Guide to Optimizing Multimodal Pipeline Benchmarks
Multimodal pipelines process diverse data like text, images, and audio, pushing hardware to its limits. Standard benchmarks often fall short for these complex systems. This guide covers how to optimize benchmarks by addressing memory spikes, CPU-GPU bottlenecks, and resource utilization challenges. Key takeaways include:
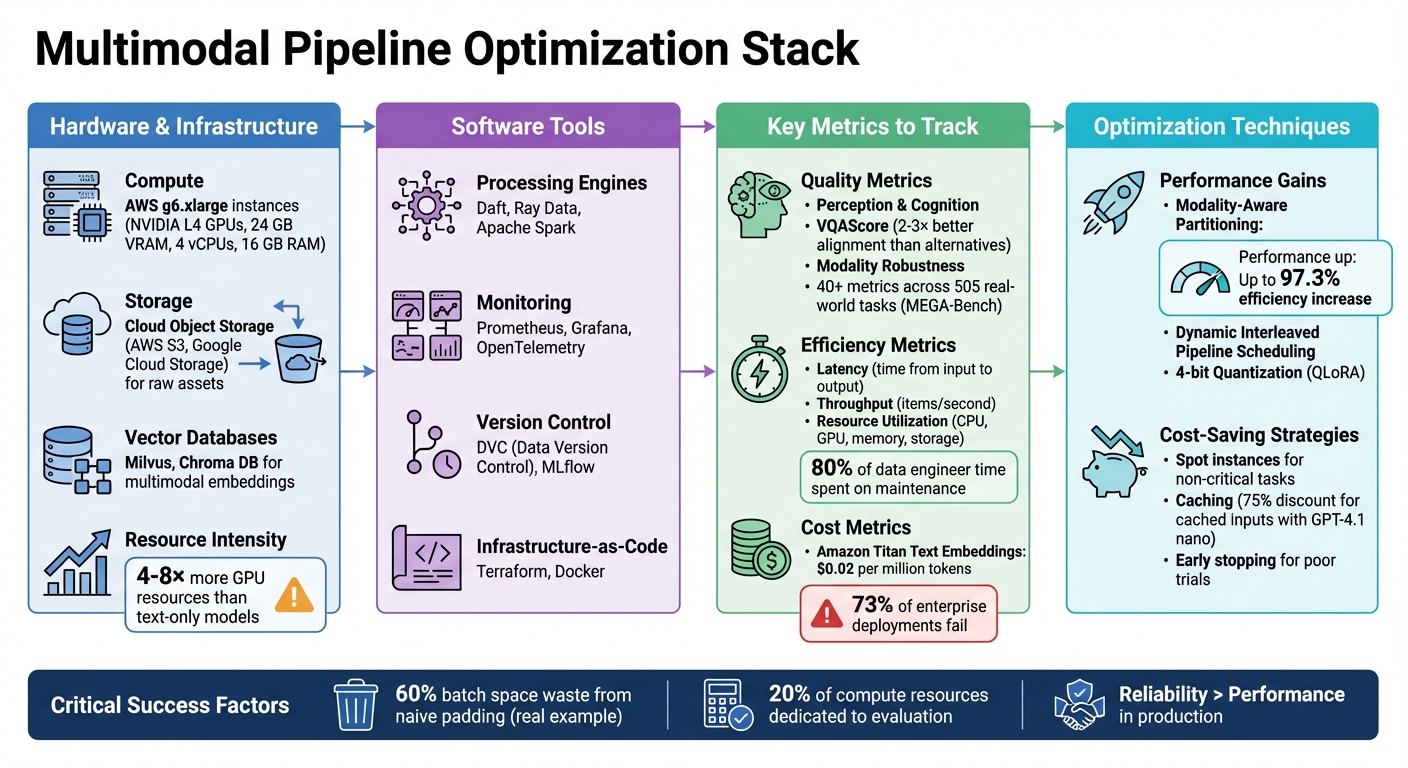
- Efficient Hardware Use: Employ AWS g6.xlarge instances with NVIDIA L4 GPUs for balanced performance.
- Software Tools: Use Daft, Ray Data, or Spark for processing; Milvus or Chroma DB for embeddings; and Prometheus or Grafana for monitoring.
- Metrics to Watch: Measure latency, throughput, modality robustness, and resource usage while managing costs.
- Optimization Techniques: Dynamic scheduling, modality-aware partitioning, and CI/CD practices can improve pipeline efficiency.
- Cost-Saving Tips: Leverage 4-bit quantization, spot instances, and caching to reduce expenses.
This approach ensures scalable, reliable benchmarking for multimodal systems while balancing cost and performance.
Multimodal Pipeline Optimization Stack: Hardware, Software, and Key Metrics Comparison
The Truth About RAG & vLLM: Why Your Multimodal System Fails at Scale
sbb-itb-903b5f2
Setting Up a Benchmarking Environment
Creating a dependable benchmarking setup requires precise coordination of hardware and software. Multimodal pipelines push I/O, CPU, and GPU resources to their limits all at once, which sets them apart from more traditional data workloads. To avoid inconsistent results between test runs, maintaining a stable and consistent environment is key. This foundation paves the way for the detailed configurations that follow.
The starting point is having the right compute resources. For instance, AWS g6.xlarge instances, which feature NVIDIA L4 GPUs (24 GB VRAM), 4 vCPUs, and 16 GB RAM, strike a good balance for managing tasks like inference and handling large files, such as videos or high-resolution images. Distributed data engines like Daft, Ray Data, or Apache Spark are well-suited for processing tasks such as audio transcription, image classification, and document embedding. On the storage side, raw assets are typically housed in cloud object storage solutions like AWS S3 or Google Cloud Storage, while multimodal embeddings are stored and queried using vector databases such as Milvus or Chroma DB.
Hardware and Software Requirements
A well-integrated stack of hardware and software components is essential for benchmarking. Beyond compute and storage, a monitoring layer is critical. Tools like Prometheus, Grafana, and OpenTelemetry provide real-time insights into aspects such as retrieval latency, resource usage, and error rates specific to each modality. Synchronizing datasets, models, and configurations with code updates is made simpler with version control tools like DVC (Data Version Control) or MLflow. These elements are vital for producing reliable benchmark outcomes, especially in complex multimodal scenarios.
One important consideration is memory usage. For example, decoding compressed images can cause a significant spike in memory consumption. To address this, systems need safeguards to pause processing before memory limits are exceeded. Tools like Daft help manage this with streaming execution models that automatically adjust the pace of upstream processing when GPU inference becomes a bottleneck, keeping memory usage in check.
Infrastructure-as-Code for Environment Replication
Using Infrastructure-as-Code (IaC) tools like Terraform minimizes the risk of manual configuration errors by codifying the entire benchmarking environment. This ensures staging environments closely resemble production, making results more consistent across teams and time periods. IaC frameworks also capture critical elements like configurations, random seeds, and software versions for better auditability.
Containerization, often through Docker, further enhances reproducibility. By isolating components - such as separating image processing models from text embedding services - updates can be applied to one part of the pipeline without disrupting others. A clear 'System Schema' should outline the hardware environment, including details like scheduler type, node lists, and global environment variables, independently of the testing logic. This allows flexibility across different infrastructures. Locking software versions with specific Docker tags or dependency managers is another way to prevent inconsistencies caused by library updates.
This modular setup not only simplifies unit testing for individual services but also allows each service to scale independently based on workload demands.
Key Metrics for Evaluating Multimodal Pipelines
When working with multimodal pipelines, evaluating their effectiveness requires a broad set of metrics. These systems handle multiple data types - text, images, audio, and more - so their evaluation spans three key areas: foundational skills like alignment and reasoning, task-specific processes like translation and fusion, and applications in fields like healthcare or affective computing. The tricky part? Finding a balance between comprehensive evaluation, low computational overhead, and avoiding data contamination - a challenge often referred to as the evaluation trilemma. These metrics are crucial for assessing model quality, efficiency, and how well they handle different modalities.
Quality Metrics
Quality metrics focus on two main areas: perception (e.g., identifying objects or attributes) and cognition (e.g., reasoning and logic). For text-to-visual tasks, VQAScore has proven to be a standout metric. It outperforms alternatives like PickScore, HPSv2, and ImageReward by a factor of 2–3 in aligning with human ratings for models such as DALL-E 3. Using the GenAI-Rank benchmark with over 40,000 human ratings, studies show VQAScore excels at evaluating how well a model handles complex, logic-driven prompts compared to traditional metrics like CLIPScore, which only measures global similarity.
Another critical factor is modality robustness - how well a system performs when some data streams are noisy or missing. This is especially important in fields like robotics or healthcare, where data inconsistencies (e.g., corrupted audio or missing images) are common. Tools like the MEGA-Bench suite highlight the scale of modern evaluation efforts, using over 40 metrics to assess 505 real-world tasks across 8,000 samples.
Efficiency and Cost Metrics
Efficiency metrics track how quickly and effectively a pipeline operates. Key considerations include latency (time from input to output), throughput (how many items are processed per second), and resource utilization (CPU, GPU, memory, and storage usage). Multimodal systems are far more resource-intensive than text-only models, often requiring 4–8x more GPU resources for fine-tuning. Maintaining these pipelines also demands significant effort, with around 80% of a data engineer's time spent on upkeep.
Costs go beyond compute time. For example, Amazon Titan Text Embeddings V2 charges about $0.02 per million tokens, and embedding generation for a typical deployment cycle can cost up to $134.22 based on volume. Many enterprise multimodal systems struggle, with 73% of deployments failing due to issues with cross-modal coordination. Techniques like QLoRA (4-bit quantization) help reduce memory needs, enabling larger batch sizes and cutting hardware costs without major accuracy trade-offs. Additionally, using spot instances or preemptible VMs for non-critical tasks can significantly lower cloud expenses.
Modality-Specific Metrics
Each data type in a multimodal pipeline requires tailored evaluation methods. For tasks involving mixed text and images, metrics like Image Coherence and Text-Image Coherence ensure visual elements align logically with accompanying text. For interleaved content, traditional similarity measures often fall short. Instead, reference-free metrics powered by advanced models like GPT-4o or Reka Core provide better insights. However, even with these tools, challenges remain - on the Vibe-Eval hard difficulty set, over 50% of questions stump current state-of-the-art multimodal models, underlining the need for more advanced evaluation methods.
To address the growing demands of multimodal systems, frameworks like MultiBench evaluate 10 modalities and 20 prediction tasks, offering a comprehensive view of how well models handle diverse data. As multimodal applications become more complex, there’s a clear shift toward compositional evaluation, which emphasizes higher-order reasoning rather than simple object recognition. This evolution reflects the increasing complexity of real-world use cases.
Optimization Techniques for Multimodal Pipelines
Once you’ve set your metrics, the next step is to fine-tune your pipeline for better speed, efficiency, and cost management. This involves everything from adjusting parameters to refining the structure of your development workflow. The ultimate aim? To clear out inefficiencies while maintaining accuracy across all data types.
Hyperparameter Tuning
Optimizing multimodal pipelines is no small feat because each type of data - be it text, images, or audio - has unique computational needs. A standout strategy here is modality-aware partitioning, which splits the pipeline into stages based on the type of data being processed. This prevents one data type from monopolizing resources while others are left idle. A great example of this is the PipeWeaver framework, which has shown to increase training efficiency for Large Multimodal Models by as much as 97.3% compared to older methods.
Another effective method is dynamic interleaved pipeline scheduling, which adjusts resource allocation on the fly to match the specific data mix in each batch. This is especially useful since multimodal data rarely comes in balanced batches in practical applications.
For added robustness, try introducing controlled noise to one data type during validation. For instance, you could add noise to audio data while keeping the text data clean. This tests how well your fusion layer can handle incomplete or messy data, preparing your model for real-world challenges.
| Optimization Strategy | Focus Area | Benefit |
|---|---|---|
| Modality-Aware Partitioning | Hardware/Infrastructure | Balances pipeline stages for diverse data types |
| Dynamic Interleaved Pipeline | Training Efficiency | Adjusts resources for unpredictable data mixes |
| Unimodal Noising | Model Robustness | Prepares models for noisy or missing data |
| Step Emulation (SEMU) | Search Efficiency | Speeds up finding optimal schedules via simulation |
These techniques not only improve performance but also pave the way for smoother integration into CI/CD workflows.
CI/CD Best Practices
After optimizing hyperparameters, it’s crucial to ensure these improvements are consistently applied through robust CI/CD practices. Multimodal systems are inherently complex, so your pipeline must be able to handle updates across different data types without causing disruptions. A modular architecture is key - using containers like Docker to isolate components (e.g., image processing models and text embedding services) ensures that updating one part doesn’t interfere with others.
Version control isn’t just for code. Tools like DVC and MLflow allow you to track changes in datasets and models alongside your code updates. This ensures everything remains reproducible.
Testing is another critical step. Conduct unit tests for individual components (e.g., an image resizing function) and integration tests to check how different modalities work together (e.g., whether a text-image search function delivers accurate results). Enforce performance gatekeeping by setting specific thresholds for latency and accuracy - if a deployment doesn’t meet these standards, it should be automatically rejected.
A real-world example of CI/CD catching inefficiencies comes from the Hugging Face team. In July 2025, they discovered their nanoVLM data pipeline was wasting 60% of batch space due to naive padding. Fixing this issue eliminated GPU idle time and produced much denser batches. This highlights the importance of continuous monitoring and feedback in catching inefficiencies early.
Feedback Loops and Continuous Monitoring
Static pipelines can quickly become outdated, which is why continuous monitoring and feedback loops are essential. These loops measure performance and feed insights back into the pipeline for ongoing refinement. The Probe-Analyze-Refine workflow is a great example - it runs small-scale trials with controlled data, analyzes how specific processes impact results, and adjusts configurations before full-scale deployment.
"A unified sandbox environment enables experimentation with guided optimization. It permits users to iterate both data and models based on comparative feedback from small-scale data processing and model training trials..." - Daoyuan Chen et al., Data-Juicer Sandbox
In June 2025, the Data-Juicer Sandbox team used this workflow to optimize multimodal models like InternVL-2.0 and EasyAnimate. By testing changes on less than 1% of their dataset, they analyzed over 40 data operators and 70 metrics, ultimately achieving top performance on the VBench leaderboard.
Real-time monitoring metrics like GPU utilization and padding waste can also make a big difference. Strategies like greedy or bin-packing knapsack techniques minimize wasted compute by efficiently distributing workloads across GPUs. This prevents scenarios where one GPU sits idle while others handle oversized batches.
For benchmarking, tools like VLMEvalKit are invaluable. Supporting over 200 multimodal models and 80 benchmarks, these toolkits automate distributed inference and metric calculations, saving time and ensuring reproducibility. To cut costs, enable early stopping for trials that show poor potential, and organize your data into quality tiers - repeat high-quality data more often while still mixing in diverse, lower-quality samples.
Analysis and Model Comparisons
Once you've optimized your pipeline, the next step is to dive into benchmark results. This means looking at factors like application type, input modality, output format (JSON, LaTeX, code), and skills such as instruction following or understanding detailed images. Research involving 12 top-tier models confirms there's no one-size-fits-all solution - different models shine in different areas, whether it’s handling factual data or tackling complex visual reasoning tasks.
To get a clearer picture, go beyond basic metrics. Multi-dimensional capability reporting can uncover trends that might be hidden by aggregate scores. For example, a model might excel at text-heavy tasks but falter when visual details are crucial. Common issues include language bias, where models overly depend on text prompts and disregard visual inputs, or problems like hallucinations and unnecessary refusals of valid prompts. Adding noise or incomplete data during testing can expose weaknesses in how well modalities are integrated. These deeper insights build on earlier optimization efforts, highlighting areas for further refinement and setting the stage for meaningful model comparisons.
Side-by-Side Model Comparisons
For fair comparisons, stick to standardized evaluation setups. This includes consistent scenarios, instructions, inference strategies, and metrics. Tools like VLMEvalKit, which supports over 200 multimodal models across 80+ benchmarks, make this process easier by automating distributed inference and metric calculations. Automation is especially critical now, as nearly 20% of the compute resources for cutting-edge models are dedicated solely to evaluation.
One useful tool for aligning model outputs with prompts is VQAScore. Testing has shown that ranking just 3 to 9 candidate images using VQAScore can be 2× to 3× more effective at improving human alignment ratings for models like DALL-E 3 compared to other methods. This approach allows you to refine pipeline performance without requiring additional fine-tuning.
Another key step is filtering out questions that can be solved with just one modality, such as text alone. In some multimodal benchmarks, as much as 70% of the questions fall into this category, which doesn’t provide a true test of multimodal capabilities. Additionally, converting multiple-choice questions into generative tasks can reveal performance drops of up to 35%, offering a more accurate view of a model’s actual abilities.
Debugging and Threshold Tuning
When performance gaps are identified through comparative analysis, debugging and threshold tuning can turn those insights into practical improvements. Start with batch size optimization. For instance, in Ray Data-based engines, keeping batch sizes as small as 10 rows for document embedding can help prevent out-of-memory crashes. Similarly, in Spark-based pipelines, limiting executor cores (e.g., spark.executor.cores=1) can stop multiple tasks from competing for a single GPU.
"Reliability trumps performance in production. It doesn't matter how fast something is if you can't even get a workload to run, or if it runs successfully only half the time." - Daft Engineering Blog
Attention visualization tools are another valuable resource. They help pinpoint reasoning errors by showing how models focus on different image regions during response generation. For memory-heavy tasks, using streaming execution with backpressure ensures that upstream processes slow down automatically if GPU inference becomes a bottleneck, keeping memory usage in check.
Threshold tuning also plays a big role in prompt selection. For multimodal RAG systems, the type of image prompt you use - like "What text appears in this image?" versus "Describe the graphical data" - can have a significant impact on retrieval accuracy. Testing consistency by shuffling options in multiple-choice questions and re-running queries helps verify that performance isn’t just due to lucky guesses. These small but targeted adjustments can lead to noticeable improvements across the entire pipeline.
Using NanoGPT for Multimodal Benchmarks

NanoGPT makes benchmarking multiple AI models easier by combining streamlined access, secure data handling, and cost-effective solutions - all in one platform. With access to over 400 AI models, including GPT-4.1 nano, Gemini, Flux Pro, DALL-E, and Stable Diffusion, it eliminates the hassle of juggling multiple subscriptions or worrying about data privacy during testing.
AI Model Access and Integration
NanoGPT simplifies workflows by offering an OpenAI-compatible v1/images/generations endpoint. This supports a variety of tasks, including text-to-image and image-to-image processes, and even allows advanced functionalities like multi-image inputs for models such as gpt-4o-image and flux-kontext.
Managing costs is also straightforward. The platform provides automated expense tracking - every API response includes details about the cost of the request and remaining balance. This real-time cost monitoring is particularly helpful during large-scale benchmarking sessions.
When it comes to pricing, GPT-4.1 nano stands out. At just $0.10 per 1 million input tokens, it’s about 80% cheaper per query than GPT-4.0, thanks to a 75% discount for cached inputs. For repetitive testing, this caching feature can significantly cut costs. To enhance security, generated files are deleted after 24 hours, and download URLs expire within an hour.
Privacy and Cost Advantages
NanoGPT puts privacy first by saving conversations locally on your device and ensuring providers do not train their models on submitted data. You don’t even need to create an account - your device is linked to your balance via a secure cookie, maintaining anonymity throughout the process.
"Conversations are saved on your device. We strictly inform providers not to train models on your data." - NanoGPT
The platform’s pay-as-you-go pricing model eliminates the need for multiple $20/month subscriptions. Instead, you only pay for the tokens you use during testing. A verified user, Craly, praised this flexibility:
"Prefer it since I have access to all the best LLM and image generation models instead of only being able to afford subscribing to one service."
This flexibility is invaluable for benchmarking workflows. For example, you can directly compare models like GPT-5 Nano (offering a 400,000-token context window) and Gemini to analyze cost-to-performance ratios without committing to long-term contracts. NanoGPT’s "Auto Model" feature even selects the best-performing model for specific queries, further simplifying the optimization process.
Conclusion
Balancing quality, cost-efficiency, and infrastructure stability is essential when optimizing multimodal benchmarks. Achieving this balance requires integrating environment setup with automated optimization tools like Infrastructure-as-Code, streaming execution, and dataset version control.
The best benchmarking workflows avoid exhaustive grid searches. Instead, automated frameworks pinpoint optimal model combinations while using significantly fewer GPU hours - 8.9× to 11.6× less - by clustering candidates with tools like CKA and employing early stopping. This method not only saves time but also reduces costs, which is especially valuable when testing hundreds of configurations. These savings highlight the importance of a dependable testing environment.
In production, reliability takes precedence over raw speed. As Daft's engineering team emphasizes:
Reliability trumps performance in production. It doesn't matter how fast something is if you can't even get a workload to run.
To ensure stability, stress-test CPU, GPU, and network resources simultaneously, confirming full utilization without failures.
The tools you choose can make or break your benchmarking process. NanoGPT, for instance, simplifies the process by eliminating the hassle of managing multiple subscriptions while offering seamless access to advanced AI models. Its pay-as-you-go model ensures you only pay for what you use, with clear cost tracking throughout benchmark runs.
Modern toolkits now support over 200 large multimodal models and more than 80 benchmarks, making comprehensive evaluations much easier. By combining standardized evaluation frameworks with flexible model access and dynamic scheduling techniques, you can create benchmarking pipelines that are both scalable and reliable - critical attributes for production systems. This approach aligns perfectly with the guide's focus on building efficient and dependable pipelines for multimodal model benchmarking.
FAQs
How do I prevent memory spikes during image or video decoding?
To keep memory usage in check during image or video decoding, it's important to fine-tune the NVDECODE API. Focus on managing buffer sizes, simplifying decoding workflows, and cutting back on unnecessary memory allocations. Also, take advantage of performance tuning guides to adjust buffer management and decoding settings. These tweaks can help improve memory efficiency and prevent sudden spikes during decoding operations.
Which metrics best capture both quality and cost for multimodal benchmarks?
The best metrics for multimodal benchmarks focus on three key areas: semantic accuracy, structural realism, and resource efficiency. While traditional metrics like BLEU and CIDEr are widely used, they often fall short in capturing subtle contextual details. Newer approaches, such as Physics-Constrained Multimodal Data Evaluation (PCMDE) and benchmarks like MMIG-Bench, take a more comprehensive approach. These frameworks assess multiple levels, including visual artifact detection and identity preservation, providing a more well-rounded perspective on quality and cost that aligns more closely with human evaluations.
How can I make multimodal benchmark runs reproducible across teams?
To maintain consistency across teams, it's crucial to use standardized and well-documented pipelines for tasks like data loading, setup, and evaluation. Structuring your code into modular sub-packages - such as those for datasets, evaluation scripts, fusion methods, and training frameworks - can make workflows more organized and easier to follow. Additionally, employing version control and sharing configuration files or scripts ensures that experiments can be replicated accurately across different environments. These steps are key to achieving consistency and reproducibility in multimodal benchmarking processes.