Scalable Design for Low-Latency Multimodal Pipelines
Low-latency multimodal pipelines process text, images, audio, and video in under 100 milliseconds, making them essential for tasks like fraud detection, patient monitoring, and live analytics. Speed matters: delays can harm user experience and business outcomes, with studies showing even small lags can lead to significant revenue losses.
This article compares three approaches to building such pipelines:
- NanoGPT: A streamlined, decoder-only system that processes diverse data types as uniform tokens. It’s simple and fast but struggles with image encoding bottlenecks.
- Monolithic Pipelines: Integrated systems that combine all stages on shared hardware. They’re easier to manage but often inefficient and prone to latency issues under mixed workloads.
- Custom Distributed Architectures: These break down the process into independently scalable stages. They deliver excellent performance and cost efficiency but require complex orchestration.
Each option has trade-offs in scalability, latency, privacy, and implementation complexity. The right choice depends on your specific needs - whether speed, simplicity, or flexibility is your priority.
1. NanoGPT

Scalability
NanoGPT employs a decoder-only architecture to handle all types of multimodal inputs - whether they’re images, audio, or text - by treating them as uniform tokens within a single transformer system. This streamlined approach eliminates the need for separate processing pipelines for each data type, making the overall design simpler and more efficient.
To integrate new input types, NanoGPT uses a connector module, often a Multi-Layer Perceptron (MLP), which aligns the diverse data formats before they enter the main processing engine. This means adding support for a new modality only requires training a lightweight layer, while the core language model remains unchanged. This approach keeps the system efficient and adaptable for tasks like text and image generation.
Latency Optimization
NanoGPT’s unified architecture also helps improve execution speed. The platform achieves faster performance by decoupling execution stages, allowing different parts of the process to be optimized independently rather than running sequentially. Specifically, it separates the prefill and decode stages, which helps reduce overall latency. However, encoding images remains a bottleneck, contributing between 25% and 54% of the total time-to-first-token (TTFT), depending on the model size.
NanoGPT also uses a pay-as-you-go pricing model with a $0.10 minimum, aligning costs directly with usage. This structure gives users access to multiple AI tools, including ChatGPT, Deepseek, Gemini, Flux Pro, Dall-E, and Stable Diffusion, without requiring upfront capacity planning.
Privacy and Data Handling
In addition to its performance features, NanoGPT places a strong emphasis on user privacy. It stores data locally on the user’s device rather than relying on centralized databases, ensuring that user prompts and generated content are not retained on external servers. The platform also allows users to access its services without creating an account. However, if operating as a guest, users should note that clearing browser cookies may result in the loss of balance information.
2. Traditional Multimodal Pipelines
Scalability
Traditional multimodal pipelines bundle image preprocessing, encoding, and text generation into a single, tightly integrated system that operates on shared hardware. This design forces every stage to scale as one, even when only specific components require additional resources.
The problem becomes evident with mixed workloads: vision encoders demand high memory bandwidth, while text decoders rely on different computational needs. However, applying uniform batching and parallelism across all stages leads to inefficient resource use. Research highlights that decoupling these components can deliver 3.3x to 5.5x higher throughput compared to monolithic setups.
"Current tightly coupled serving architectures struggle to distinguish between mixed request types or adapt parallelism strategies to different inference stages, leading to increased time-to-first-token (TTFT) latency and poor resource utilization." - Zedong Liu, Shenggan Cheng, et al.
This rigid architecture not only limits scalability but also creates latency issues, which will be discussed next.
Latency Optimization
Latency is another major hurdle in traditional pipelines. To reduce delays, these systems often rely on shared hardware, keeping all components on the same server to avoid the overhead of transferring large tensor data across machines. While this approach minimizes network delays, it introduces other bottlenecks.
For instance, image encoding is a significant issue, consuming 79% of TTFT in models like Llama3.2-11B and 54% in NVLM-D-72B. Image-heavy requests worsen the situation, causing head-of-line blocking - a single slow request with multiple images can hold up all subsequent tasks in the queue. In serverless setups, cold starts add another layer of delay, with traditional instances requiring over 40 seconds to generate the first token.
Implementation Complexity
The complexity of maintaining traditional pipelines adds to these challenges. The contrasting requirements of different modalities - such as high VRAM for vision, low latency for audio, and intricate attention mechanisms for text - make engineering and operations increasingly difficult.
Introducing new capabilities, like adding audio processing, often requires a complete overhaul of the system. Moreover, traditional pipelines have rigid validation systems that can halt an entire workflow if a single file fails, instead of enabling partial processing. It's no surprise that around 80% of AI development time is spent on data preparation rather than refining models.
3. Custom Distributed Pipeline Architectures
Scalability
Custom distributed architectures break down inference pipelines into separate, independently scalable stages. For instance, systems like ModServe and EPD (Encode-Prefill-Decode) divide the process into four main steps: image preprocessing, image encoding, LLM prefill, and LLM decoding. This separation allows each stage to scale independently based on demand. This design is particularly useful during image-heavy workloads, where the number of images in a request increases significantly without a corresponding rise in text volume. A practical example of this is a Microsoft Azure Research deployment on a 128-GPU cluster, which achieved 3.3–5.5 times higher throughput and reduced costs by 25–41.3%, all while meeting P99 TTFT (Time to First Token) requirements.
Since image encoding doesn’t require interaction between images, multiple images from a single request can be processed in parallel across distributed instances. This parallel processing, combined with the disaggregation in the EPD model, enables 22× larger batch sizes and reduces peak memory consumption by up to 15×.
Latency Optimization
Beyond scalability, this architecture also addresses latency issues through smarter request routing and parallel processing. Distributed systems reduce bottlenecks in image encoding by using parallel processing and modality-aware routing. Instead of relying on simple round-robin distribution, modality-aware routing assigns requests based on the number of pending tokens for each modality. This prevents image-heavy requests from clogging the pipeline and delaying text-only tasks, resulting in a 71% reduction in TTFT when using EPD disaggregation.
For serverless deployments, PipeBoost, a framework developed by Beihang University researchers in March 2025, introduces fault-tolerant pipeline parallelism. It optimizes GPU usage by reordering model layer loading, allowing inference to start before the entire model is fully loaded. Using the OPT-1.3B model, PipeBoost generated the first token in under 1 second, with the full model loaded in just 0.64 seconds. This approach reduced TTFT by 30–47% compared to standard serverless systems.
Implementation Complexity
While these distributed architectures deliver impressive performance improvements, they also introduce significant complexity. Effective orchestration is critical, particularly for managing inter-node communication during the transfer of large intermediate tensors between encoder and decoder nodes.
"Teams that succeed with multi-modal deployment treat the pipeline itself as a first-class system." – GMI Cloud
To ensure smooth operation, stage-level observability is essential. Metrics like queue depth and GPU memory pressure need to be monitored for each modality, rather than relying solely on overall request counts. Fault-tolerance mechanisms also play a key role, ensuring that node failures don’t disrupt the entire workflow. Additionally, careful decisions about co-location are necessary - stages exchanging large data artifacts should use shared memory or high-speed interconnects like NVLink to minimize data transfer overhead.
Despite these challenges, the flexibility of this architecture allows for the use of heterogeneous GPU pools, tailored to the specific needs of each stage. For example, vision encoders can benefit from high-VRAM GPUs optimized for memory bandwidth, while text decoders might perform better on hardware designed for attention mechanisms. Balancing these orchestration and co-location demands highlights the trade-off between optimizing latency and managing system complexity in scalable pipeline designs.
sbb-itb-903b5f2
Real-Time AI: Low Latency Solutions for Interactive Applications by Luca Vajani
Pros and Cons
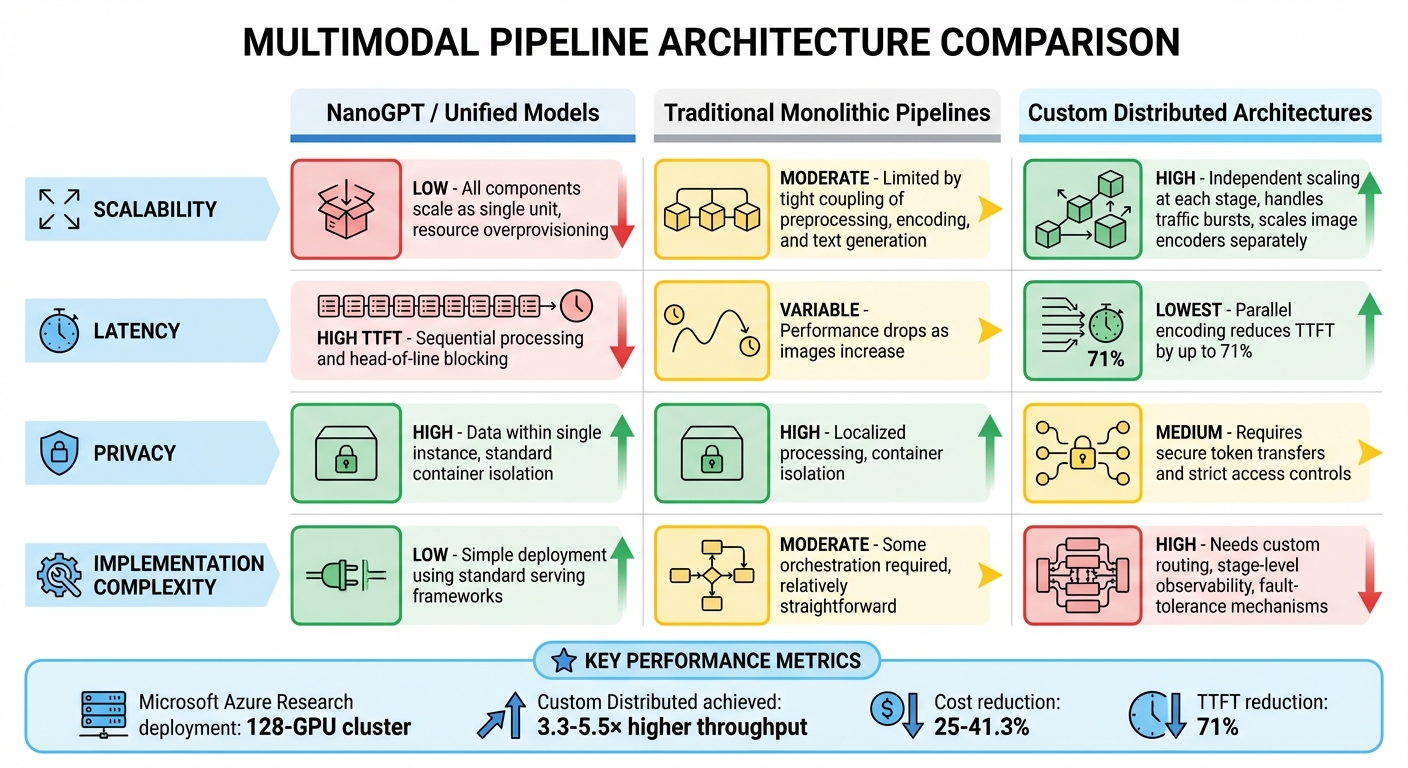
Comparison of Three Multimodal Pipeline Architectures: Scalability, Latency, Privacy, and Complexity
When it comes to building multimodal pipelines, each approach has its own strengths and weaknesses. The table below compares NanoGPT's unified model approach, traditional monolithic pipelines, and custom distributed architectures across four key areas.
| Feature | NanoGPT / Unified Models | Traditional Monolithic Pipelines | Custom Distributed Architectures |
|---|---|---|---|
| Scalability | Low: All components scale as a single unit, often leading to resource overprovisioning | Moderate: Limited by the tight coupling of preprocessing, encoding, and text generation | High: Independent scaling at each stage allows for better handling of traffic bursts, such as scaling image encoders separately |
| Latency | High time-to-first-token (TTFT) due to sequential processing and head-of-line blocking | Variable: Performance drops significantly as the number of images increases | Lowest: Parallel encoding reduces TTFT by up to 71% |
| Privacy | High: Data remains within a single instance with standard container isolation | High: Similar privacy benefits due to localized processing and container isolation | Medium: Requires secure token transfers and strict access controls |
| Implementation Complexity | Low: Simple to deploy using standard serving frameworks | Moderate: Requires some orchestration but is relatively straightforward | High: Needs custom routing, stage-level observability, and fault-tolerance mechanisms |
These trade-offs are reflected in real-world deployments. For instance, Microsoft Azure Research used a 128-GPU cluster running ModServe and achieved 3.3–5.5× higher throughput while cutting costs by 25–41.3% compared to monolithic systems. However, such performance gains come with added complexity. Distributed systems need advanced orchestration to manage inter-node communication and avoid bottlenecks during large tensor transfers.
"Deploying all stages on identical infrastructure creates contention and wastes resources. Instead, each stage should be treated as a separate service with its own scaling and scheduling behavior." – GMI Cloud
The choice between these architectures boils down to balancing performance against simplicity. If your team values speed and ease of deployment, unified or traditional pipelines might be the better fit. On the other hand, workloads involving video processing or multi-image requests can benefit greatly from the reduced latency and improved resource efficiency of distributed architectures - despite the added complexity. This comparison lays the groundwork for evaluating overall system performance in the next section.
Conclusion
Choosing the right architecture depends entirely on your deployment needs. Unified architectures are great for rapid prototyping because they’re simple to set up and allow for quick iterations. As GMI Cloud explains, "Cloud pipelines... are built for change, scaling systems from prototype to production". These features make unified setups ideal for smaller projects or early-stage development.
For enterprise systems managing millions of daily requests, custom distributed architectures can offer significant advantages. They shine when traffic patterns are unpredictable - like scaling image encoders independently during video-heavy surges. This approach helps prevent unnecessary resource use but does demand advanced orchestration, strong fault tolerance, and meticulous handling of inter-node communication.
Meanwhile, sensitive workloads call for trusted, isolated servers to ensure data security. Industries with strict regulations often rely on custom, isolated architectures to meet both performance and compliance requirements.
FAQs
What are the main advantages of using a custom distributed architecture for multimodal pipelines?
A custom distributed architecture for multimodal pipelines brings some clear advantages, particularly in scalability, efficiency, and low latency. By letting different components - like text, image, or audio processing - scale on their own, this setup ensures resources are used effectively and avoids bottlenecks. It’s a smart way to manage varying workloads without wasting capacity.
Another standout perk is the way it cuts down latency. Distributed architectures support parallel processing and reduce the need for data transfers between stages. This is a game-changer for real-time applications, such as autonomous vehicles or medical diagnostics, where speed and precision are critical. Using containerized microservices and distributed frameworks, each part of the pipeline operates independently, which boosts processing speed and system reliability. These qualities make distributed architectures a solid choice for building dependable, production-ready multimodal AI pipelines.
How does NanoGPT ensure privacy in multimodal data processing?
NanoGPT takes privacy seriously when handling multimodal data by ensuring all data is stored locally on the user's device. Unlike systems that rely on centralized servers, this setup keeps sensitive information - like personal images or audio - within the user's control. This approach minimizes the chances of data breaches or unauthorized access, offering an added layer of security.
What’s more, NanoGPT uses a pay-as-you-go model, eliminating subscriptions and the need for extensive data collection or long-term storage. This setup not only supports fast, scalable multimodal pipelines but also strengthens privacy by reducing reliance on external data handling. It’s a straightforward and secure way to process multimodal data efficiently.
What are the main challenges of using traditional monolithic multimodal pipelines?
Traditional monolithic multimodal pipelines come with a host of challenges, especially when it comes to complexity and scalability. Handling multiple components for diverse modalities - like text, images, audio, and video - can be a logistical headache. Each modality has its own demands in terms of computation and resources, making it tough to fine-tune performance and keep processes running smoothly.
These architectures also fall short in terms of scalability and flexibility. They’re typically built for fixed workflows, which makes it difficult to incorporate new modalities or handle varying workloads. On top of that, the tightly connected stages in monolithic systems can create higher latency since data has to flow sequentially through the entire pipeline. This becomes a major hurdle when trying to meet low-latency requirements, especially with large models or when working across multiple modalities.
Another major drawback is maintenance. Updating or modifying a single component often means re-testing and re-deploying the whole system, which adds to development time and operational complexity. Switching to a modular and scalable approach can help tackle these issues more effectively.