LLM Pricing: What Drives Long-Term Costs
LLM pricing boils down to three main choices: pay-as-you-go APIs, hosted services, and self-hosted solutions. Each has distinct cost structures and trade-offs, depending on your usage, budget, and data privacy needs.
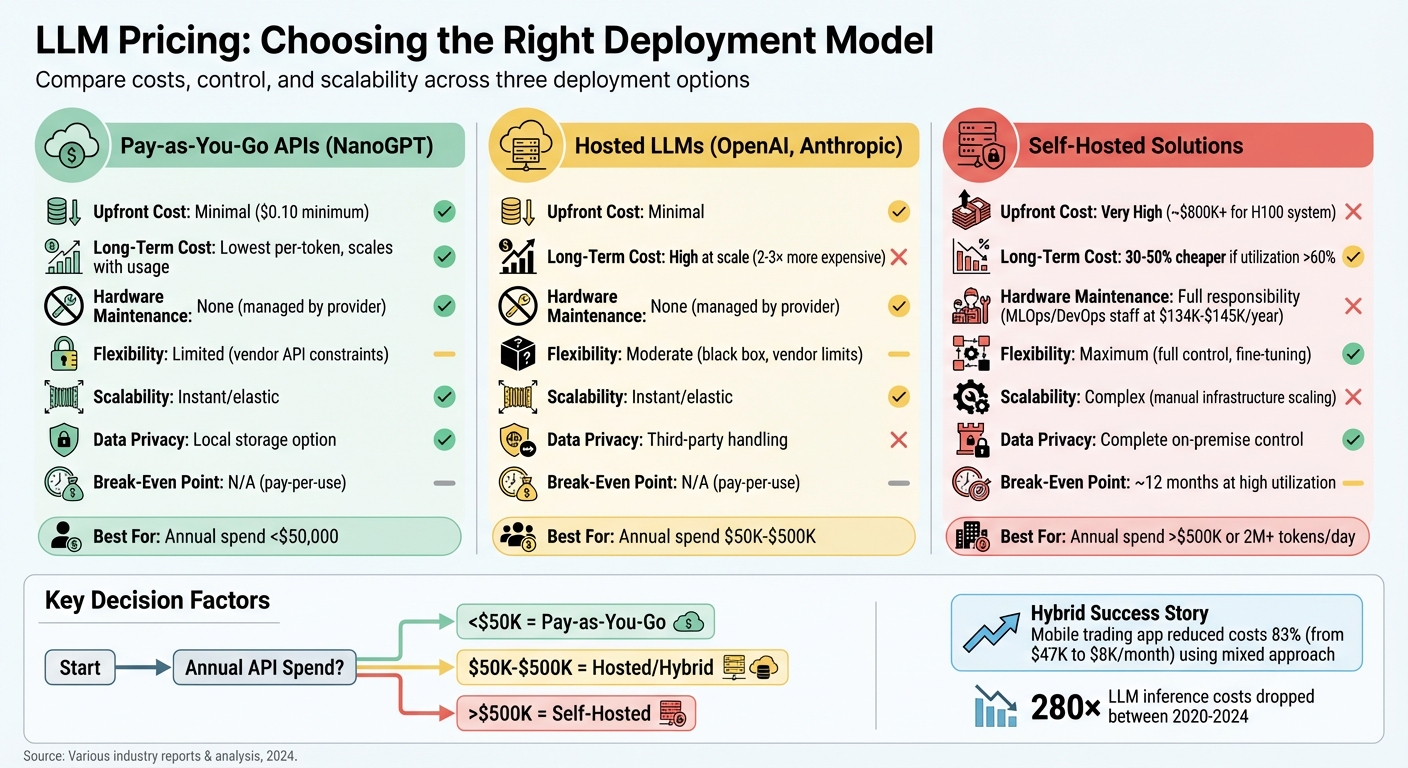
- Pay-as-you-go APIs (e.g., NanoGPT): Low upfront costs, no hardware required, and flexible for small or fluctuating workloads. However, high usage can lead to unpredictable expenses.
- Hosted services (e.g., OpenAI, Anthropic): Easy access to advanced models without managing infrastructure. Costs are higher for large-scale usage, and vendor lock-in is a concern.
- Self-hosted solutions: High upfront investment in hardware and staffing but lower long-term costs for consistent, heavy usage. Provides full control over data and customizations.
Key takeaway:
For small-scale or experimental projects, pay-as-you-go APIs are cost-effective. Hosted services suit medium-scale operations with predictable budgets. Self-hosting is ideal for enterprises spending over $500,000 annually on LLMs or requiring strict data privacy.
| Factor | Pay-as-You-Go APIs | Hosted Services | Self-Hosted Solutions |
|---|---|---|---|
| Upfront Cost | Minimal | Minimal | Very High |
| Long-Term Cost | Scales with usage | High at scale | Cheaper if usage is high |
| Data Privacy | Local storage option | Handled by provider | Full control |
| Scalability | Elastic | Elastic | Complex to scale |
| Maintenance | None | None | Full responsibility |
Understanding these models helps businesses optimize costs while meeting operational needs.
LLM Deployment Options: Cost Comparison of Pay-as-You-Go, Hosted, and Self-Hosted Solutions
1. NanoGPT

Pricing Model
NanoGPT uses a pay-as-you-go pricing structure with a low entry point of just $0.10 and no subscription fees. This means you only pay for the tokens you consume across a variety of AI models, such as ChatGPT, Deepseek, Gemini, Flux Pro, Dall‑E, and Stable Diffusion. The platform provides clear cost breakdowns for every query, giving you a transparent view of your expenses. However, your monthly bill will depend entirely on how much you use the service.
This model works well for businesses with fluctuating workloads, as it eliminates the need to pay for unused capacity. On the flip side, if you're handling high-volume applications with thousands of daily queries, predicting costs can become tricky compared to fixed subscription plans. One big advantage is that you directly benefit from the ongoing drop in inference costs, which have seen sharp declines across various benchmarks. Let’s now take a closer look at how NanoGPT stacks up against traditional self-hosted infrastructure in terms of costs.
Hardware and Infrastructure Costs
Traditional self-hosted solutions often require hefty upfront investments in hardware, with costs ranging from $5,000 to over $50,000. With NanoGPT, those expenses vanish. There’s no need to buy expensive NVIDIA GPUs, worry about electricity bills, or deal with the hassle of maintenance and system updates.
What’s more, NanoGPT stores your data locally on your device. This eliminates the need for managing cloud servers, reducing infrastructure overhead while addressing concerns about data privacy - an increasingly important issue for many organizations.
Long-Term Usability and Flexibility
NanoGPT’s approach to local data storage tackles some of the more pressing long-term challenges. As Guanzhong Pan points out, concerns about data privacy and the high costs of switching providers make local deployments particularly appealing. By keeping your data on your own device, NanoGPT supports privacy and compliance more effectively.
The platform also enables access to a variety of AI models without locking you into a single vendor. This means you're not at the mercy of one provider’s pricing changes or service disruptions. With 95% of businesses reporting satisfaction with the return on investment from AI tools, the flexibility to adjust your model usage over time without being tied to a specific infrastructure offers a strategic edge.
sbb-itb-903b5f2
2. Hosted Large Language Models (General)
Pricing Model
Most hosted large language model (LLM) providers, such as OpenAI, Anthropic, and Google, operate on a pay-as-you-go basis, charging per token. Unlike NanoGPT's localized approach, these providers factor substantial infrastructure expenses into their token pricing. It's worth noting that output tokens are more expensive than input tokens - each generated token requires an additional pass through the model, which can make tasks involving long responses quite costly.
Some providers implement tiered pricing structures, where higher usage results in increased rates. Others offer discounts for large-scale commitments, making them more appealing for enterprise-level users. Interestingly, LLM inference costs have dropped significantly - by 50x annually and accelerating to 200x reductions after January 2024. These pricing strategies reflect the effort to balance accessibility with recovering infrastructure investments.
Hardware and Infrastructure Costs
When you use a hosted API, you’re not directly purchasing hardware, but those costs are still passed on to you through token pricing. Providers invest heavily in high-end equipment like the NVIDIA DGX H100, which costs over $375,000, along with power infrastructure at $7.00 per watt and cooling systems at $2.50 per watt.
To manage these costs and maintain system reliability, providers often impose rate limits and quotas to prevent unexpected surges from traffic spikes or coding errors. A notable cost-saving feature to look for is input caching, where previously processed tokens are reused at a reduced cost. This feature can significantly lower expenses for applications with repetitive workloads.
Long-Term Usability and Flexibility
Hosted services make accessing advanced models straightforward, sparing you the hassle of managing servers. However, they come with challenges, particularly vendor lock-in. Once your application is deeply integrated with a specific provider’s API, switching providers can be a daunting task. This is a sharp contrast to NanoGPT’s self-hosted solutions, which offer greater flexibility and control. As Guanzhong Pan and colleagues explain:
"Cloud services... are attractive because they provide easy access to state-of-the-art models and are easy to scale. However, concerns about data privacy, the difficulty of switching service providers, and long-term operating costs have driven interest in local deployment."
Another issue is model versioning. Providers frequently update their models, which generally improves performance but can sometimes introduce unexpected problems with specific prompts. To avoid disruptions, rigorous testing is essential before transitioning to a new version. Additionally, to safeguard against rate limits or service downtime, it’s wise to build fallback options into your applications - whether that’s simpler models or non-LLM solutions.
3. Self-Hosted LLMs
Pricing Model
Self-hosting large language models (LLMs) changes the way costs are structured compared to pay-as-you-go or hosted API models like NanoGPT. Instead of being charged per token processed, costs are tied to the continuous operation of the hardware, even when the system is idle. As Nikita Bukhal from Zencoder.ai puts it:
"You pre-pay for hardware, facilities, and power; costs accrue even when models are idle - effectively paying by wall-clock time rather than by token."
This idle time can significantly impact costs. For instance, low utilization can increase the cost per 1,000 tokens from $0.013 to $0.13. However, for organizations with high, consistent usage, self-hosting can be cost-effective, often breaking even within 6 to 12 months. Generally, self-hosting becomes financially viable when your annual API spend exceeds $500,000. If your spend is below $50,000, hosted models are likely the better option.
Hardware and Infrastructure Costs
Setting up self-hosted LLMs requires a hefty upfront investment. For example, an NVIDIA A100-80GB GPU costs around $15,000, while renting an H100 GPU on AWS can run about $6.75 per hour - or $1.65 per hour if you use spot pricing. Beyond GPUs, you'll need high-memory servers, NVMe storage, and robust networking equipment. Together, hardware and staffing typically account for 70–80% of the total deployment costs.
Operating expenses add up quickly too. A single H100 GPU running at full capacity uses about $60 in electricity per month, assuming a rate of $0.12 per kWh. On top of that, you'll need cooling systems, data center space, and skilled personnel. For example, hiring a mid-level MLOps engineer in the U.S. costs between $134,000 and $145,000 annually.
The time it takes to break even depends on the size of the model you're running. For smaller models (under 30 billion parameters), the payback period can be as short as 0.3 to 3 months. However, ultra-large deployments might take more than two years to justify the investment.
Long-Term Usability and Flexibility
One of the biggest advantages of self-hosting is the control it provides. You can choose and fine-tune models (e.g., using LoRA) and optimize inference runtimes with tools like vLLM or SGLang. This level of customization is particularly valuable in industries with strict data privacy requirements, such as healthcare or finance. In these cases, deploying in air-gapped environments ensures compliance with regulations like HIPAA or PCI DSS.
That said, this flexibility comes with a significant maintenance burden. You're responsible for everything, from monitoring hardware performance to managing power, cooling, and software updates. Some hardware issues can take days of engineering work to resolve. Unlike hosted APIs that can scale up or down almost instantly, self-hosting requires lengthy procurement processes to scale up, and scaling down leaves you with expensive, underutilized hardware.
For example, a mobile trading app in 2025 cut its monthly AI costs by 83% - from $47,000 to $8,000 - by using a hybrid approach. They routed simple queries to a hosted API while handling bulk tasks with a self-hosted 7B model on spot H100s. This strategy paid for itself in just four months.
The REAL cost of LLM (And How to reduce 78%+ of Cost)
Pros and Cons
When weighing the options between NanoGPT, hosted LLMs, and self-hosted solutions, it's essential to consider the trade-offs in terms of costs, control, and scalability. Here's a breakdown of the strengths and weaknesses of each approach, based on the cost models discussed earlier.
NanoGPT and small models are the most accessible choice, requiring minimal upfront investment and no hardware upkeep. You only pay for what you use, which makes them a great fit for startups or projects with unpredictable workloads. However, these models come with vendor-imposed limitations and offer less customization. For high-volume applications, the per-token costs can add up quickly, even though they remain cost-efficient for smaller-scale usage.
Hosted LLMs eliminate the need to manage infrastructure and provide instant scalability. While this makes them ideal for rapid prototyping and general-purpose tasks, they can become 2–3 times more expensive than self-hosted solutions at higher usage levels. Additionally, relying on hosted solutions can lead to vendor lock-in and raise concerns about data privacy. Extra operational costs - like embeddings, vector databases, and monitoring - can tack on an additional 20–40% to your expenses.
On the other hand, self-hosted LLMs offer unparalleled flexibility and can save 30–50% over three years if utilization exceeds 60–70%. They allow for complete control over data, which is critical for industries like healthcare and finance, and make fine-tuning easier. But the upfront costs are steep - a high-end 8× H100 GPU server can cost around $833,806. You’ll also need skilled MLOps and DevOps engineers, with salaries averaging $134,000 and $145,000 per year, respectively. Scaling these systems involves significant effort, and idle hardware can quickly eat into potential savings.
| Factor | NanoGPT / Small Models | Hosted LLMs (General) | Self-Hosted LLMs |
|---|---|---|---|
| Upfront Cost | Minimal ($0.10 minimum) | Minimal | Very High (≈$800k+ for H100 system) |
| Long-Term Cost | Lowest per-token | High at scale (2–3× more) | 30–50% cheaper if utilization >60% |
| Hardware Maintenance | None (managed by provider) | None (managed by provider) | Full responsibility (MLOps/DevOps staff) |
| Flexibility | Limited (vendor API constraints) | Moderate (black box, vendor limits) | Maximum (full control, fine-tuning) |
| Scalability | Instant/elastic | Instant/elastic | Complex (manual infrastructure scaling) |
| Data Privacy | Local storage option ensures privacy | Third-party handling | Complete on-premise control |
| Break-Even Point | N/A (pay-per-use) | N/A (pay-per-use) | Approximately 12 months at high utilization |
Ultimately, the best choice depends on your specific needs. For example, a hybrid approach can help balance costs and performance. One mobile trading app successfully cut its monthly AI expenses by 83% - from $47,000 to $8,000 - by using small models for routine tasks and reserving premium options for more complex operations. Despite the cost reduction, they maintained a customer satisfaction score of 4.2/5.
Conclusion
Selecting the right LLM deployment strategy hinges on aligning your budget and usage needs with the appropriate model tier. If your annual API spending is under $50,000, opting for hosted models can simplify operations and keep costs predictable. For example, NanoGPT offers a pay-as-you-go model starting at just $0.10, with no subscriptions required. This makes it an excellent choice for startups, side projects, or anyone experimenting with AI without committing to large expenses.
As your spending grows, so should your strategy. For annual API costs between $50,000 and $500,000, a hybrid approach often works best. This involves directing 70–80% of routine tasks - like FAQs, simple classifications, or basic summaries - to more affordable models, while reserving premium models for the 20% of queries that require advanced reasoning or complex processing.
For organizations with annual API expenditures exceeding $500,000 or those handling over 2 million tokens daily, self-hosting becomes a compelling option. While it requires higher upfront investment, self-hosting offers long-term cost savings and complete control over data privacy. This is particularly important for industries like healthcare and finance, which must meet strict regulatory standards such as HIPAA and PCI DSS.
The pricing landscape for LLMs is evolving quickly. Between 2020 and 2024, inference costs for GPT-3.5-class models fell by a staggering 280-fold. The market is now dividing into two clear tiers: affordable models for everyday tasks and premium models for more critical applications. Additionally, techniques like prompt tuning and caching can reduce costs by as much as 40%. This dynamic environment underscores the importance of flexible, usage-based strategies - scaling your infrastructure only when your data justifies it.
FAQs
What are the main cost differences between pay-as-you-go, hosted, and self-hosted LLM solutions?
Pay-as-you-go options, like cloud-based APIs, come with no upfront costs but charge based on usage. This flexibility can lead to unpredictable expenses during periods of high demand. For workloads with heavy usage, this model might end up being 2–3 times more expensive than managing your own infrastructure, as fees cover scaling, maintenance, and other operational needs.
Hosted services strike a balance by combining usage-based pricing with a subscription or reserved capacity. While they cost more than pay-as-you-go options, they include perks like monitoring, regular updates, and customer support. This eliminates the need for upfront investments in hardware or ongoing operational management.
On the other hand, self-hosted solutions involve a hefty initial investment - purchasing something like an H100 GPU cluster can cost around $833,806. However, for workloads running at high utilization (60–70% or more), self-hosting can result in 30–50% savings over three years. This approach does require a skilled in-house team to handle scaling and maintenance, but it’s the most cost-effective solution for steady, resource-intensive use.
Each option has its strengths: pay-as-you-go is highly flexible but can get pricey at scale, hosted services offer predictability with some added costs, and self-hosting provides the best long-term savings for consistent, heavy workloads.
What factors influence long-term costs of large language models (LLMs)?
Several factors play a role in shaping the long-term costs of large language models (LLMs). These include hardware requirements, user demand, and market competition, each influencing expenses in different ways.
Take hardware, for example. High-performance GPUs or specialized chips are a must for both training and deploying LLMs efficiently. These components don't come cheap, and their costs can quickly add up. Then there's user demand - the more people use an LLM, the more computational power is required, driving up maintenance and operational expenses. Lastly, competition among providers can impact pricing strategies, as companies may adjust their rates to stay competitive, making it crucial to weigh your options carefully.
Platforms like NanoGPT offer a practical way to manage these costs with their pay-as-you-go model. Instead of locking you into a subscription, you only pay for what you use. Plus, they store data locally on your device, giving you the added benefit of enhanced privacy.
When does it make financial sense for enterprises to self-host large language models (LLMs)?
Self-hosting large language models (LLMs) can be a smart financial move for enterprises that handle high and consistent workloads. For organizations processing millions of tokens daily, the upfront expense of GPU hardware can lead to significant long-term savings. Over time, the cost per token decreases considerably when the investment is spread across several years.
Companies achieving GPU utilization rates of 60–70% or higher throughout the year often see 30–50% cost reductions compared to relying on cloud-based solutions. Beyond savings, self-hosting offers benefits like predictable costs and enhanced data security, sidestepping the fluctuating fees and privacy risks tied to commercial APIs.
For businesses that can either invest in new GPUs or repurpose existing ones, the economics become even more appealing. The per-token cost of self-hosting is usually much lower than the rates charged by hosted providers. This makes self-hosting an excellent option for enterprises with large, steady workloads, high GPU usage, and the capability to manage their own infrastructure.