Smarter Load Balancing for AI Pipelines
AI routing should protect uptime first, then cut cost and delay. In this piece, I’d sum it up like this: use small models for simple work, cache repeat prompts, split batch from live traffic, send fixed-answer tasks to tools, route by live health signals, and add failover when providers slip.
Here’s the short version:
- AI traffic is uneven. One request can cost 100x more than another.
- Rate limits and slowdowns matter as much as outages.
- Most LLM calls don’t need top-tier models. The article cites about 70%.
- Caching can cut input cost by 50% to 90% and sharply reduce time to first token.
- Separating batch and live traffic helps keep chat and user-facing flows from getting stuck behind long jobs.
- Tool offloading removes model risk from math, lookups, and code checks.
- Metrics-based routing can move traffic away from weak backends before they fully fail.
- Failover orchestration handles the messy part: retries, 429s, 5xxs, and provider outages.
If I had to boil the whole article down to one rule, it’d be this: pick routing based on failure mode, not just traffic volume. That means asking, what is most likely to break first - quota, latency, cost, or provider health?
6 AI Load Balancing Strategies: Tradeoffs at a Glance
Multi-LLM Load Balancer: agentgateway for OpenAI GPT + Anthropic Claude Traffic

sbb-itb-903b5f2
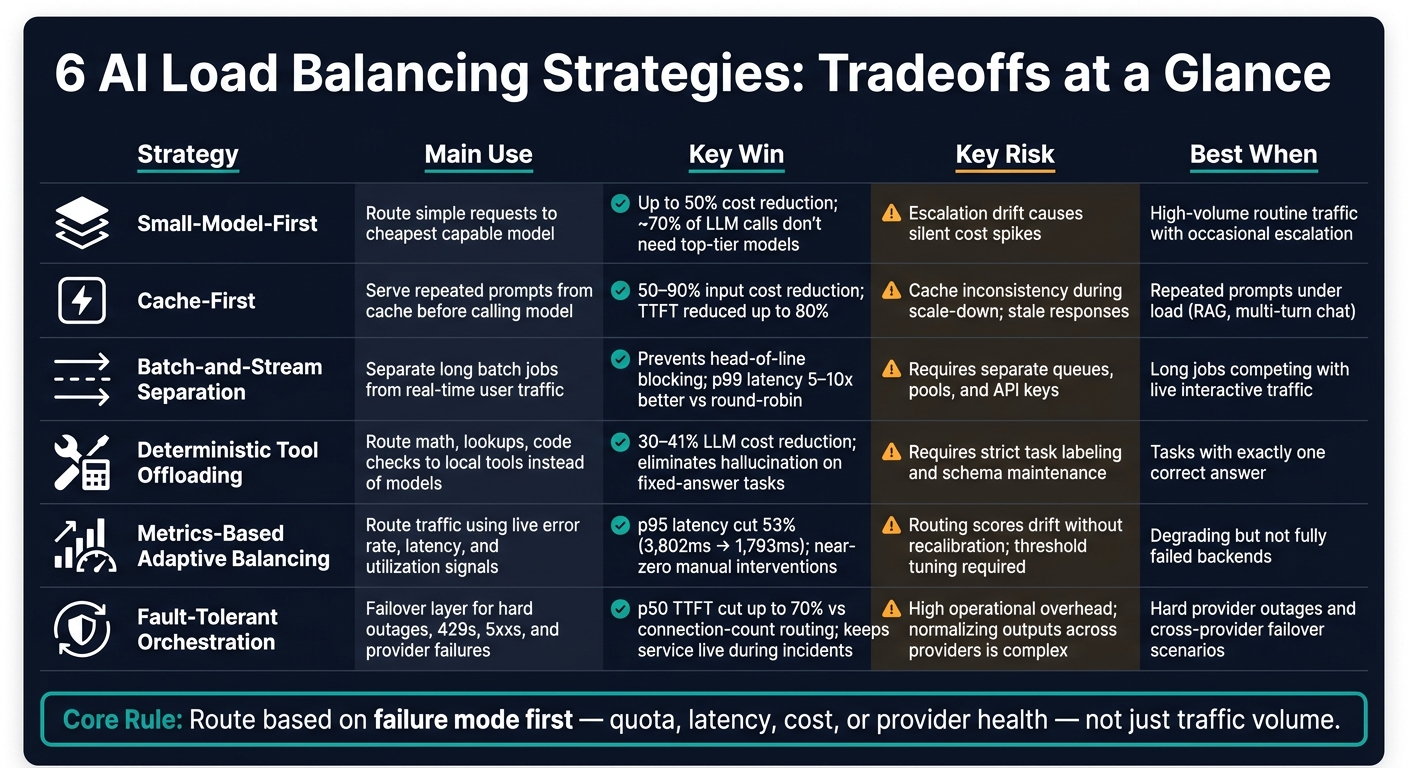
Quick Comparison
| Approach | Main use | Main win | Main risk |
|---|---|---|---|
| Small-model-first | Simple requests first | Lower model spend | Escalation drift |
| Cache-first | Repeat prompts | Fewer upstream calls | Stale or missed cache state |
| Batch-and-stream separation | Mixed workloads | Protects live traffic | More moving parts |
| Deterministic tool offloading | Fixed-answer tasks | Cuts hallucination risk | Task labeling work |
| Metrics-based balancing | Weak but not dead backends | Better routing under strain | Threshold tuning |
| Fault-tolerant orchestration | Hard failures and retries | Keeps service up during incidents | Cross-provider response mismatch |
So if you run multi-model AI systems, I’d treat routing as a failure-control layer first and a cost layer second. The rest of the article shows how each of the six methods handles overload, latency, outages, retries, and chain-reaction failure.
1. Small-Model-First Routing
Send each request to the lowest-cost model that can do the job, then move up only if schema checks fail, confidence drops, or the task needs deeper reasoning. This approach works well because about 70% of enterprise LLM calls don't need top-tier capability. Routine work like classification, sentiment analysis, intent detection, and extraction often fits smaller models such as GPT-4.1-nano or Llama-3-8B.
Put simply: if most of your traffic is basic, start basic. That makes small-model-first routing one of the easiest ways to improve resilience when the risky failures tend to come from a much smaller set of harder requests.
Failure Resilience
Small-model-first routing cuts the blast radius right away. If one provider has an outage, it mainly affects the complex tier, while simpler requests can still move through the smaller-model path. That alone can keep a lot of your system alive when things get messy.
It also helps with rate limits. High-volume, simpler traffic goes to lower-cost models, which leaves more room on premium models for the requests that actually need them. In production, rate limits cause more LLM request failures than full outages do.
Latency Impact
For most requests, latency improves because smaller models usually answer faster. If routing is based on static task labels, the added overhead is often under 1 ms. That's close to nothing.
The catch shows up on escalated requests. If a small model fails a schema check or misses a confidence threshold, you pay for that first pass before the larger model even begins. Content-based routing gives you more flexibility, but it often adds 5–20 ms of overhead. On chat, support, or other interactive flows, that extra step is worth watching.
Cost Efficiency
The gap in pricing between tiers is huge. GPT-4.1-nano costs $0.10 per million input tokens, while Claude Opus costs $5.00 per million input tokens. That's not a small difference.
Because of that spread, a cascade that resolves 70% of traffic on the cheap tier can cut total LLM spend by about 50% versus sending every request to frontier models.
Operational Complexity
This is where things can go sideways: bad routing can wipe out the gains. You need a classifier, response normalization, and an evaluation loop that catches quality drift before it turns into a quiet problem.
A simple starting point is to route with application-level task labels like classify or summarize. Then watch escalation rate closely. If that number keeps climbing, it's often a sign that drift, prompt edits, or workload changes are pushing more traffic - and more spend - into the larger tier.
2. Cache-First Distribution
A cache-first router checks for an exact match, or a close semantic match, before it calls the model. If it finds one, it serves the cached response right away. Simple idea, big payoff: repeat traffic stays off the model path, which helps keep the system steady under load.
The numbers are hard to ignore. Prompt caching can cut input token costs by 50% to 90% and reduce time to first token (TTFT) by up to 80%. At scale, smart scheduling cut TTFT from 35 seconds to 120 milliseconds and increased throughput by 151% on the same hardware.
Failure Resilience
This is where cache-first routing earns its keep. When a provider slows down, a warm cache can keep repeat requests flowing without sending every call upstream. That matters when providers degrade or start returning 5xx errors: repeated requests can still be served from cache instead of waiting on a shaky backend.
Some routers go a step further and push weak providers out of rotation. If uptime drops below a set threshold, the router can assign a penalty score and route around that provider. In one case, a provider running at 50% uptime got a penalty score of about 5.61, which was enough to move it out of the active pool.
Cache-first routing also helps during traffic surges. By catching repeated queries at the gateway, it avoids head-of-line blocking and the tail-latency spikes that show up when every single request has to pass through the inference engine.
Latency Impact
Cache-aware routing keeps identical prompts on the same replicas, which preserves KV locality. In benchmarks, that nearly doubled throughput. The catch is pretty clear: the speedup lasts only if cache locality stays steady.
Cost Efficiency
Cache-first distribution works best when prompts repeat. That includes:
- Multi-turn conversations
- RAG pipelines with shared system prompts
- Agentic loops that resend the same tool descriptions
With fewer upstream calls, you don't just spend less. You also cut down the number of places where a request can fail, which ties cost control directly to resilience.
A two-tier cache with an in-memory L1 and Redis L2 can cut provider calls by 40% to 60% for repeated prompts in chat apps. Semantic caching, which serves earlier completions based on prompt similarity instead of exact matches, usually reaches hit rates between 8% and 30% for support bots.
Operational Complexity
The tradeoff is operational overhead. Cache-first distribution adds work around invalidation and consistency. For example, an inference engine might evict a prefix cache when memory gets tight, while the router still assumes that cache entry exists. That leads to recomputation.
TTL settings can also bite you. If the TTL runs too long, freshness starts to slip. Semantic drift can pass 15% after about 5 minutes.
A common setup is a 60-second L1 cache and a 300-second Redis L2. When the miss rate climbs above 70%, bypass the cache.
3. Batch-and-Stream Separation
When batch jobs and live requests run through the same worker pool, things can go sideways fast. One long batch task can sit in front of short chat requests and slow everything down. That’s classic head-of-line blocking. It also helps explain why p99 latency with round-robin routing can be 5–10x higher than with least-outstanding-requests routing.
Even if the model is working fine, mixed pools are shaky. The bigger problem is spillover: one batch surge can eat up quota and push live traffic offline.
The fix is simple in theory: split batch and live traffic into separate lanes. Give each one its own queue, API keys, and routing policy.
Failure Resilience
If batch and live traffic share API keys, batch work can burn through the quota meant for live users. Separate rate limits keep that batch spike boxed in. Independent circuit breakers add another layer of protection, so a failure in the batch pool won’t trip the breaker for the live path.
Once you split traffic by workload, the next pressure point is routing speed inside each lane.
Latency Impact
Live traffic needs low TTFT. Batch jobs usually don’t.
That’s why token-aware routing helps. Instead of looking only at open connections, it tracks in-flight tokens, which gives a better read on queue pressure. A good target is p95 TTFT under 1,200 ms for live traffic, while batch jobs can live with a 30-second end-to-end window.
There’s another wrinkle with multi-turn chat. If you route a request back to the same replica that already holds the prior turn’s KV cache, you avoid extra recomputation. Batch jobs, by contrast, can lean toward throughput over fast response time.
Cost Efficiency
Not every request needs the top-shelf model. Route batch jobs to lower-cost models and keep premium models for live traffic. That split alone can cut total LLM spend by about 30%.
At high batch volume, self-hosting can also make sense. Running Llama-3-8B-Instruct on an L4 GPU costs about $200/month, which can beat per-token API pricing once usage gets high enough.
Operational Complexity
The router needs clear labels on every call, like chat, summarize, and classify, so it knows where each request belongs.
You also need a clean scale-down process. Drain batch replicas before shutting them down, and let in-flight generations finish within a 30–120 second timeout. If you cut them off too early, you risk corrupting long-running responses.
And static rules won’t hold up forever. When labels drift or the traffic mix shifts, routing has to follow live metrics, not old assumptions.
4. Deterministic Tool Offloading
When a task has one right answer, the best router often skips the model. That applies to math, database lookups, code execution, and build, lint, and style checks. Pushing those jobs through a large model burns tokens, slows the workflow, and adds risk you don't need. A better move is to send them to local tools and bring in the model only when it's actually needed.
This matters even more when one bad output can snowball into later steps.
Failure Resilience
Deterministic routing cuts hallucination risk off at the root. Models can confabulate - when they don't know something, they may fill the gap with something that sounds plausible but isn't true. That's a bad fit for jobs like checking whether a dataset link works or confirming a calculation.
Route those tasks to deterministic tools instead - a regex engine, a calculator, or a local REPL - and that failure path disappears from the model flow. The tool either returns a valid result or throws an error you can catch. That means one bad answer is less likely to spread into retries, alerts, or downstream automation.
Latency Impact
Local deterministic tools are fast. A regex match or calculator call can run in sub-millisecond time, which is much faster than token generation, so it's usually best to keep that work local unless freshness demands an external call.
The slowdown appears when a tool depends on external I/O, like scraping a web page or calling a third-party API. Those requests can take 10 seconds or more.
Cost Efficiency
Offloading deterministic work removes pricey model calls from the path. Routing rule-based tasks to tools - or to smaller models like GPT-4o-mini or Claude Haiku when a model is still needed - can cut total LLM spend by 30% to 41%.
For docs lookup, MCP tools such as Context7 or Docfork can pull current references and block deprecated API usage.
Operational Complexity
The main extra work is labeling tasks so the router can tell whether a job should go to a tool or a model. In production, it also helps to pin model versions with dated snapshot identifiers, such as gpt-4o-2024-11-20, instead of rolling aliases, because provider updates can change behavior.
A handy pattern is to use the LLM as a verifier, not the source of truth. Let the deterministic process produce the result first, then have the model check it rather than generate it. That keeps the model in a verification role.
5. Metrics-Based Adaptive Balancing
For the traffic that still needs model routing, live metrics should decide where each request goes. Static routing has a blind spot: it keeps sending traffic to backends even after they start slipping. Metrics-based balancing fixes that by watching live error, latency, and utilization signals, then shifting traffic before a backend falls apart.
Failure Resilience
Adaptive balancing depends on circuit breakers. A route moves from Healthy to Degraded, then Failed, based on error rate, rate-limit pressure, and recovery probes. For example, a route can shift to Degraded at 2% errors and Failed at 5% errors or when it hits a TPM limit. It also helps to keep a small exploratory traffic floor on failed routes so the system can spot recovery fast instead of waiting around.
In April 2026, Pinecone Assistant rolled out a service-aware balancer using the Power of Two Choices (p2c) algorithm. During a 12-day regional degradation of an LLM provider, which peaked at 1,288 unhealthy signals in a single day, the balancer kept chat throughput flat at 3,400–6,200 requests per day. Customers saw no outages or alerts.
Latency Impact
Latency needs context. Looking at it with one fixed threshold sounds simple, but it misses what’s right in front of you: request size changes everything. A 6-second response can be fine for an 8,000-token completion and still be a red flag for a 200-token request. That’s why token-aware scoring does a better job of spotting trouble. Systems such as MV-TACOS judge whether a latency value is actually odd for the request that produced it.
p2c helps here too. It samples two backends and sends the request to the healthier one, which cuts down on herding. In Pinecone’s case, moving from round-robin to latency-weighted p2c for embeddings cut p95 latency by 53%, from 3,802 ms to 1,793 ms.
Cost Efficiency
Cost drift is often the canary in the coal mine. One of the best live signals to watch is escalation rate. If that number starts climbing, a cheap model may be degrading and pushing traffic onto pricier fallbacks.
That’s exactly what happened in June 2026, when an engineer at Northwind found the cascade’s escalation rate had climbed to 90% over nine days. Watching escalation rate as a live cost signal can surface incidents like that early.
Operational Complexity
The routing logic itself is pretty light. Modern adaptive systems add under 10 microseconds to request-path latency, while weights recalculate asynchronously every few seconds. After Pinecone deployed its adaptive balancer, manual routing interventions dropped from about 3 per week to near zero.
The harder part is tuning the system so it behaves well under stress. That means setting metric weights, choosing state-transition thresholds, and defining service-specific rules. A practical rule of thumb looks like this:
- Use latency as the main signal for fast, structured calls like embeddings and rerankers.
- Lean more on reliability and load for LLM generation, where output length makes end-to-end latency too noisy to read on its own.
6. Fault-Tolerant Orchestration
If metrics-based balancing picks the healthiest path, orchestration decides what to do when that path starts to break.
Fault-tolerant orchestration adds a failover layer based on health signals. It routes traffic away from degraded providers before a small issue turns into a much bigger mess. And unlike adaptive balancing, this layer is about the recovery path after a route slips.
Failure Resilience
This layer matters most when failures aren't clean and obvious. In practice, many issues are partial, intermittent, or tied to one provider.
A circuit breaker is the usual first move. When error rate or latency passes a set threshold, open the route and shift traffic to a fallback. That handles hard outages, but it also helps with the more annoying case: providers that are still technically up, yet so slow that users feel the pain.
Error-aware routing helps too:
- Send 429s to another provider right away
- Retry 5xxs once or twice with jitter
- Move context-window overflows to a model with a larger context window
Latency Impact
Failover helps uptime, but it also changes response time. Every retry, fallback, or hedge adds some tradeoff.
Sequential fallback adds latency. Hedged requests can trim tail spikes by sending the same prompt to two providers at the same time, but they also double call cost. It's a classic speed-versus-spend choice.
At the orchestration layer, predicted-latency scheduling can cut p50 Time-to-First-Token (TTFT) by as much as 70% compared to standard connection-count routing. For multi-turn conversations, consistent hashing keeps a session on the same worker and avoids needless recompute.
Cost Efficiency
Tiered fallback can lower costs by routing simpler work to cheaper models.
But there's a catch: retries and hedging can burn through those savings fast. What looks cheap on paper can get expensive once failure handling kicks in.
Operational Complexity
The biggest build burden is keeping fallback responses compatible.
The hard part is schema and response consistency across providers. Different SDKs, different error codes, different output shapes - it adds up fast. Normalize SDKs and error codes first, then validate structured output at the boundary before sending it downstream.
It's also smart to add graceful draining during scale-down or model updates: stop new traffic, then let in-flight requests finish.
Pros and Cons of Each Approach
Every approach fixes one bottleneck and introduces another. That's the tradeoff in plain English. The table below sums it up.
| Approach | Best At | Weakest Point | Best When |
|---|---|---|---|
| Small-Model-First | Up to 50% cost reduction on routine traffic | Escalation drift causes silent cost spikes | High-volume routine traffic with occasional escalation |
| Cache-First | Sharply lower TTFT on repeated prompts | Hard to keep consistent during scale-down | Repeated prompts under load |
| Batch-and-Stream | Prevents batch traffic from slowing live requests | Needs separate queues, pools, and keys | Long jobs competing with live traffic |
| Deterministic Tool Offloading | Keeps deterministic tasks out of model paths | Requires strict schema maintenance | Tasks with one correct answer |
| Metrics-Based Adaptive | Cuts p50 TTFT by routing to the healthiest backend | Routing scores drift without recalibration | Degrading but not failed backends |
| Fault-Tolerant Orchestration | Turns outages into fallback traffic | High operational overhead; normalizing outputs across providers | Hard provider outages |
In practice, the strongest setups usually pair one optimization layer with one recovery layer.
Adaptive balancing and fault-tolerant orchestration work well together because they solve different problems. Adaptive balancing sends requests to the fastest healthy backend. Fault-tolerant orchestration takes over when a backend stops running. Put them side by side, and you get coverage for both slow decline and hard failure.
Caching and small-model routing are another strong match, especially when the same requests show up again and again. One trims repeated work. The other trims unnecessary model usage. Together, they cut both model calls and escalation volume.
In AI pipelines, the best load balancer is often the one that fails in the least damaging way. The danger isn't always a crash you can spot right away. It's the quiet kind of failure: escalation creeps up, output quality slips, and spend climbs before normal alerts go off. So the better question isn't which method wins in every case. It's which kind of failure you need to absorb first.
Conclusion
Across all six approaches, the pattern is pretty simple: protect the system from failure first, then tune for efficiency.
No single routing strategy works for every AI pipeline. The smart place to start is with failure handling. Absorb failures first. Then improve latency and cost where the workload actually makes it worth doing. Health checks, circuit breakers, and metrics-based routing deal with the most damaging failure modes - hard outages and slow backend degradation - before you layer anything else on top.
Once that base is steady, add workload-specific tuning only where traffic patterns repeat or queue pressure is easy to spot. When the core layer is stable, add caching for repeat traffic and separate long batch jobs from real-time requests. Start with resilience. Add complexity only when it makes a clear difference in latency or cost.
FAQs
Which routing strategy should I implement first?
Start with health-checked routing. It tracks the live status of each provider and sends traffic only to healthy endpoints. That helps users avoid slowdowns caused by timeouts or outages.
Once that base is in place, you can add more advanced routing, like cost-weighted, latency-weighted, or task-aware routing.
How do I know when to use a smaller model or a tool instead?
Use a smaller model or a specialized tool when the job is simple enough to handle well without any drop in output quality.
A common approach is capability-weighted routing. In plain English, that means you save your more powerful, resource-heavy models for hard reasoning tasks or creative work, and send routine requests or simple classification jobs to smaller options.
That split helps balance performance, cost, latency, and resource use across your pipeline.
What metrics matter most for safe AI traffic routing?
Prioritize metrics that show backend health and capacity as it happens, not just raw connection counts.
Watch the numbers that tell you when the system is starting to strain:
- Queue depth and queue-to-compute ratio help you catch saturation and bottlenecks early
- Rate limit consumption helps you avoid 429 errors
- Error rates (400, 500, 503) help you reroute traffic away from unhealthy nodes
- First-token latency and token throughput show the model’s actual load, not just how many requests are coming in