Multi-Dimensional Text Quality: Key Frameworks
Evaluating AI-generated content is complex, but breaking it into measurable parts makes it manageable. Multi-dimensional frameworks assess text quality across categories like accuracy, fluency, coherence, style, and relevance. Unlike older metrics like BLEU and ROUGE, these methods focus on deeper aspects such as contextual relevance and factual correctness.
Key Points:
- MQM Framework: Breaks text quality into 7 dimensions (e.g., accuracy, style, terminology) with a clear scoring system. Widely used in translation and customizable for various industries.
- GPTScore: Uses language models for prompt-based evaluation, offering flexibility but dependent on prompt design and model size.
- MSumBench: Focuses on summarization quality using AI debates to score faithfulness, completeness, and conciseness.
- ARIA: Evaluates ethical behavior in AI models, scoring fairness, transparency, and accountability.
These frameworks ensure precise evaluations, helping developers improve AI systems across diverse applications.
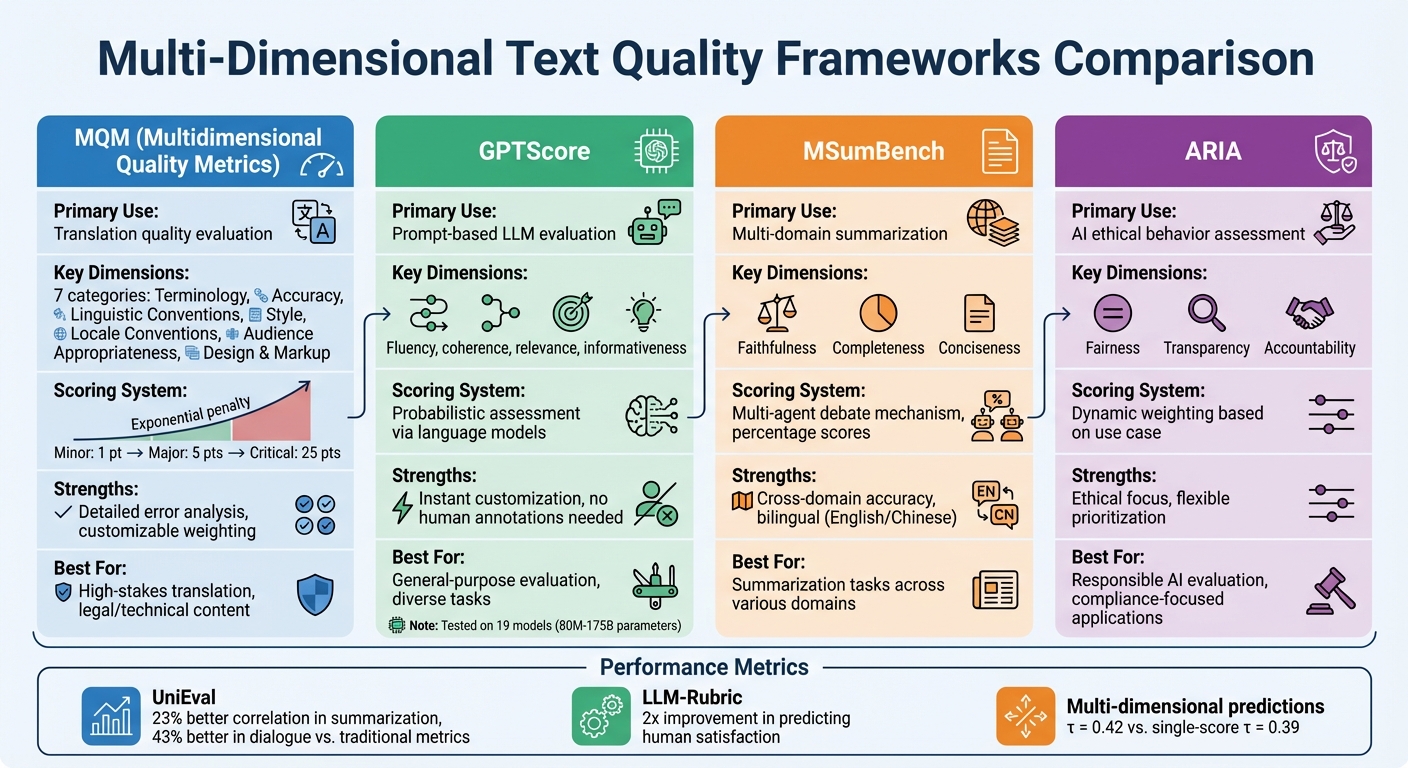
Comparison of Multi-Dimensional Text Quality Frameworks: MQM, GPTScore, MSumBench, and ARIA
How to measure LLM writing quality when there is no right answer?
Multidimensional Quality Metrics (MQM) Framework

The MQM framework takes text quality evaluation to the next level by breaking it down into clear, measurable categories. This approach ensures that quality is assessed in a structured and actionable way.
MQM Error Categories
MQM organizes text quality into seven key dimensions: Terminology, Accuracy, Linguistic Conventions (replacing the older "Fluency" term), Style, Locale Conventions, Audience Appropriateness, and Design and Markup.
Each of these dimensions includes specific error types. For instance, Accuracy covers problems like mistranslations, omissions, and untranslated segments, while Linguistic Conventions focuses on issues such as grammar, spelling, and punctuation. To streamline evaluations, MQM often uses the MQM-Core subset, which highlights the most common issue types.
A key feature of MQM is its distinction between "issues" (potential concerns) and "errors" (confirmed problems). This clarity helps evaluators concentrate on verified mistakes rather than subjective preferences, ensuring a more objective assessment process. Additionally, this structure supports the use of error weighting for a more precise evaluation.
Scoring Methods and Customization
MQM employs an exponential penalty system to reflect the severity of errors: Minor errors score 1 point, Major errors score 5 points, and Critical errors score 25 points. This approach mirrors the real-world impact of mistakes, where a minor typo is far less severe than a critical error that could have serious consequences.
To accommodate different needs, MQM provides three scoring models: raw scores, calibrated scores (on a 0–100 scale), and non-linear scores. Calibration, as described by the MQM Council, offers a closer look at the narrow range near perfect scores:
The process of calibration acts like a magnifying glass for viewing the otherwise very small or inconsistent ranges of acceptance close to 100.
What makes MQM especially versatile is its ability to adjust error type weights based on specific requirements. For example, Accuracy might take precedence over Style in legal documents, while the opposite could be true for marketing materials. This customization ensures that the framework works across a variety of content types and quality standards.
Where MQM Is Used
Thanks to its detailed structure and adaptable scoring, MQM has become a go-to tool for evaluating translation quality. It’s especially prominent in machine translation research, where it serves as a "platinum reference" for training evaluation metrics like COMET and UniTE.
But MQM's applications extend beyond translation. It’s being used in areas like software code evaluation, healthcare data quality checks, and even high-dimensional data visualization. Domain-specific adaptations, such as MQM-Chat and versions designed for under-resourced languages, highlight its flexibility. This adaptability is rooted in MQM's "functionalist" approach, which evaluates quality based on how well the content fulfills its intended purpose, rather than applying a universal standard. This ability to cater to various domains underscores its role in comprehensive text quality assessment.
GPTScore Framework

GPTScore takes a different route compared to manual, metric-based systems like MQM. Instead of relying on predefined metrics, it uses large language models (LLMs) to probabilistically assess text quality.
Prompt-Based Evaluation Method
The framework operates by providing natural language prompts to the model, such as "Is this summary relevant to the original text?". Based on the prompt, the model calculates the probability of generating the target text. This approach allows for tailored evaluations of aspects like fluency, coherence, relevance, and informativeness - without requiring human annotations.
GPTScore offers three modes of operation: vanilla, zero-shot instruction (IST), and instruction plus demonstration (IDM). It has been tested on 19 different models, ranging from 80 million to 175 billion parameters, across four tasks, 22 evaluation aspects, and 37 datasets. Interestingly, just a handful of demonstration samples - around four - are enough to achieve optimal performance.
This method highlights GPTScore's ability to adapt to various evaluation needs while also revealing its potential limitations.
GPTScore Advantages and Drawbacks
One of GPTScore's standout features is its ability to provide instant, prompt-based customization. This flexibility makes it easier to tackle complex evaluation tasks without requiring additional training for the model.
That said, it’s not without its challenges. The scoring process can be subjective, sometimes diverging from human judgments. Additionally, the quality of the results depends heavily on the prompt design and the size of the model. Larger models, like GPT-3-davinci-001, tend to align more closely with human assessments compared to smaller ones.
sbb-itb-903b5f2
New Frameworks: MSumBench and ARIA

Building on the idea of multi-dimensional evaluation, two new frameworks aim to refine assessments by targeting specific needs: MSumBench, which evaluates summarization quality across various domains, and ARIA, which focuses on assessing the ethical behavior of AI models. While GPTScore provides a general evaluation, these tools cater to more specialized requirements. Let’s break down how each framework works and what they measure.
MSumBench for Multi-Domain Summarization
MSumBench is tailored to evaluate summaries in both English and Chinese, addressing the limitations of traditional metrics like ROUGE when dealing with diverse content. Its standout feature is a multi-agent debate mechanism, where multiple AI agents "debate" the quality of a summary. This collaborative process enhances scoring accuracy by incorporating varied perspectives.
The framework evaluates summaries across three main dimensions:
- Faithfulness: Does the summary accurately represent the source material?
- Completeness: Are all the key points covered?
- Conciseness: Is the summary free of unnecessary wordiness?
Each dimension is scored as a percentage, providing a clear and detailed evaluation.
ARIA for Responsibility Assessment
ARIA takes a different approach by focusing on the ethical aspects of AI behavior. It evaluates models based on three critical dimensions:
- Fairness: Does the model treat all users and data inputs equitably?
- Transparency: Are the model's operations and decisions understandable?
- Accountability: Can the model's actions be traced and justified?
What sets ARIA apart is its dynamic weighting system, which adjusts the importance of each dimension based on the specific use case. This flexibility makes it especially useful for industries or applications with unique ethical priorities.
MSumBench vs. ARIA Comparison
| Feature | MSumBench | ARIA |
|---|---|---|
| Primary Focus | Multi-domain Summarization | Responsibility Assessment |
| Languages | English and Chinese | Not specified (likely English) |
| Key Dimensions | Faithfulness, Completeness, Conciseness | Fairness, Transparency, Accountability |
| Evaluation Mechanism | Multi-agent Debates | Dynamic Weighting |
These frameworks highlight a shift toward more targeted evaluation tools. MSumBench addresses the technical challenges of summarizing content across domains, while ARIA focuses on the pressing need for ethical AI evaluation. Both frameworks provide specialized insights that go beyond general-purpose assessment methods.
How NanoGPT Supports Text Quality Evaluation

As evaluation frameworks become more sophisticated, tools like NanoGPT help bring them to life. NanoGPT enables advanced text quality evaluation by offering direct access to powerful models, including ChatGPT, Gemini, and Deepseek. These models excel at tasks like in-context learning and zero-shot instruction, allowing users to evaluate text quality using natural language prompts - no extra model training required. This makes it easier to implement the efficient evaluation methods discussed earlier.
NanoGPT also prioritizes privacy with its local data storage. This feature is especially critical for tasks like machine translation or summarization, where sensitive content is often involved. For example, its Context Memory endpoint compresses conversation history without running model inference, ensuring that sensitive data remains untouched during the process. This privacy-focused design aligns with frameworks like ARIA, which often require handling proprietary or confidential text.
Using NanoGPT for Different Tasks
NanoGPT shines in tasks like Boolean QA-based evaluation, which has been shown to align more closely with human judgment than traditional similarity metrics. For instance, tools like UniEval demonstrate a 23% better correlation with human evaluations on text summarization tasks and over 43% on dialogue response generation compared to older metrics. A practical approach is to frame quality checks as simple questions, such as: "Does this summary match the original content?".
NanoGPT's models, ranging from 80M to 175B parameters, also support rubric-based scoring for more complex tasks. This precision is possible because NanoGPT provides the infrastructure needed to run evaluations without requiring users to invest in expensive hardware.
Benefits of NanoGPT's Pricing Model
In addition to its technical capabilities, NanoGPT offers a cost-effective pricing model. Traditional evaluation methods often depend on human annotations or repeated model inferences, which can quickly become expensive and time-consuming. NanoGPT addresses this issue with its pay-as-you-go approach - there are no upfront costs, and pricing starts at just $0.10 minimum. This flexibility is particularly helpful for researchers experimenting with different models, as performance can vary widely depending on the task.
The scalable pricing structure works equally well for both small-scale tests and large-scale projects. With NanoGPT, you can access models with over 175B parameters for evaluation without the burden of maintaining your own infrastructure. Whether you're running a single evaluation or processing thousands of documents, costs adjust based on actual usage. This affordability makes multi-dimensional quality assessment accessible across industries and research fields.
Conclusion
Main Points
Evaluation methods have evolved beyond simple single-score metrics, with multi-dimensional frameworks now leading the way. MQM stands out for its detailed error analysis, particularly in high-stakes fields like legal or technical translations. GPTScore, on the other hand, offers adaptable, prompt-based evaluation, while MSumBench focuses on assessing summarization across various domains. For open-ended text generation, ARIA provides a structured way to balance multiple evaluation criteria.
Recent advancements showcase clear progress: UniEval demonstrates a 23% stronger alignment with human judgment in text summarization tasks and over 43% in dialogue response evaluations. Similarly, LLM-Rubric doubles its ability to predict human satisfaction, and FDLLM achieves impressive accuracy - 95% - in identifying model fingerprints. These frameworks address traditional issues like limited interpretability and misalignment with human expectations.
Implementation Recommendations
To leverage these advancements, here are some practical strategies. For specialized domains requiring detailed error breakdowns, MQM is an excellent choice. You can customize its dimensions to fit your needs - such as excluding "audience appropriateness" when evaluating formal news translations. If your organization handles diverse tasks like summarization and dialogue generation, UniEval's Boolean QA approach allows one model to assess multiple dimensions efficiently.
For multi-task fine-tuning, aim for at least 1,000 annotated segments to ensure stability. When using large language models for evaluation, include a calibration layer to align model predictions with human judgments. Research shows multi-dimensional evaluations outperform single-score systems; for instance, predictions based on three scores are more reliable (τ = 0.42) compared to single-score predictions (τ = 0.39).
For style evaluations, start with reference-free models, as they outperform reference-based methods (τ = 0.33 vs. τ = 0.26). If your evaluation criteria are evolving, X-Eval offers flexibility by allowing assessments of new aspects without requiring retraining. Match each framework's unique capabilities to your specific quality goals for optimal results.
FAQs
What makes the MQM framework different from traditional text evaluation methods?
The MQM (Multidimensional Quality Metrics) framework takes a different path from traditional evaluation methods like BLEU or ROUGE by offering a more detailed and adaptable way to assess text quality. While traditional metrics often boil everything down to a single score based on surface-level text comparisons, MQM digs deeper. It breaks quality into specific error categories - like accuracy, fluency, and style - and even considers the severity of those errors. This makes evaluations much more diagnostic and precise.
Another standout feature of MQM is its scoring system. By converting expert error annotations into numerical scores, it simplifies the process of identifying and addressing quality issues. Thanks to its multidimensional design, MQM works well across a variety of applications, from translation projects to highly specialized fields like software and healthcare. It provides clearer insights into where text outputs excel and where they fall short.
What makes GPTScore effective for evaluating text quality?
GPTScore shines in evaluating text quality across various aspects like relevance, coherence, and fluency - all without requiring pre-labeled examples or set responses. This is thanks to its use of large pre-trained models with advanced zero-shot capabilities, enabling flexible and customized assessments.
What sets GPTScore apart is its ability to adjust to different needs. By utilizing models of varying sizes and complexities, it can handle everything from quick, high-level reviews to in-depth evaluations. This flexibility minimizes the need for manual annotations, simplifying the process and making it practical for large-scale or real-time use cases.
How do MSumBench and ARIA evaluate the quality of AI-generated content?
MSumBench and ARIA are tools designed to dive deep into the quality of AI-generated content, each focusing on different but complementary aspects of evaluation.
MSumBench zeroes in on summarization models, covering multiple domains and languages like English and Chinese. What sets it apart is its use of a multi-agent debate system, which boosts the quality of annotations. This approach provides a richer view of performance, uncovering patterns and biases that traditional single-metric methods might overlook.
On the other hand, ARIA (Automatic Relevance and Informativeness Assessment) evaluates large language models (LLMs) by examining crucial elements such as content quality, relevance, and factual accuracy. By addressing the gaps left by older metrics, ARIA offers a more reliable and well-rounded way to assess generated text.
Together, these frameworks mark a step forward in evaluating AI-generated content, offering insights that help pinpoint strengths and areas for improvement.