RNN Variants: Performance Comparison
When working with sequential data, selecting the right Recurrent Neural Network (RNN) architecture can make a big difference. Here's a quick breakdown:
- Vanilla RNNs: Simple and efficient for short sequences, but struggle with long-term dependencies due to the vanishing gradient problem. Computationally lightweight with fewer parameters.
- LSTMs: Best for tasks requiring long-term memory, like machine translation or text generation. They use three gates (forget, input, output) to manage information but are computationally intensive.
- GRUs: A streamlined alternative to LSTMs with two gates (update, reset). They perform similarly to LSTMs but train faster and use fewer resources, making them ideal for medium-length sequences.
Quick Comparison
| Feature | Vanilla RNN | LSTM | GRU |
|---|---|---|---|
| Best For | Short sequences | Long-term memory | Medium sequences |
| Parameters | Few | High | Moderate |
| Training Speed | Fast | Slow | Faster than LSTM |
| Memory Requirements | Low | High | Moderate |
| Performance | Limited for long sequences | Excellent for long-term dependencies | Similar to LSTM, slightly less expressive for long patterns |
| Complexity (O) | O(n) | O(4n) | O(3n) |
Key Takeaways
- Vanilla RNNs are simple and fast but lose context quickly.
- LSTMs excel in handling long-term dependencies but need more computational power.
- GRUs balance performance and efficiency, making them suitable for real-time applications.
For tasks like text generation, LSTMs lead the way. GRUs are better for resource-limited scenarios, while Vanilla RNNs work well for straightforward, short-sequence tasks.
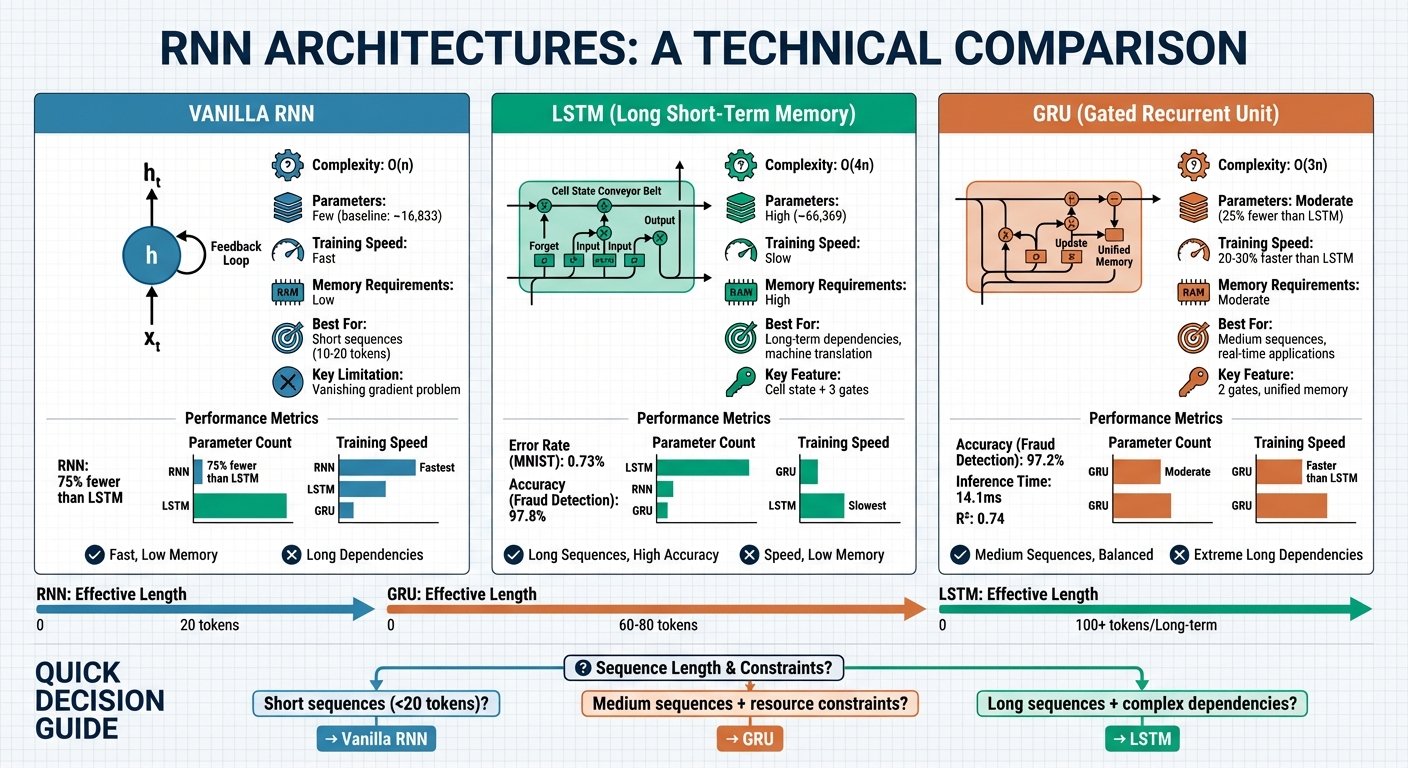
RNN vs LSTM vs GRU: Architecture Comparison and Performance Metrics
1. RNN
Architecture and Complexity
RNNs, or Recurrent Neural Networks, rely on a straightforward structure: an input layer, a recurrent hidden layer with shared parameters across time steps, and an output layer. Unlike feedforward networks that process data in one go, RNNs handle inputs sequentially. Each step's output feeds back into the network, creating a feedback loop. This loop generates a hidden state ($h_t$) that serves as the network's internal memory, retaining information from earlier inputs in the sequence.
The key to RNNs' efficiency lies in parameter sharing. The same weight matrices ($W_{xh}$, $W_{hh}$, $W_{hy}$) and biases are reused at every time step. The hidden state at each step is updated using the formula $h_t = \sigma_h(W_{xh}x_t + W_{hh}h_{t-1} + b_h)$, where $\sigma_h$ is typically a $tanh$ or $ReLU$ activation function. This design makes RNNs computationally efficient, achieving O(n) complexity - about four times faster than LSTMs, which operate at O(4n).
Training Performance
RNNs are trained using Backpropagation Through Time (BPTT), which unrolls the network over the sequence length to compute gradients. With roughly 75% fewer parameters than LSTMs, RNNs are faster to train. However, they face major challenges during training. Gradients can either shrink to near zero, making it difficult to learn dependencies over long sequences, or grow excessively large, destabilizing the learning process.
"RNNs perform well on short sequences but struggle to capture long-range dependencies due to their limited memory." - GeeksforGeeks
Task Accuracy
Research from Peter Makieu and colleagues at Suzhou University of Science and Technology (September 2025) demonstrated that while RNNs are adequate for tasks involving short sequences, they significantly underperform in complex spatial classification tasks compared to gated architectures like LSTMs or convolutional networks (CNNs).
Memory and Speed
RNNs require less memory than other recurrent architectures because they lack the gating mechanisms found in more advanced models. However, this simplicity comes with trade-offs. RNNs focus on recent information and quickly "forget" older inputs, making them unsuitable for tasks that demand understanding of longer contexts, like analyzing lengthy documents or conversations.
Another limitation is their sequential nature. Each step depends on the completion of the previous one, preventing parallel processing within a single sequence. This design limits their ability to fully utilize modern GPUs for speed. These drawbacks have driven the development of gated architectures, such as LSTMs, which are better equipped to handle long-term dependencies.
sbb-itb-903b5f2
2. LSTM
Architecture and Complexity
LSTMs, or Long Short-Term Memory networks, stand apart from standard RNNs by introducing a cell state that helps maintain information over extended time steps. They use three specialized gates: the forget gate (to discard unnecessary information), the input gate (to decide what new information to store), and the output gate (to determine what information to pass on). This design makes LSTMs more complex, with about four times as many parameters as standard RNNs, resulting in a computational cost of O(4n) .
"The cell state acts as a conveyor belt, allowing information to flow unchanged across time steps when the forget gate is fully open."
– Inovaqo
Training Performance
Training LSTMs can be slower because of their larger parameter count. For example, a study comparing dual-hidden-layer architectures showed that an LSTM model required 66,369 parameters, while a vanilla RNN needed only 16,833. This makes LSTM training more resource-intensive. However, the gating mechanisms in LSTMs ensure stable training, even with long sequences .
A July 2025 benchmark study on COVID-19 prediction in Jakarta demonstrated this stability. Using 634 daily records spanning March 2020 to December 2021, a standalone LSTM outperformed hybrid models. While training might take longer, LSTMs deliver better results for tasks involving long-term dependencies.
Task Accuracy
LSTMs are particularly effective in tasks requiring retention of information over longer durations. For instance, in August 2015, Thomas M. Breuel from Google, Inc. tested LSTMs on the MNIST dataset. By converting 28×28 pixel images into sequences of 28-bit vectors, a configuration of 660 LSTMs achieved a test set error rate of just 0.73%. A broader study with 5,400 experimental runs found that most LSTM variations don’t significantly outperform the standard architecture. The forget gate and output activation function were highlighted as the most critical components .
"The best performing networks in all experiments were 'standard' LSTM networks with no peephole connections."
– Thomas M. Breuel, Google, Inc.
Bidirectional LSTMs, which process data both forward and backward, consistently outperform unidirectional models across various network sizes .
Memory and Speed
LSTMs require significant computational power due to their intricate gating mechanisms, which demand more memory and processing capacity compared to standard RNNs or GRUs. Their sequential nature also limits parallel processing. Despite these challenges, LSTMs are the go-to choice for tasks involving very long sequences, as they can effectively capture dependencies from hundreds - or even thousands - of time steps prior. Applications like machine translation, document summarization, and speech recognition benefit greatly from this ability .
For medium-length sequences or when computational resources are limited, GRUs often serve as a more efficient alternative, offering similar performance with about 25% fewer parameters.
3. GRU
Architecture and Complexity
Gated Recurrent Units (GRUs) simplify the architecture of Long Short-Term Memory networks (LSTMs) while maintaining some of their advantages. GRUs combine the forget and input gates into a single update gate and introduce a reset gate. Unlike LSTMs, GRUs don't use a separate cell state; instead, they merge memory and hidden states into one unified structure. The reset gate decides how much past information to discard, while the update gate balances retaining old information with incorporating new input. This streamlined design reduces the number of parameters by about 25% compared to LSTMs, leading to a computational complexity of O(3n) versus the O(4n) of LSTMs.
Training Performance
Thanks to their simpler structure, GRUs often train faster than LSTMs. They tend to converge in fewer epochs - about 25% fewer - and train 20–30% faster overall. For instance, a 2014 study by Université de Montréal researchers tested GRUs and LSTMs on an internal speech signal dataset from Ubisoft. Using a dataset of 800 sequences, each with a length of 8,000, the GRU-RNN achieved a negative log-likelihood of 0.88, outperforming the LSTM-RNN's 1.26. GRU models also tend to be more compact, with production-ready models requiring less storage - e.g., 31 MB compared to 42 MB for similar LSTM models - making them ideal for environments with limited resources.
Task Accuracy
GRUs generally perform as well as LSTMs on tasks involving medium-length sequences. However, for very long or complex temporal patterns, they may fall slightly short in expressiveness. In a 2025 study, Harrison Blake from Harvard University evaluated GRUs on a dataset of 1 million anonymized banking transactions. The GRU model achieved 97.2% accuracy with an F1-score of 87%, compared to the LSTM's 97.8% accuracy and 88.4% F1-score.
"GRU offers nearly equivalent accuracy with superior speed, making it ideal for real-time applications with latency constraints."
– Harrison Blake, Harvard University
In February 2025, researchers at the University of Burgos demonstrated that GRUs excel in real-time scenarios. Their GRU-based model for predicting cognitive states from raw EEG data achieved an RMSE of 11.79 and inference times under 50 ms, making it suitable for real-time robotic control.
Memory and Speed
GRUs use less memory and offer faster inference times compared to LSTMs. For example, in the 2025 banking fraud detection study, GRUs achieved an inference time of 14.1 ms, significantly faster than the 22.3 ms of LSTMs, though slightly slower than vanilla RNNs at 8.5 ms. This combination of speed and accuracy makes GRUs a strong choice for real-time applications, particularly in resource-constrained tasks like sentiment analysis, short-to-medium text classification, and music generation. Their efficiency places GRUs among the top options for balanced performance in recurrent neural network architectures.
4.2 Recurrent Neural Networks: GRU vs LSTM & Solving Gradient Problems Explained
Strengths and Weaknesses
Each type of RNN comes with its own set of advantages and challenges. Vanilla RNNs are straightforward and efficient, making them a solid choice for handling short sequences, such as sensor readings or basic time-series data. However, they falter when dealing with longer sequences due to the vanishing gradient problem. This issue arises during backpropagation, where gradients shrink exponentially, making it difficult for the model to learn long-term dependencies.
LSTMs address this issue with a more intricate design that includes three gates - input, forget, and output - to manage information flow through a dedicated cell state. This structure allows LSTMs to excel in tasks requiring long-term context, such as machine translation or summarizing lengthy documents. However, this complexity comes at a cost: LSTMs are computationally demanding, with an operational complexity of O(4n). A large-scale study analyzing 5,400 experimental runs highlighted that the forget gate and output activation function are pivotal to the LSTM's performance.
GRUs simplify the LSTM's design by using just two gates - update and reset - while maintaining strong performance. They are approximately 3.84% faster to train under the same conditions, making them a great fit for medium-length sequences or scenarios where computational resources are limited.
"GRUs offer a good balance between performance and efficiency. They match or outperform LSTMs in some tasks while being faster and using fewer resources." – GeeksforGeeks
Despite their strengths, a shared limitation of all three architectures is their reliance on sequential data processing. Unlike modern Transformers, which can process entire sequences simultaneously, RNNs handle data step by step, creating a bottleneck when scaling to larger datasets. As a result, while Vanilla RNNs work best for short sequences, GRUs often strike the right balance for medium sequences, and LSTMs justify their computational demands when managing deep, long-term dependencies is essential. These trade-offs highlight how picking the right model can significantly influence AI applications, particularly in tools like NanoGPT.
NanoGPT and AI Model Access
NanoGPT takes theoretical AI concepts and makes them practical, bridging the gap between research and real-world application. While understanding RNN architectures is one thing, having access to ready-to-use models is entirely another. With 852 models available as of March 2026 - including 562 text models and 146 image models - NanoGPT provides a rich playground for developers and researchers alike. These models cover a variety of architectures, including RNN, LSTM, and GRU, giving users the tools to apply advanced AI insights directly.
The platform’s pricing is refreshingly straightforward. It operates on a pay-as-you-go basis, eliminating the need for monthly subscriptions. For instance, Amazon Nova Lite 1.0 costs $0.06 per 1 million input tokens and $0.24 per 1 million output tokens. If you’re looking for something more advanced, like GPT-5.2, it’s priced at $1.75 per 1 million input tokens. This flexible pricing model lowers the financial barrier, making cutting-edge AI tools accessible to startups, independent developers, and researchers.
NanoGPT also simplifies integration with its unified API, which is compatible with OpenAI endpoints like /v1/chat/completions. This means users can incorporate NanoGPT’s diverse models into existing workflows with minimal adjustments. For image generation, the platform supports popular models such as Stable Diffusion (SDXL), DALL-E, Midjourney, and Flux, all accessible through a single interface. Developers can browse the model catalog via GET /api/v1/models, filtering by architecture or cost, which streamlines the selection process.
Privacy is a top priority on NanoGPT. Unlike many platforms, it stores data locally on users’ devices rather than on centralized servers. This feature is particularly important for sensitive tasks, such as analyzing medical records or financial data. Additionally, the platform supports Secure GPU-TEE (Trusted Execution Environment) attestation, ensuring verified and secure inference for workloads that demand extra caution. These privacy measures make NanoGPT a safe option for experimenting with sensitive sequential data while addressing the challenges of working with such information.
Conclusion
Striking the right balance between performance, efficiency, and task complexity is essential, as highlighted by the analysis. GRU, with approximately 25% fewer parameters and an R² of 0.74 for short-term sequence prediction, stands out as the preferred choice for real-time applications and environments with limited resources. On the other hand, LSTMs shine in scenarios where managing long-term context is critical.
LSTMs are particularly effective when long-term dependencies need careful handling. Their three-gate structure provides a level of memory control that the simpler two-gate design of GRUs cannot achieve. For tasks like complex text generation - such as machine translation or medical diagnosis - LSTMs excel due to their ability to selectively "forget" unneeded information while maintaining distant context. As SabrePC observes:
"LSTMs are no longer state of the art for NLP, but they are not obsolete. They remain practical in latency-sensitive systems, streaming tasks, smaller datasets, and domains where sequential inductive bias matters".
In contrast, standard RNNs have become unsuitable for generation tasks as of 2026. Their inability to maintain context beyond roughly 10–20 tokens - due to the vanishing gradient problem - makes them impractical for anything beyond simple tasks like processing IoT sensor data.
Hybrid architectures are increasingly being adopted for specialized applications. For instance, a 2026 study published in Engineering Applications of Artificial Intelligence demonstrated that a CNN-LSTM-Attention model achieved an RMSE of 0.061 for wave height prediction, reducing error by 48.40% compared to standard LSTMs. Similarly, when applied to supercritical LNG heat exchangers, the same hybrid setup achieved error rates that were 81.5% lower than standalone LSTM models. By combining spatial processing with temporal memory, these architectures are particularly well-suited for tasks like video generation and image captioning.
FAQs
How do I choose between a Vanilla RNN, LSTM, and GRU for my sequence length?
Recurrent Neural Networks (RNNs) are great for handling short sequences, but they tend to falter when it comes to longer ones because of the vanishing gradient problem. That’s where LSTMs (Long Short-Term Memory networks) come in - they're specifically designed to manage long-term dependencies, making them a better fit for processing lengthy sequences.
On the other hand, GRUs (Gated Recurrent Units) offer a middle ground. They deliver performance similar to LSTMs but with fewer parameters, which often makes them faster, especially when working with smaller datasets or shorter sequences. If you're dealing with long and complex sequences, LSTMs are usually the go-to option. However, for simpler tasks where speed is a priority, GRUs are often the better choice.
What practical tricks help RNNs handle vanishing or exploding gradients?
RNNs can tackle the issue of vanishing or exploding gradients by using architectures such as LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit). These models are equipped with gating mechanisms that regulate the flow of information, helping gradients remain stable across time steps. This stability enhances both training efficiency and overall performance.
When should I use a hybrid model like CNN-LSTM-Attention instead of a plain RNN?
When dealing with tasks that require identifying intricate patterns in sequential data, especially those involving long-term dependencies and detailed feature extraction, a hybrid model like CNN-LSTM-Attention can be a game-changer. Here's why:
- RNN Limitations: Traditional RNNs often face challenges like vanishing gradients, making them less effective for capturing long-range dependencies in data.
- CNN Strengths: CNNs excel at extracting local features, making them great for identifying patterns within smaller segments of data.
- Attention Mechanisms: Attention layers help the model focus on the most relevant parts of a sequence, enhancing its ability to understand context.
This combination makes hybrid models particularly effective for advanced tasks like text or image generation, where a deep understanding of context and complex relationships is essential.