Structured Outputs in Text Generation APIs
Generating structured outputs with AI ensures responses are precise, predictable, and align with specific requirements. Unlike general text generation, structured outputs follow strict JSON Schemas to avoid errors like missing fields or invalid data types. This approach is especially useful for tasks like data extraction, workflows, and application integration. Key advancements include constrained decoding, which enforces schema adherence by limiting token selection, and function calling, which lets AI produce structured arguments for predefined tools. Modern APIs like OpenAI's latest models now achieve 100% schema compliance, reducing costs and improving reliability. However, challenges like platform-specific schema limitations and token truncation remain, which can be mitigated with tools like Pydantic, LangChain, and NanoGPT.
Key Takeaways:
- Structured outputs eliminate parsing errors and ensure schema compliance.
- Constrained decoding and function calling enforce strict adherence to JSON Schemas.
- Tools like Pydantic and LangChain simplify cross-platform compatibility.
- Modern models achieve 100% compliance but require schema simplification for complex cases.
- Savings include reduced token costs (up to 50% input, 33% output) and fewer retries.
This method is shaping AI's role in applications requiring reliable, machine-readable data.
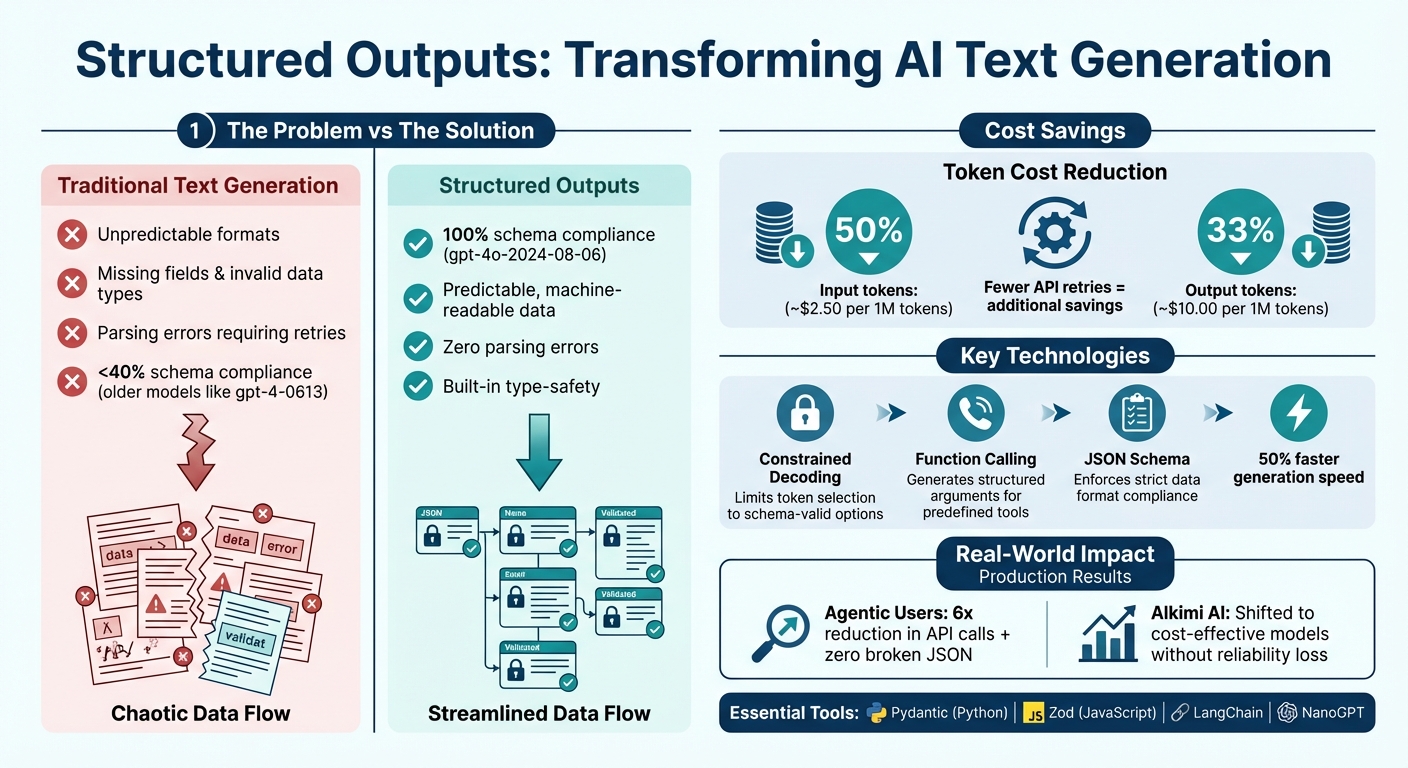
Structured Outputs vs Traditional Text Generation: Key Benefits and Cost Savings
Methods for Generating Structured Outputs
Constrained Decoding and JSON Mode
When models generate text without limitations, they can make errors like omitting keys, using incorrect data types, or including fabricated values. Constrained decoding solves this by intervening during the token selection process, ensuring the model only chooses tokens that align with the provided schema. Tokens violating the schema are effectively removed from consideration, with their probability set to zero.
"By default, when models are sampled to produce outputs, they are entirely unconstrained and can select any token from the vocabulary as the next output. This flexibility is what allows models to make mistakes... In order to force valid outputs, we constrain our models to only tokens that would be valid according to the supplied schema." - OpenAI
This method works by converting your JSON Schema into a context-free grammar (CFG) - a rule-based system that defines valid tokens at each step. As the output grows, the set of acceptable tokens adjusts dynamically. While JSON Mode ensures syntactically correct JSON, it doesn’t enforce a specific schema. In contrast, constrained decoding guarantees strict adherence to the schema.
One added benefit? Constrained decoding can speed up generation by as much as 50%, since unnecessary steps are skipped.
Function Calling and Grammar-Based Approaches
Building on constrained decoding, function calling offers another way to streamline structured output generation.
Function calling allows models to produce structured arguments for predefined tools, essentially acting as a connection between the AI and external systems. By defining a function using a JSON schema and enabling strict mode, the model is required to generate arguments that perfectly match the schema. This eliminates the need for retries or manual corrections.
This method also uses the grammar-based approach behind constrained decoding, where the JSON schema is translated into a CFG. This ensures that valid tokens are dynamically determined at each generation step, supporting even recursive or deeply nested structures.
To optimize function calling:
- Use fewer than 20 functions at a time.
- Provide clear, detailed parameter descriptions.
- Mark all fields as required and set
additionalPropertiesto false for objects. - For optional fields, define a union type that includes null (e.g.,
type: ["string", "null"]).
It's worth noting that structured outputs currently don’t support parallel function calls. To avoid issues, make sure parallel_tool_calls is set to false.
Data Format Compatibility Challenges
Cross-Platform Compatibility Issues
Maintaining consistent structured outputs across text generation APIs can be tricky. While many providers, such as OpenAI, Google, and Groq, rely on JSON Schema, they only support a limited subset of its full specification. This lack of uniformity often complicates transitions between platforms.
For example, OpenAI and Azure OpenAI's Strict mode doesn't support common JSON Schema keywords like minLength, pattern, uniqueItems, or minItems. Azure OpenAI introduces additional constraints, such as a cap of 100 properties per schema and a maximum of five nesting levels. Historically, attempts to use "strongly worded prompts" to enforce structure often fell apart when switching providers. Even with structured outputs, quirks remain - Gemini 2.0, for instance, requires an explicit propertyOrdering list for schemas to work properly.
Preprocessing schemas into a context-free grammar before their first use can also introduce delays. For complex schemas, this step might take up to 60 seconds. Furthermore, while JSON has become the go-to format, alternatives like XML and YAML are still not widely supported natively.
These hurdles highlight the ongoing difficulty of managing platform-specific variations in structured output formats.
Provider-Independent Library Solutions
To address these compatibility issues, provider-agnostic libraries have been developed to simplify structured outputs across platforms. Tools such as Pydantic (for Python) and Zod (for JavaScript) allow developers to define schemas once and convert them into JSON Schema for use with any API. Many SDKs, including those from OpenAI, Gemini, and Ollama, integrate with these libraries to streamline the conversion and deserialization processes.
Libraries like LangChain take it a step further by dynamically choosing between native features or fallback strategies, enabling seamless transitions between providers without requiring significant rewrites of structured output logic. These tools also help mitigate platform-specific constraints. For instance, if you encounter a "schema complexity" error, you can automatically adjust by shortening property names, reducing nesting, or simplifying constraints before sending the schema to the API. By handling these differences behind the scenes, these libraries allow you to define your schema once and use it across multiple platforms - though occasional edge case quirks and varying levels of schema support still require attention.
Benefits and Common Problems with Structured Outputs
Advantages for Users and Developers
Structured outputs are a game-changer for both users and developers, as they ensure responses stick to a defined schema, removing any guesswork. With newer models, the reliability of handling complex JSON schemas has improved significantly. This built-in type-safety means you can bypass complicated validation steps, and the use of a dedicated refusal field makes it easier to handle safety concerns programmatically.
This type-safety becomes especially critical in production settings. Instead of dealing with unstructured text and hoping for consistent formatting, you get predictable outputs that seamlessly integrate into your code. Another powerful feature is the ability to embed chain-of-thought reasoning directly into your schema. By adding fields like "reasoning_steps" or "explanation", the model can break down complex problems step by step before delivering a final answer. This approach boosts accuracy for tasks such as solving math problems or extracting data. On top of that, newer models offer cost savings - input token costs are slashed by 50% (roughly $2.50 per 1M tokens), and output token costs are reduced by 33% (around $10.00 per 1M tokens).
While these benefits are undeniable, structured outputs also come with their own set of challenges that developers need to navigate.
Common Problems and How to Avoid Them
One common issue is token-limit truncation, which can lead to incomplete JSON outputs. This typically results in a finish_reason of length. To avoid application errors, always check this field before parsing the response.
Overly complex or deeply nested schemas can also cause problems, often triggering an InvalidArgument: 400 error. If you encounter this, try simplifying your schema. Strategies include shortening property names, reducing the number of enum values, flattening nested arrays, or minimizing optional properties. Additionally, the first request using a new schema might experience a delay of up to 60 seconds due to schema preprocessing.
Even if the JSON output matches your schema, there’s still the risk of factually incorrect values. To mitigate this, provide clear examples in your system instructions or break down complex tasks into smaller, more manageable subtasks. Always validate the final output within your application to ensure it aligns with your business logic.
sbb-itb-903b5f2
Recent Developments in Structured Outputs
Schema Adherence in Modern APIs
Modern APIs have made impressive strides in adhering to structured output requirements. For instance, OpenAI's gpt-4o-2024-08-06 has achieved a flawless 100% score on complex JSON schema evaluations, a huge leap from older models like gpt-4-0613, which scored under 40% on the same benchmarks. These advancements are largely credited to refined token-selection strategies.
Providers now differentiate between two approaches: Strict Mode and best-effort. In Strict Mode, compliance is ensured by enforcing rules such as setting additionalProperties: false and marking all fields as required. Recent updates also include expanded support for advanced schema features like unions (anyOf), recursive schemas ($ref), numeric constraints (minimum, maximum), and exact key ordering.
These changes aren't just theoretical - they're delivering tangible results in production environments. For example, Lluis Vega, Founder and CEO of Agentic Users, shared that using structured outputs with Pydantic reduced API calls by a factor of six and completely eliminated broken JSON responses in their systems. Similarly, Dillon Uzar from Alkimi AI highlighted that enforcing machine-readable formats allowed his team to shift tasks to more cost-effective models without compromising reliability.
These advancements have also driven the creation of better tools and integration methods, which are outlined in the next section.
New Tools and Techniques
The improvements in schema adherence have paved the way for tools that simplify developer workflows. For example, native SDKs for Pydantic (Python) and Zod (JavaScript) now allow developers to define type-safe schemas that automatically convert to JSON Schema, eliminating the need for manual conversions and reducing errors.
For teams working across multiple providers, frameworks like LangChain have introduced a ProviderStrategy. This feature automatically chooses the best native structured output method for each model - whether it's OpenAI, Anthropic, or Gemini - and defaults to function calling for models lacking native support. Additionally, NanoGPT offers a unified API gateway compatible with OpenAI, enabling developers to interact with multiple providers through a single, standardized interface. NanoGPT also forwards schema-related parameters to upstream providers and includes a stickyProvider feature to maintain consistency, avoiding disruptions to stateful features like prompt caches.
The industry has also adopted new benchmarking tools. The JSONSchemaBench, launched in January 2025, provides a standardized way to evaluate constrained decoding frameworks using 10,000 real-world JSON schemas. This benchmark has become a critical resource for developers, speeding up improvements across the industry and offering a reliable way to assess provider capabilities.
OpenAI Introduces Structured Outputs in the API (Tutorial)
Conclusion
Structured outputs now ensure 100% adherence to schemas, eliminating parsing errors in production systems. By implementing constrained decoding, these systems limit models to generating only valid tokens, doing away with the need for retry logic.
This approach isn't just about technical precision - it translates into real savings. Input costs drop by 50%, output costs by 33%, and fewer API calls mean fewer broken responses. Beyond cost efficiency, this reliability paves the way for smoother integrations across platforms.
With standardized JSON Schema, AI models can seamlessly interact with databases, UI generators, and multi-step workflows - no custom adapters required. NanoGPT takes this a step further by offering a unified API gateway, ensuring consistent schema handling while safeguarding user privacy through local data storage.
The introduction of the refusal field is another game-changer. It clearly separates safety rejections from valid responses, preventing parsing errors. When combined with a temperature setting of 0 and strict mode, outputs become entirely deterministic, delivering predictable and reliable behavior.
Whether you're building enterprise-level applications or personal projects, structured outputs provide the foundation for dependable and efficient AI integration. With guaranteed schema compliance, reduced costs, and privacy-focused features, this technology is shaping up to be a must-have for anyone working with text generation APIs in 2026.
FAQs
How do constrained decoding and function calling ensure structured outputs in text generation?
Constrained decoding and function calling are two effective methods to ensure a language model produces outputs in predefined formats, like JSON or XML, instead of free-form text.
Constrained decoding limits the model to generate only outputs that conform to a given schema. By adjusting token probabilities, it excludes invalid tokens, ensuring the output remains both syntactically correct and aligned with the specified structure.
Function calling takes this concept further. Developers can define the desired output format as a function with a schema. The model is then directed to "call" this function. With strict validation in place, any response that fails to match the schema is rejected. This makes it particularly useful for tasks such as updating databases or integrating tools, where precision is critical.
NanoGPT incorporates both constrained decoding and function calling in its text-generation APIs. This integration allows developers to produce structured, validated data without requiring extra post-processing, simplifying workflows, minimizing errors, and delivering outputs that are ready to use right away.
What are the challenges of using structured outputs across different text generation platforms?
Using structured outputs across different platforms comes with its fair share of challenges. One major issue lies in how APIs handle JSON schema compliance. Some platforms enforce strict validation rules for schema formats, while others perform only basic checks or allow for optional configurations. This inconsistency can cause problems like payloads being unexpectedly rejected or modified.
Another common obstacle involves working with nested or complex structures, such as arrays of objects. Certain APIs may struggle to process deeply nested data, forcing developers to manually simplify these structures. On top of that, the tools and SDKs offered by various platforms can differ widely, often requiring additional effort when transitioning between services.
NanoGPT addresses these challenges by implementing a strict schema enforcement approach. This ensures smoother compatibility and minimizes friction when working across platforms. That said, developers should still test edge cases during integration to maintain reliability and avoid surprises.
How do structured outputs help reduce costs when using text generation APIs?
Structured outputs are a smart way to reduce costs by ensuring API responses follow a set format, like a JSON schema. This consistency removes the need for expensive post-processing, cuts down on errors, and limits the need for retries. The result? A smoother workflow that saves developers both time and money, ultimately lowering operational costs.
Another major advantage is how structured outputs help control token usage, especially in pay-as-you-go pricing models. By avoiding unnecessary token consumption and reducing the need for manual fixes, businesses can make their API usage more efficient and budget-friendly.