Static vs. Dynamic Data Masking: Key Differences
Static and dynamic data masking are two critical methods for protecting sensitive information, but they serve different purposes. Static masking permanently replaces sensitive data in non-production environments, while dynamic masking hides data in real-time based on user roles. Each approach has unique strengths and is suited to specific use cases.
Key Takeaways:
- Static Data Masking (SDM): Used for non-production environments like testing and development. Permanently alters data to prevent exposure, ensuring security even in case of breaches.
- Dynamic Data Masking (DDM): Ideal for production environments. Masks data on-the-fly, allowing role-based access without modifying the original database.
Quick Comparison:
| Factor | Static Masking | Dynamic Masking |
|---|---|---|
| Modification Type | Permanent | Temporary (query-time) |
| Use Case | Non-production (testing/dev) | Production (role-based access) |
| Performance Impact | None | Possible query delays |
| Data Security | Protects against breaches | Protects against unauthorized views |
| Storage Requirements | Requires duplicate databases | No extra storage needed |
Choosing the right method depends on your needs: Use static masking for long-term data protection in non-production systems and dynamic masking for real-time security in live environments. A hybrid approach often works best for organizations managing both scenarios.
Static vs Dynamic Data Masking: Key Differences Comparison Chart
What is Data Masking? Importance & Techniques
sbb-itb-903b5f2
What is Static Data Masking?
Static data masking (SDM) is a method used to permanently replace sensitive information in a database with fictitious, yet realistic, values. Think of it as creating a sanitized version of your production database - a clean copy where real names, Social Security numbers, credit card details, and other sensitive data are swapped out for fake but functional counterparts. The original database remains untouched, while this masked copy is handed over to developers or testers.
Once data is masked, it cannot be reverted to its original state. This irreversible transformation makes SDM especially useful for non-production environments, which often lack the rigorous security controls found in production systems. If a test database gets breached, only meaningless, fabricated data is exposed. This one-way process is what sets SDM apart in terms of security and usability.
Another key advantage of static masking is that it maintains the database's referential integrity. For example, masked Social Security numbers or credit card numbers still follow their expected formats, so developers can perform realistic tests without risking exposure of actual customer data.
Key Features of Static Data Masking
Static data masking works by transforming entire datasets in one batch operation, rather than processing individual queries. This process generates a fully masked copy of the database, stored separately from the production environment. Since the masking is applied beforehand, it eliminates any performance impact during testing.
The masked data also retains the format and statistical properties of the original data. For instance, a masked phone number still looks like a phone number, dates remain valid, and numerical values keep their natural distribution. This ensures that testing remains as realistic as possible, helping developers catch bugs or issues earlier in the development process - all while keeping sensitive data secure.
How Static Data Masking Protects Privacy
Static data masking addresses a critical vulnerability in many organizations: the lack of security in non-production environments. By permanently replacing sensitive data with fictitious values, SDM ensures that even in the event of a breach, no real data is at risk.
"If a database is breached, only static data masking will protect sensitive data from compromise. That's because the sensitive data in the database itself has been replaced with irreversible fictitious values." - Perforce Delphix
In the next section, we’ll dive into dynamic data masking to see how it compares and complements static masking.
What is Dynamic Data Masking?
Dynamic data masking (DDM) works differently from static masking. Instead of permanently altering data in the database, DDM masks sensitive information in real-time as users access it. The original data stays untouched - only the results of a query are modified, depending on the user's access permissions.
Think of DDM as a security filter that operates between users and the database. When a query is executed, DDM intercepts the request and applies masking rules on-the-spot before presenting the results. For example, a customer service representative might see a Social Security number as XXX-XX-1234, while a manager with higher access rights sees the full number, 123-45-6789. Both users are accessing the same record, but DDM ensures they only see the information appropriate for their role.
"Dynamic data masking is when sensitive data is masked in real-time, at the point when it is accessed by users and applications." - Laura Case, Director of Product Marketing, Baffle
This real-time functionality makes DDM especially useful in production environments where the original data must remain available for authorized operations. It operates at the presentation layer, which means it has minimal impact on existing applications and often requires no changes to code or database queries.
Key Features of Dynamic Data Masking
DDM relies heavily on role-based access control (RBAC) to determine what each user can see. Organizations can create detailed masking policies, customizing them for specific columns, tables, schemas, or even entire databases. For instance, in SQL Server 2022 and later, administrators can assign UNMASK permissions at various levels, allowing for precise control over who can view sensitive data.
The masking functions are flexible and can adapt to different contexts. Common examples include:
- Default masking: Replacing data with generic values.
- Email masking: Showing only part of an email address (e.g.,
j***@example.com). - Partial masking: Displaying only certain characters, such as the last four digits of a Social Security number.
- Credit card masking: Hiding all but the last few digits of a credit card number.
Unlike static masking, which requires creating separate masked copies of a database, DDM works directly with the production database. This eliminates the need for duplicate datasets, reduces storage costs, and ensures everyone is working with up-to-date information - even though users see different versions of the data based on their access rights. These features make DDM a practical solution for real-time data protection.
How Dynamic Data Masking Protects Data in Real-Time
With each query, DDM evaluates the applicable masking policies and automatically applies the correct masking function to sensitive data. For example, it might show only the last four digits of a Social Security number for a customer support query, allowing the user to verify critical details without exposing the full data. This ensures sensitive information never leaves the database in its raw form when accessed by unauthorized users.
"Dynamic data masking (DDM) limits sensitive data exposure by masking it to nonprivileged users. It can be used to greatly simplify the design and coding of security in your application." - Microsoft
That said, DDM is not a comprehensive solution for all security threats. It does not protect against direct database breaches - if someone gains unauthorized access to the database itself, the unmasked data remains available.
To strengthen security, DDM should be paired with additional measures like auditing and encryption. Monitoring database activity is also crucial, as users might try to infer masked values through repeated queries. Following the principle of least privilege - granting UNMASK permissions only to those who genuinely need access to unmasked data - is an essential part of a robust security strategy.
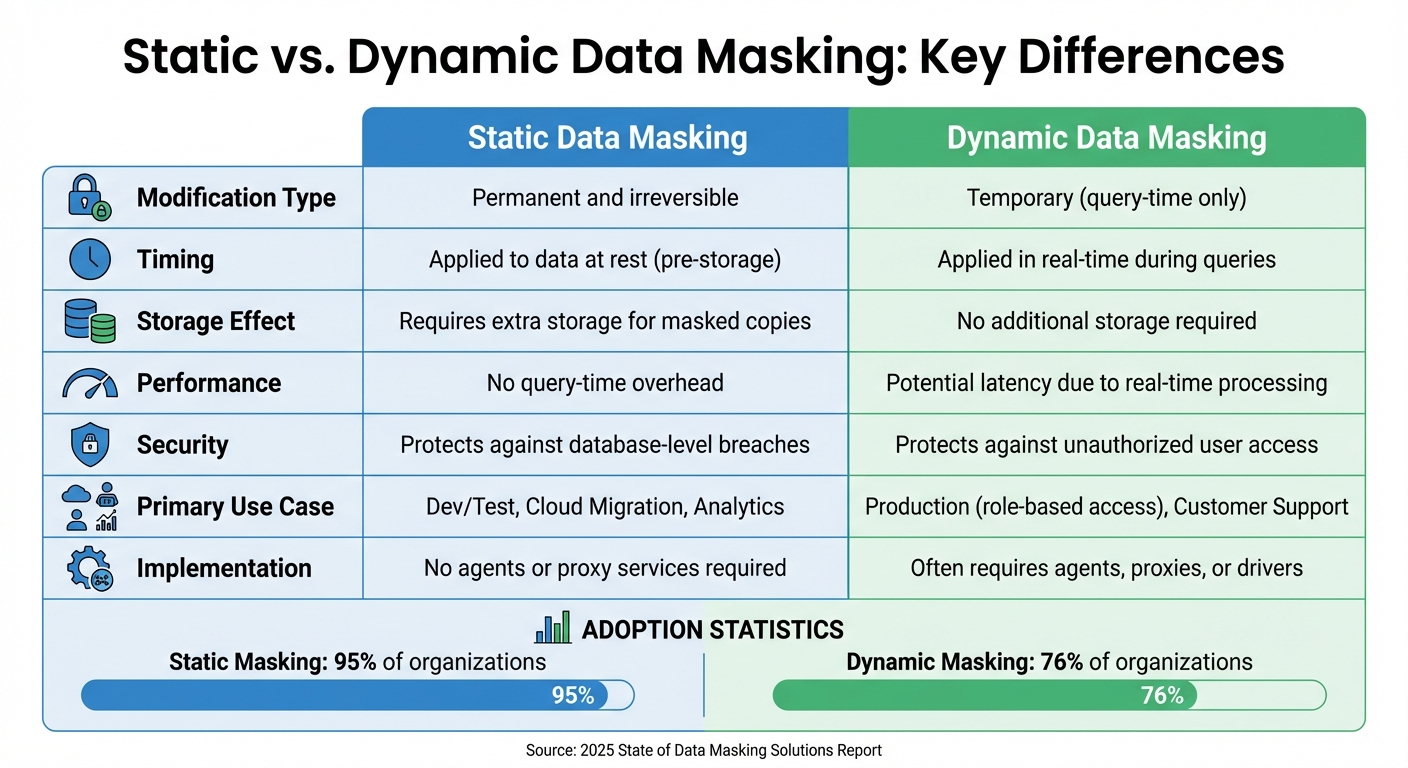
Static vs. Dynamic Data Masking: Direct Comparison
Let’s break down the key differences between static and dynamic data masking. Static masking permanently alters data before it’s stored, while dynamic masking modifies data in real time during queries. This fundamental distinction impacts how each method handles data and its security implications.
With static masking, the data is permanently changed, creating separate masked copies of the database. This approach increases storage requirements but ensures that non-production environments, like testing or development, contain no actual sensitive data. On the other hand, dynamic masking works directly on the production database. It leaves the original data untouched, which can be risky if the database is ever compromised.
Another difference lies in performance. Static masking is a one-time process, meaning it doesn’t affect query speed. Dynamic masking, however, evaluates access permissions with every query, which can introduce delays. According to the 2025 State of Data Masking Solutions Report, 95% of organizations reported using static masking, while 76% utilized dynamic masking. These statistics highlight the importance of choosing a method that aligns with specific operational needs.
"If a database is breached, only static data masking will protect sensitive data from compromise." – Ilker Taskaya and David Wells, Perforce Delphix
When deciding between the two, static masking is best for non-production environments like development, testing, or analytics. Its permanent alteration of data minimizes exposure risks. Dynamic masking, however, is ideal for production workflows. It allows authorized users, such as fraud investigators, to view unmasked data while presenting redacted versions to others, like customer service teams.
Comparison Table: Key Differences
| Factor | Static Data Masking (SDM) | Dynamic Data Masking (DDM) |
|---|---|---|
| Modification Type | Permanent and irreversible | Temporary, only for presentation |
| Timing | Applied to data at rest (pre-storage) | Applied in real time (query-time) |
| Storage Effect | Requires extra storage for masked copies | No additional storage required |
| Performance | No query-time overhead | Potential latency due to real-time processing |
| Security | Protects against database-level breaches | Protects against unauthorized user access |
| Primary Use Case | Dev/Test, Cloud Migration, Analytics | Production (role-based access) and Customer Support |
| Implementation | No agents or proxy services required | Often requires agents, proxies, or drivers |
This table clearly illustrates how each method serves a distinct purpose in protecting sensitive data at different stages of its lifecycle.
Pros and Cons of Static Data Masking
Static data masking offers a reliable way to secure non-production environments, but it comes with its own set of trade-offs. Perhaps its most notable advantage is its irreversibility - once data is masked, it’s impossible to reverse-engineer it back to its original form. This ensures that, even in the event of a database breach, only fictitious data is exposed.
Another benefit is that static masking introduces zero query overhead. Since the data is already masked at rest, there’s no performance hit during queries. It also preserves referential integrity, making it compatible with older systems like mainframes and flat files that are challenging to mask dynamically. However, these benefits come with some challenges.
One major drawback is the cost of storage and maintenance. Creating and managing duplicate masked copies of databases increases storage requirements and operational complexity. For example, in July 2024, Proximus reported an 85% reduction in non-production data storage costs after optimizing their static masking processes. This shows the potential for optimization, but the initial costs can still be steep.
Another issue is data staleness. Masked datasets can quickly become outdated as production data evolves. Keeping them current requires periodic refreshes, which are both time-intensive and resource-heavy. To illustrate, Boeing Employees Credit Union (BECU) masked 680 million rows of data in a 15-hour operation in July 2024. This demonstrates the scale of effort needed for large datasets.
Below is a quick overview of the pros and cons:
Static Data Masking Pros and Cons Table
| Advantages (Pros) | Disadvantages (Cons) |
|---|---|
| Irreversible Protection: Prevents reverse-engineering, safeguarding against breaches | Storage Costs: Maintaining duplicate masked databases significantly increases storage needs |
| High Performance: No query delays since data is pre-masked | Data Staleness: Masked datasets require frequent updates to match production changes |
| Referential Integrity: Supports complex relationships across systems | Not for Live Use: Unsuitable for production environments where real data is essential |
| Broad Compatibility: Works seamlessly with databases, mainframes, and various file types | Initial Processing Time: Masking large datasets can be a lengthy process |
| Regulatory Compliance: Simplifies audits for frameworks like GDPR, HIPAA, and CCPA | Management Overhead: Requires lifecycle management for multiple masked datasets |
While static data masking is a powerful tool for securing non-production data, it demands careful planning to address its storage and refresh challenges effectively.
Pros and Cons of Dynamic Data Masking
Dynamic data masking works by applying masking rules in real time. This ensures that sensitive information is only fully visible to authorized users. For example, a fraud investigator might access complete credit card numbers, while a customer service representative would only see the last four digits.
A report from 2025 highlights that 76% of global enterprise leaders have adopted dynamic masking. This approach eliminates the need for duplicate databases, significantly reducing storage costs. Additionally, centralized policies allow for instant updates across thousands of columns.
However, this technology isn't without its challenges. Evaluating access rights and applying masking rules for each query can create performance bottlenecks, especially in environments handling high-speed, large-volume data.
Another concern is its vulnerability to inference attacks. Since the original data remains intact, attackers could potentially craft queries to deduce sensitive information. Microsoft emphasizes this limitation:
"Dynamic data masking is appropriate for preventing accidental sensitive data exposure, but doesn't protect against malicious intent to infer the underlying data".
If a database is breached, any unmasked data becomes exposed, presenting a significant security risk. Below is a table summarizing the advantages and disadvantages for a clearer understanding.
Dynamic Data Masking Pros and Cons Table
| Advantages (Pros) | Disadvantages (Cons) |
|---|---|
| Real-Time Flexibility: Masks data during query execution based on user roles, leaving the original database untouched. | Performance Overhead: Adds latency as masking logic is applied with every query. |
| No Data Duplication: Removes the need for maintaining separate masked database copies. | Breach Vulnerability: Sensitive data remains at risk if the database is compromised. |
| Granular Access Control: Role-based policies allow tailored access, showing full, partial, or masked data as needed. | Inference Attack Risk: Attackers may deduce original data through crafted queries or brute-force methods. |
| Centralized Policy Management: Simplifies the process of updating masking rules across thousands of columns. | Implementation Complexity: Often requires additional tools like proxy servers or specific drivers to intercept queries. |
| Preserves Data Integrity: Original data remains unaltered, ensuring usability for authorized users and administrative tasks. | Limited Data Source Support: Difficult to apply on legacy systems, flat files, encrypted columns, or mainframes. |
Use Cases for Static and Dynamic Data Masking
Static and dynamic data masking each serve distinct roles, and knowing when to use them can help safeguard sensitive data while avoiding compliance issues.
When to Use Static Data Masking
Static data masking works best in non-production environments. For development and testing teams, having access to realistic data without exposing actual customer information is crucial. Static masking achieves this by permanently altering sensitive data before it’s sent to testing or development servers.
This approach is also essential when sharing data with third parties, such as external vendors, contractors, or offshore teams. By masking sensitive information beforehand, you ensure that data remains secure as it crosses organizational or geographic boundaries. Similarly, static masking is valuable during cloud migrations. Masking data before moving it to the cloud minimizes the risk of exposure and aligns with the shared responsibility model required by cloud providers.
Analytics and business intelligence teams often favor static masking because it eliminates the performance issues associated with real-time processing. Data scientists can perform complex queries on large datasets without the delays that dynamic masking might introduce.
"Data masking isn't just about protecting information; it's about keeping business moving at the speed it needs to".
Static masking is also the go-to solution for mainframe and legacy systems, which often lack the infrastructure needed to support dynamic masking. In these environments, static masking is the only practical option.
Now, let’s explore how dynamic masking addresses the needs of live production environments.
When to Use Dynamic Data Masking
Dynamic data masking shines in production environments, where users with different roles require varying levels of access to the same data. A common example is in healthcare settings: a doctor treating a patient needs full access to medical records, while billing staff should only see partial details. Dynamic masking applies these role-based rules in real-time, ensuring that users only see what they are authorized to view, without the need to create separate database copies.
The financial sector also relies heavily on dynamic masking, particularly in customer service. For instance, bank tellers may only access the last four digits of a Social Security number or credit card, while fraud investigators can view complete details when necessary.
Dynamic masking is particularly useful in live troubleshooting scenarios. When developers or support teams need temporary access to production data to resolve issues, dynamic masking allows controlled visibility. This ensures that sensitive data stays protected while users see only the information their role permits.
For external collaboration, dynamic masking offers a secure alternative to sharing static copies. Organizations can grant time-limited access to production systems with masking rules applied based on the external user's role. This approach ensures that sensitive data remains secure while still allowing necessary access.
In the next section, we’ll guide you on how to choose the right masking method for your organization’s specific needs.
Conclusion: Choosing the Right Data Masking Method
Deciding between static and dynamic data masking comes down to where your data resides and how users need to access it. Interestingly, recent statistics reveal that 95% of organizations lean toward static masking, while 76% also employ dynamic masking - many opting for a mix of both.
To determine the right fit, consider specific use cases. For non-production environments like development, testing, or analytics, static data masking is often the go-to choice. It permanently replaces sensitive information, ensuring that even if a test database is compromised, the data remains useless to unauthorized parties. Plus, it eliminates query-time processing delays, making it highly efficient.
On the other hand, dynamic data masking is ideal for production systems. It provides role-based access to live data, applying masking rules in real time. For example, a customer service agent might only see partial account numbers, while a fraud investigator has access to complete details. This approach reduces the need for maintaining duplicate databases, though it may introduce slight query-time delays.
Many organizations find a hybrid approach works best, combining static masking for non-production security with dynamic masking for production flexibility. This strategy allows companies to address diverse operational needs effectively.
Ultimately, selecting the right data masking method depends on your organization’s storage requirements, performance expectations, and compliance obligations. Align your choice with these factors to secure sensitive data while maintaining seamless operations.
FAQs
What are the performance differences between static and dynamic data masking?
Static data masking (SDM) involves altering sensitive data at rest through a one-time process, resulting in a masked version of the database. After this initial step, the database operates like any standard non-production instance, with no further impact on performance. The only system resources utilized are during the masking process itself, which engages the CPU and I/O systems.
Dynamic data masking (DDM) works differently. It handles sensitive data on the fly, intercepting and modifying queries in real-time as they are executed. While this approach ensures data is masked dynamically, it does come with a trade-off: added processing overhead. Each query requires extra CPU resources and can increase latency, especially during periods of high activity. This makes DDM more likely to affect performance in production environments, unlike SDM, which eliminates this concern by completing the masking process upfront.
What are the key security differences between static and dynamic data masking?
Static data masking (SDM) works by permanently substituting sensitive information in a copied dataset with fictitious data. This ensures the original production data stays intact and secure. The main advantage here is that if a masked copy is ever compromised, it only contains fake information, not the real sensitive data. That said, SDM has its limitations - it requires precise masking processes and can quickly become outdated if the source data changes.
Dynamic data masking (DDM) takes a different approach. Instead of altering the data permanently, it applies masking rules in real time whenever someone accesses the data. The original dataset remains untouched, which eliminates the need for creating duplicate datasets. This method offers more flexibility, but it comes with its own challenges. Effective DDM relies heavily on strong access controls to ensure unauthorized users can’t bypass the masking layer.
Both methods come with their own security considerations. Choosing between them depends on an organization’s specific compliance requirements and how much risk they’re willing to accept.
When should an organization use a hybrid approach for data masking?
A hybrid data masking approach is a smart choice when an organization needs to safeguard sensitive information in both non-production environments and live production systems. Here's how it works: static data masking is ideal for creating permanently masked data copies used in testing, development, or analytics. On the other hand, dynamic data masking protects sensitive information in real-time production systems without altering the original database.
If your operations demand both capabilities - like providing realistic test data for developers while masking live data for customer support or other real-time functions - a hybrid approach can seamlessly handle these requirements. This is particularly crucial for organizations bound by regulations such as GDPR, HIPAA, or CCPA, where compliance and security must coexist with usability and system performance.
In short, a hybrid model allows you to address both production security and non-production data needs effectively, using the right masking method for each scenario.