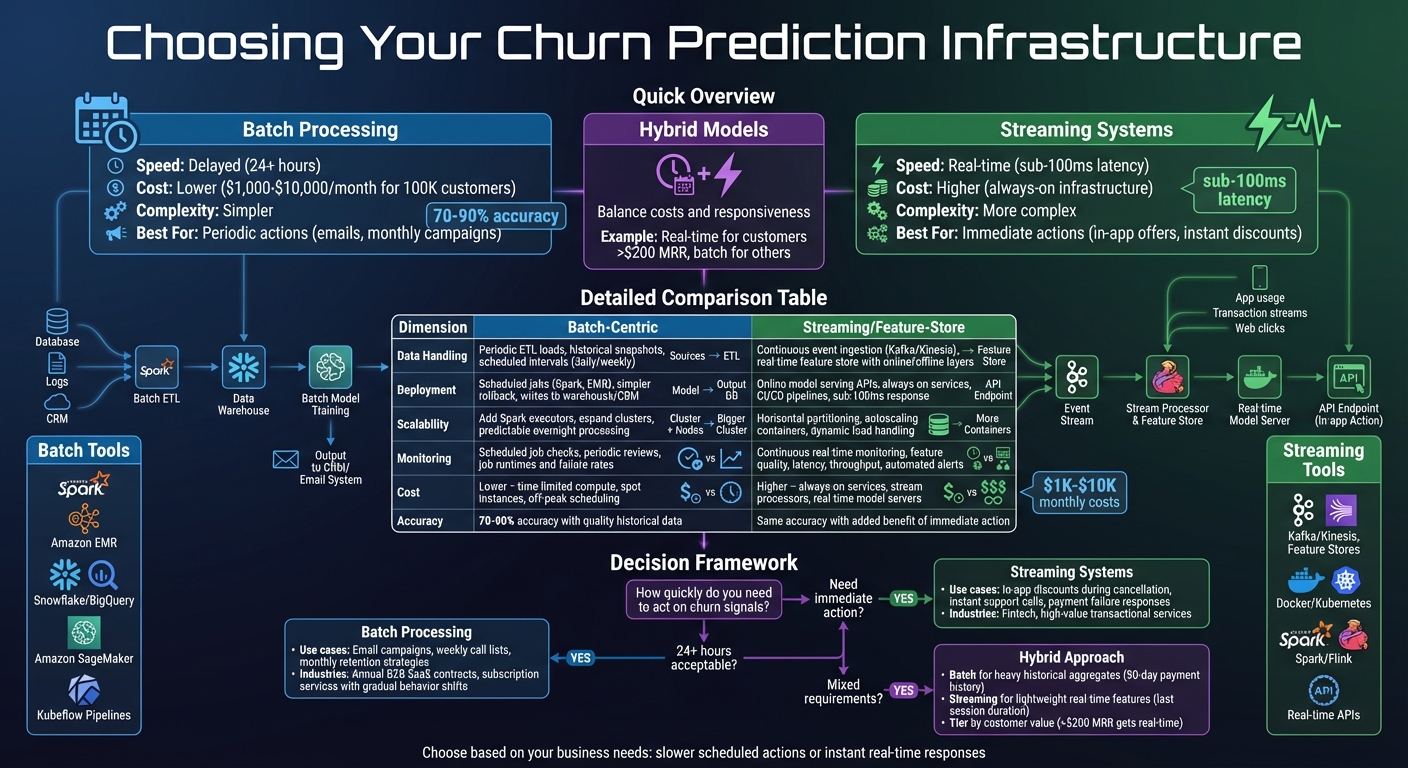
Batch vs Streaming Infrastructure for Churn Prediction: Complete Comparison
1. Batch-Centric Infrastructure
Data Handling
In batch-centric churn prediction, data is gathered from various sources like relational customer databases, billing records, usage logs, support tickets, and CRM systems. This data is then funneled into a centralized data warehouse or data lake. These pipelines operate on a fixed schedule - usually nightly or weekly - using tools like Apache Spark or Amazon EMR. The data is organized into customer-keyed snapshot and feature tables, often stored in partitioned formats like Parquet.
Take a U.S.-based SaaS company as an example: they might run a daily job to process millions of event records and calculate 30-day usage metrics. These metrics, such as login counts, transaction volumes (in USD), and support ticket trends, are stored in cloud warehouses like Snowflake or BigQuery. This structured approach creates a solid foundation for deploying batch-based churn prediction models.
Model Deployment
Once the data pipeline is in place, model deployment follows a clear and systematic process. The training phase involves extracting data, engineering features, and training and validating the model. Tools like Amazon SageMaker and Kubeflow Pipelines help orchestrate these steps, often using Kubernetes clusters or managed compute services.
For deployment, batch inference jobs are scheduled - typically on a daily basis - to analyze fresh data and generate churn risk scores for all active customers. These scores are then written back to the data warehouse or directly into CRM systems. From there, marketing and customer success teams can use the insights to prioritize retention campaigns and monitor their impact on revenue.
Scalability and Monitoring
Batch systems are designed to scale by increasing compute resources - such as adding more Spark executors, expanding EMR clusters, or scaling Kubernetes environments - and by boosting storage capacity in data lakes or warehouses. Monitoring is critical and focuses on key metrics like job runtimes, failure rates, data quality, and model performance (e.g., AUC, precision, recall, and calibration).
A well-constructed churn model, when trained on high-quality historical data, can achieve accuracy levels of 70–90% in identifying potential churners. Many organizations maintain a model registry to track versions, training data ranges, hyperparameters, and evaluation metrics. Retraining schedules are often based on time intervals or triggered by data drift signals.
Cost and Privacy
Batch-centric infrastructures are not just efficient but also cost-effective. They use time-limited compute resources, which lowers cloud expenses compared to always-on streaming systems. Costs can be further reduced by optimizing cluster sizes, using spot or low-priority instances, and scheduling jobs during off-peak hours when rates are lower.
Privacy is another strong point of batch processing. Since most data remains within governed storage systems, it’s easier to enforce privacy controls and comply with U.S. regulations like CCPA/CPRA and HIPAA. Measures such as access controls, encryption, data retention policies, and audit logging ensure robust data protection. For subscription-based businesses in the U.S., where churn risk usually changes over days or weeks, daily batch processing strikes the right balance between data freshness and cost efficiency, without the added complexity of real-time streaming systems.
2. Streaming and Feature-Store-Centric Infrastructure
Data Handling
Batch systems rely on scheduled processing, but streaming infrastructures take a different approach, offering immediate data processing. With streaming churn prediction, real-time event data flows continuously from sources like user interactions, billing systems, and support channels. Instead of waiting for nightly batch jobs, events - such as logins, page views, in-app actions, payments, or support tickets - are captured instantly using platforms like Kafka or Kinesis. This data is then fed into a feature store.
The feature store is divided into two layers: an online layer for immediate access (e.g., "last 7-day login count" or "monthly recurring revenue in USD") and an offline layer for historical data used in training and backtesting. For instance, a U.S. fintech company might stream payment events and account changes. If a customer’s payment fails or they downgrade their plan, the feature store updates within seconds, enabling real-time churn scoring. Meanwhile, historical data is refreshed periodically to complement these real-time updates.
Model Deployment
In a streaming environment, churn models function as always-on services. These models are typically deployed as online inference APIs, hosted on platforms like Amazon SageMaker Endpoint or custom Docker services running on Kubernetes. They pull features from the online store and return churn risk scores in milliseconds. In some cases, models are embedded directly into stream processors, so customer events are scored automatically as they flow through the system. High-risk alerts can then be sent to CRM platforms or customer success teams.
One of the major advantages of this setup is the consistency it provides. The feature store ensures that the same feature definitions are used during both training and live scoring. This eliminates training–serving skew, meaning that metrics like "last 30-day transaction volume" are interpreted the same way in both scenarios. CI/CD pipelines further streamline the process by managing model versions, canary releases, and rollbacks, paving the way for reliable real-time scalability and monitoring.
Scalability and Monitoring
Streaming systems build on the scalability of batch systems by introducing dynamic load handling and real-time oversight. They scale horizontally by partitioning event streams and using autoscaling container services, ensuring sub-100 millisecond latencies even during peak loads. For example, Kafka partitions event streams by customer ID or region, while distributed engines like Spark or Flink parallelize feature computations and adjust resources based on demand.
However, monitoring in a streaming setup is more complex. Teams need to track feature quality - looking for missing values, distribution changes, and data staleness - alongside model performance metrics like AUC, precision, recall, and calibration. Operational metrics such as latency, throughput, and error rates are also monitored in real time. Automated alerts can trigger actions like retraining or rolling back models if critical metrics, such as recall for high-value customers, fall below acceptable levels.
Cost and Privacy
Streaming and feature-store-centric infrastructures generally come with higher costs compared to batch-only systems. This is due to the need for always-on services like stream processors and real-time model servers. However, the ability to act instantly - like offering a discount to a customer during a cancellation process - can make the investment worthwhile. To manage costs, organizations often right-size clusters, use autoscaling, and implement tiered scoring. For instance, high-value U.S. customers generating more than $200 in monthly recurring revenue might receive real-time scoring, while lower-value segments are scored daily in batches.
Privacy is another critical concern. Real-time feature stores often handle sensitive data like personally identifiable information and behavioral insights. To meet regulations such as CCPA/CPRA, robust safeguards like role-based access controls, data masking, and audit logs are essential. Additionally, when customers request data deletion, their features and historical records must be promptly removed from both online and offline stores. Some teams even use AI services like NanoGPT (https://nano-gpt.com), which store data locally, to craft personalized retention messages while adhering to data privacy policies.
Deploy a BigQuery ML Customer Churn Classifier to Vertex AI for Online Predictions GSP944
sbb-itb-903b5f2
Advantages and Disadvantages
Each infrastructure approach comes with its own set of trade-offs, depending on how and when you need to act on churn predictions. Let’s break it down.
Batch systems are perfect for scenarios where interventions happen on a daily or weekly schedule, like overnight email campaigns or generating call lists. They’re straightforward to deploy, less expensive to operate, and easier to debug since every job has a clear start and finish. For instance, a U.S.-based fintech company processing 100,000 customers each night might see monthly costs range from $1,000 to $10,000 for batch infrastructure. The downside? Predictions are delayed by 24+ hours, which could mean missed opportunities, such as acting on payment failures or sudden changes in user behavior.
On the other hand, streaming and feature-store-centric setups flip this trade-off. These systems enable near real-time churn scoring, allowing businesses to take immediate actions like offering in-app discounts or initiating support calls. Stripe’s churn modeling guide highlights that real-time models are critical "when businesses can act immediately to prevent churn." However, this speed comes at a cost. Streaming systems require always-on infrastructure, specialized skills, and constant monitoring, which makes them more expensive and operationally complex. For businesses where decisions don’t need to be instant - like those with monthly subscriptions and gradual behavior shifts - the added complexity may not justify the incremental benefits.
Hybrid approaches offer a middle ground by combining nightly batch processing with real-time updates. For example, batch jobs can handle heavy historical aggregates, like a 90-day payment history, while streaming pipelines manage lightweight, real-time features, such as the duration of the last session. This setup is particularly useful for serving high-value customer segments with instant scoring, while relying on daily batch updates for lower-value groups. Streaming infrastructures also make it easier to experiment - teams can quickly test new features, deploy model variations, and A/B test retention strategies. A company might, for instance, prioritize real-time scoring for customers generating over $200 in monthly recurring revenue, while using batch updates for everyone else. This approach strikes a balance between cost, complexity, and responsiveness.
| Dimension | Batch-Centric Infrastructure | Streaming / Feature-Store-Centric Infrastructure |
|---|---|---|
| Data handling | Periodic ETL loads into a data warehouse; models run on historical snapshots. Best for aggregated data and slower-changing metrics. | Continuous event ingestion (e.g., usage, billing, support) with low-latency, real-time scoring. Features are kept current in a centralized feature store. |
| Deployment flexibility | Simpler deployment using scheduled jobs; predictions are written back to the warehouse or CRM after each batch. Easier to roll back and version. | Requires online model serving, streaming frameworks, and often a feature store. Offers more integration options but adds operational complexity. |
| Scalability | Scales with the volume of historical data over the batch window; ideal for predictable overnight processing. | Must handle high throughput and low latency, requiring elastic streaming infrastructure and careful capacity planning. |
| Monitoring & reliability | Easier to monitor with scheduled job success checks and periodic performance reviews; issues may surface only after processing. | Requires continuous monitoring - tracking lag, error rates, feature freshness, and model performance in real time, often with automated alerts. |
| Cost | Lower infrastructure and operational costs since compute is concentrated in scheduled windows, making it accessible for many small to medium SaaS businesses. | Higher ongoing costs due to always-on compute, streaming services, and advanced monitoring tools. The return on investment must justify these expenses. |
This comparison highlights how each infrastructure balances speed, complexity, and cost. Choosing the right approach depends on your business’s need for timely action. By aligning your infrastructure with how fast you need to respond, churn prediction can become a powerful, ongoing strategy instead of just a one-time experiment.
Conclusion
Deciding on the right infrastructure for churn prediction comes down to how quickly your business needs to respond to potential churn risks. For many U.S. B2B SaaS companies with annual contracts, batch-oriented systems are often a great fit. These systems align well with workflows like weekly email campaigns or monthly retention strategies. Plus, they’re easier to set up, simpler to troubleshoot, and often more budget-friendly for mid-sized companies.
On the other hand, streaming infrastructures shine in industries where swift action is crucial. In these cases, the ability to reduce churn - even slightly - can outweigh the higher costs of maintaining an always-on system.
For many businesses, a hybrid approach can strike the perfect balance. By combining nightly batch processing for the majority of customers with real-time scoring for high-value accounts, companies can manage costs while still responding promptly when it matters most.
FAQs
What’s the difference between batch processing and real-time streaming for churn prediction?
Batch processing works by analyzing large amounts of data at set intervals. This method is perfect for tasks like creating regular reports or spotting long-term trends in customer behavior after the data has been gathered and processed.
On the other hand, real-time streaming handles data as it comes in, offering instant insights into customer behavior changes. This gives businesses the chance to act quickly, making timely adjustments that can boost customer retention and minimize churn.
How does a hybrid model manage costs while ensuring quick churn predictions?
A hybrid model blends traditional methods with AI-driven techniques to create a smart balance between cost and responsiveness. It works by leveraging simpler, less expensive models for initial analysis while reserving advanced, resource-heavy models for crucial decision-making moments. This setup allows businesses to scale effectively, gain real-time insights, and manage costs without compromising on performance.
By efficiently allocating resources, hybrid models enable companies to address potential customer churn swiftly, all while keeping operational expenses in check.
What privacy measures should be considered for batch and streaming data infrastructures?
When setting up batch and streaming data infrastructures, keeping privacy at the forefront is non-negotiable. Protecting data means ensuring it stays confidential, blocking unauthorized access, and eliminating risks of leaks during processing.
One key step is securely storing data on local devices. It's also crucial to never use data for training models without clear, explicit consent from users. On the user side, it's important to avoid sharing sensitive details that might put their privacy at risk. By following these practices, organizations can uphold trust and keep user data safe.