How to Test Data Recovery After a Disaster
Your disaster recovery plan is only as effective as your last test. Without regular testing, you risk discovering critical issues - like incomplete backups or outdated recovery steps - during an actual crisis. This can lead to extended downtime, data loss, and compliance violations.
Key Takeaways:
- What is Data Recovery Testing? It simulates disasters to confirm backups are complete, usable, and systems can be restored within your Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
- Why Test? Testing uncovers hidden gaps, verifies RTO/RPO targets, and ensures your team is prepared to act swiftly.
- How to Prepare:
- Inventory IT assets and classify workloads by priority (Tier 1, Tier 2, Tier 3).
- Document backup locations and dependencies.
- Develop realistic disaster scenarios based on risks like ransomware or natural disasters.
- Testing Methods: Choose from checklist reviews, simulations, parallel testing, or full interruption testing based on system priority and risk tolerance.
- Verify Success: Validate data integrity (e.g., checksums), test application functionality, and measure recovery performance metrics like RTO and restore success rates.
- Iterate and Improve: Analyze test results, document failures, and refine your recovery processes.
Quick Action Plan:
- Schedule Regular Tests: Quarterly for critical systems; annually for lower-priority ones.
- Test Different Scenarios: Include ransomware, hardware failure, and network outages.
- Involve the Whole Team: Ensure all stakeholders know their roles during recovery.
- Track Metrics: Monitor RTO, RPO, and restore success rates to identify weaknesses.
Regular testing ensures your disaster recovery plan is reliable and keeps your organization ready for unexpected disruptions.
Disaster Recovery Testing Explained | The Right Way to Test DR
How to Prepare for Data Recovery Testing
Preparation is key to uncovering real vulnerabilities during data recovery tests. Start by pinpointing the assets that need safeguarding, documenting where backups are stored, and crafting scenarios that mirror threats your organization might actually face.
Assess Your Risks
Begin with a full inventory of your IT assets. Categorize workloads based on their importance, and define specific Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) for each one. Tools like network mappers and data discovery software can help track assets and detect changes in real time, so you don’t miss any new additions.
Next, map out critical application dependencies - files, directory services, and systems that must be restored together.
Think about the risks your organization faces: natural disasters, physical damage, tech failures, or cyberattacks. Each type of threat requires a specific testing approach. For instance, natural disaster tests might focus on accessing offsite or cross-region backups, while ransomware scenarios emphasize ensuring backups are isolated and secure.
Create a Backup Inventory
Thorough documentation of your backups is essential. Record all backup locations - whether they’re local, cloud-based, or offsite - as well as the types of data stored and the recovery options available for each asset. To prioritize recovery, classify workloads into tiers: Tier 1 for mission-critical systems, Tier 2 for important but secondary systems, and Tier 3 for non-critical workloads.
Don’t forget the technical details. Your inventory should include service accounts, credentials, and network paths needed to validate restored services. If you rely on cloud-based backups, test cross-account and cross-region restore capabilities to ensure encryption keys (like AWS KMS) and permissions don’t cause issues during recovery. Stick to the 3-2-1 rule: keep at least three copies of your data, use two different storage media, and store one copy offsite.
"Backups that are not regularly tested are essentially useless. Without consistent testing, you run the risk of losing the data, applications, systems, and workloads that your backups contain."
- Tess Hanna, Editor, Solutions Review
Plan Your Test Scenarios
Develop scenarios that mimic real-world disasters. For example, simulate a corrupted or inaccessible primary backup and test your team’s ability to switch to secondary or cloud backups. Include dependencies like power outages, network failures, or ISP disruptions to confirm systems can transition to alternate paths or backup power sources.
Other scenarios might include sudden shifts to remote work or conditions that limit access to physical data centers. Before testing, define clear success metrics - such as verifying data integrity with checksums, confirming file sizes match, or ensuring user permissions stay intact after restoration.
"Often, the only backup recovery pattern that actually works is the path you test frequently."
- AWS Prescriptive Guidance
Lastly, consider starting with tabletop exercises. These are structured discussions where key stakeholders walk through a hypothetical disaster scenario. It’s a great way to clarify responsibilities and identify decision-making gaps before diving into technical tests.
Once these steps are complete, you’ll be ready to perform recovery tests that not only validate your systems but also highlight areas for improvement.
Data Recovery Testing Methods
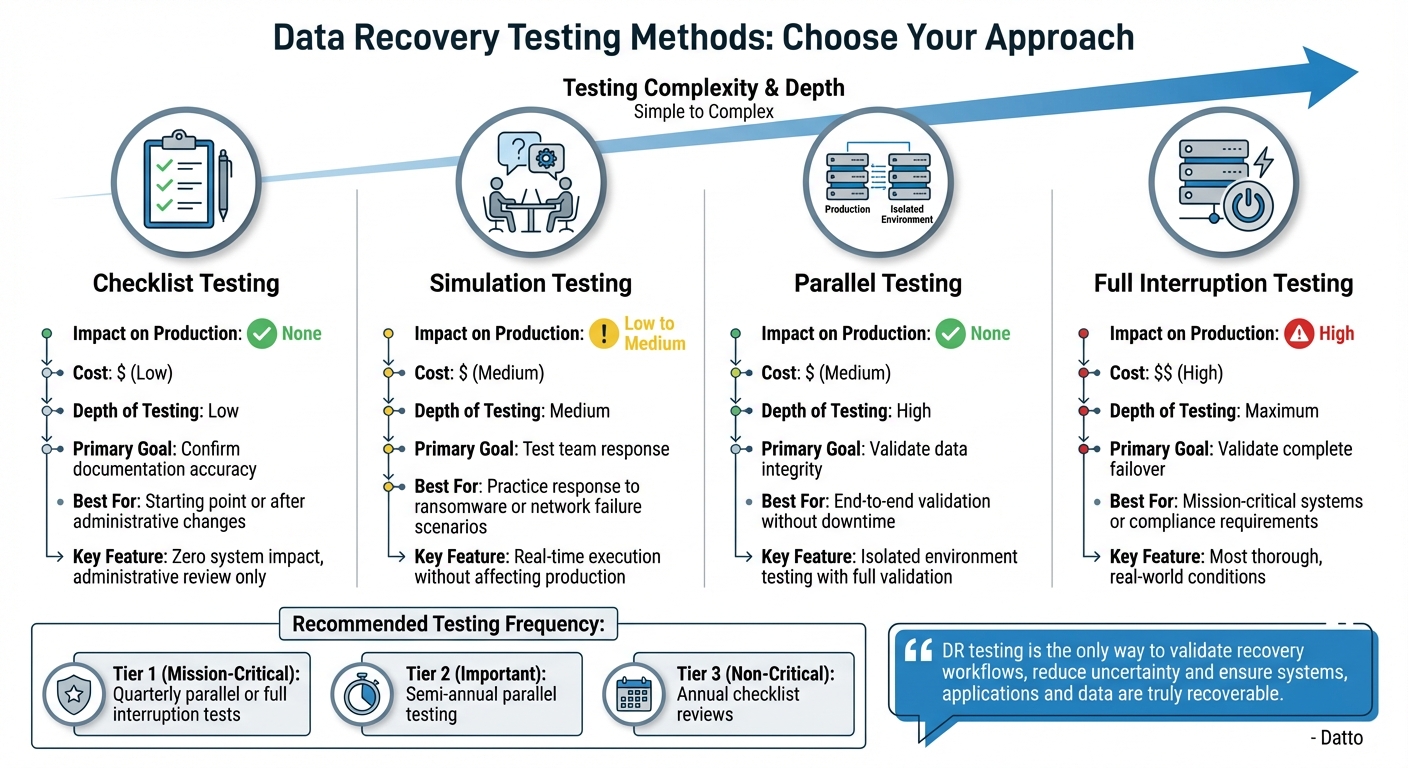
Data Recovery Testing Methods Comparison Guide
When your test scenarios are ready, the next step is picking a testing method that aligns with your organization’s risk tolerance, workload priorities, and compliance requirements. These methods guide you in selecting tests that match your recovery goals and ensure your preparation pays off.
Checklist Testing
Checklist testing is a straightforward, administrative approach to data recovery testing. It involves reviewing your disaster recovery documentation to confirm that all resources, contact details, backup locations, and procedures are up to date. Since this method doesn’t involve technical testing, it has zero impact on your production systems.
This method is an excellent starting point, especially when launching a new disaster recovery program or after changes in infrastructure or team members. While it doesn’t prove that your backups will function, it ensures your team knows where to find crucial information during a crisis.
Simulation and Parallel Testing
Simulation testing brings your recovery plan to life by creating a mock disaster scenario. Your team executes recovery steps in real time, testing their response and identifying any gaps in the process. This method is particularly useful for training staff on their roles without affecting production systems.
Parallel testing goes a step further by restoring critical systems in a separate, isolated environment while production systems remain unaffected. This allows you to verify data accuracy, test application functionality, and measure performance metrics from start to finish. To ensure safety, use separate VLANs or network segments for these tests.
"DR testing is the only way to validate recovery workflows, reduce uncertainty and ensure systems, applications and data are truly recoverable."
Both simulation and parallel testing offer a balance of realism and safety, making them ideal for regular testing of high-priority systems.
Full Interruption Testing
Full interruption testing is the most thorough - and the riskiest - method. It involves shutting down primary systems entirely and switching operations to a recovery site using actual data and equipment. This method tests whether your organization can meet recovery time objectives (RTO) and recovery point objectives (RPO) under real-world conditions.
Because of its high impact, this method is typically reserved for mission-critical systems or compliance-driven scenarios. Organizations often schedule full interruption tests during maintenance windows or after business hours to minimize disruption while ensuring their recovery infrastructure is up to the task.
| Testing Method | Impact on Production | Primary Goal | When to Use |
|---|---|---|---|
| Checklist | None | Confirm documentation | Starting point or after administrative changes |
| Simulation | Low to Medium | Test team response | Practice response to scenarios like ransomware or network failure |
| Parallel | None | Validate data integrity | End-to-end validation without downtime |
| Full Interruption | High | Validate complete failover | Mission-critical systems or compliance requirements |
Selecting the right testing method depends on your system’s priority. For example, Tier 1 (mission-critical) systems might need quarterly parallel or full interruption tests, while Tier 3 (non-critical) workloads may only require annual checklist reviews. Start with lower-risk methods and gradually advance to more realistic scenarios as your team gains confidence and expertise.
sbb-itb-903b5f2
How to Verify Recovery Success
Once you've completed your recovery test steps, the next crucial phase is verification. This ensures that every restored component is fully operational. A successful recovery test must confirm that the restored data is intact, accurate, and ready for production use. Skipping this step could leave you vulnerable to hidden issues that only surface during a real disaster.
Check Data Completeness
Start by comparing the restored data to its original using tools like checksum and hash methods to ensure data integrity. Automating these checks after every backup job can help detect corruption early, preventing it from becoming a larger problem.
But don't stop at file-level validation. Verify that your systems not only boot but also function as expected. Tools like automated screenshot utilities can confirm that backups are bootable. For a more thorough test, restore data in an isolated sandbox environment, such as a separate VLAN or virtual network. This allows you to confirm that key services like Active Directory or SQL Server not only start but can process sample transactions correctly.
"If you don't test your backups for recoverability, you really don't have backups at all."
The 2021 Colonial Pipeline ransomware attack highlights the importance of this step. The company paid a reported $4.4 million ransom after discovering their backups were ineffective during the crisis. On top of that, they faced nearly $1 million in fines for failing to meet cybersecurity and safety standards.
Once you've verified data completeness, it's equally important to evaluate recovery performance.
Track Performance Metrics
Tracking recovery performance helps pinpoint weaknesses and fine-tune your recovery process. Start by measuring your Recovery Time Objective (RTO) - the time it takes to restore and fully validate a system - and compare it to your target. Similarly, check your Recovery Point Objective (RPO) by assessing the age of the recovered data to ensure any data loss is within acceptable limits.
Other key metrics include:
- Restore success rate: The percentage of successful restores out of total attempts.
- Integrity pass rate: The percentage of restores that pass checksum validation.
- Median restore time: The average time required to restore different workload tiers.
Monitoring these metrics over time can help you identify recurring problems, streamline recovery processes, and ensure compliance. Always document test results, including job logs, screenshots, and integrity reports, to support continuous improvement.
Testing Methods Comparison
| Testing Method | Disruption Level | Cost | Depth | Ideal For |
|---|---|---|---|---|
| Checklist/Manual | Low | Low | Low | Verifying documentation and basic accessibility |
| Checksum/Hash | Low | Low | Medium | Detecting file corruption or transfer errors |
| Sandbox/Simulation | Medium | Medium | High | Validating system bootability and application dependencies |
| Full Interruption | High | High | Maximum | Testing entire disaster recovery workflows and team response |
Choose the right testing method based on the priority of your systems and your organization's risk tolerance. For high-priority systems, sandbox or full interruption testing offers deeper validation. Lower-risk systems, on the other hand, might only need periodic checksum checks. Start with less disruptive methods and gradually move to more comprehensive testing as your confidence in the recovery process grows.
Analyze Results and Improve Your Plan
Once you've confirmed recovery success, it's time to dive into the test results and fine-tune your disaster recovery plan. Testing doesn't just validate your plan - it exposes its strengths and weaknesses. Make sure to document every action, timestamp, error message, and conversation in real-time with the help of a dedicated scribe. This should include job logs, screenshots, command-line outputs, and integrity summaries.
Treat any failure as an incident. Perform a root cause analysis to document corrective measures and schedule a retest. Use timestamps from your test to identify gaps in meeting your RTO (Recovery Time Objective) and RPO (Recovery Point Objective) goals. Common issues that surface during testing might include corrupted backups, incomplete datasets, broken permissions, or network bandwidth bottlenecks that slow down recovery.
"A disaster recovery plan that has never been tested is not a plan; it's a theory. It's a very expensive, high-stakes theory that you don't want to be testing for the first time during a real crisis."
- ISO 27001 PRO
Document Results and Identify Weaknesses
Compile a formal disaster recovery test report. This should include an executive summary, test objectives, a detailed timeline of events, and an analysis of both successes and failures. Start small with simple plan reviews and tabletop exercises before moving on to more complex full-interruption tests. This "crawl, walk, run" approach helps you identify documentation gaps early without taking unnecessary risks.
Where possible, automate evidence collection. Use scripts or automation tools to gather checksums, service probe results, and other data, attaching them to recovery tickets for consistent reporting. If a test fails or exceeds RTO targets, notify stakeholders immediately with automated alerts via SMS, email, or Slack to ensure everyone is aware of the risk.
Gather Team Feedback
Once you've documented the technical details, bring your team together to review the findings. Hold a post-mortem review within 24–48 hours of the test while the experience is still fresh. Include IT specialists, management, communication experts, and representatives from affected departments like finance and operations. Structure the discussion around three key questions: What worked? What failed? How can we improve?
Don't just focus on the technical aspects - evaluate how well the team performed. Were the guidelines clear? Did the recovery tools function as expected? How effectively did the team collaborate under pressure? Use these reviews to uncover breakdowns in communication or unclear roles within the response team. Turn every "lesson learned" into actionable updates for your disaster recovery plan, such as fixing outdated contact lists, revising failed scripts, or addressing overlooked system dependencies.
"Don't fear failure in a test; embrace it. Every gap you find, every script that fails, and every outdated phone number you discover is a victory."
- ISO 27001 PRO
Refine Your RTO and RPO Targets
After testing, compare your actual recovery time and data loss against your RTO and RPO targets. If you missed the mark, dig into the root causes. Are outdated systems, misconfigurations, insufficient training, or unclear procedures to blame? Testing often shines a light on these vulnerabilities.
When recovery takes too long, you might need to upgrade hardware, boost network bandwidth, or optimize backup configurations. Streamlining recovery could involve automating manual steps or using application-aware backup tools to cut down on restoration time. If your RPO targets aren't met, consider increasing backup frequency - shifting from daily to hourly backups - or implementing continuous data protection.
If your resources are stretched thin, adjust your RTO and RPO targets to more realistic levels. Align these targets with the criticality of your workloads: mission-critical systems (Tier 1) demand shorter RTOs compared to less essential systems (Tier 3). Present your test data to leadership to either secure additional funding for better tools or gain approval for longer acceptable downtimes. Once you've incorporated feedback and updated the plan, run another test to confirm that the new processes work as expected.
Conclusion
To ensure your disaster recovery plan is effective when it matters most, focus on clear, actionable steps and regular testing. A plan that isn’t tested frequently relies on assumptions - and assumptions can fail in a crisis.
Here’s the reality: around 50% of organizations test their disaster recovery plans only once a year or less, and 7% skip testing altogether. Even more alarming, just 57% of backups are successfully completed in a given year. These numbers highlight why proactive testing is critical. You need to identify and fix failures before they escalate into full-blown disasters.
Key Takeaways
- Preparation is everything. Start by evaluating risks, creating a detailed backup inventory, and planning realistic test scenarios. Incorporate a mix of testing methods like tabletop exercises for communication, parallel testing for technical validation, and full-scale drills for complete readiness.
- Verification is non-negotiable. Ensure your data is complete, test performance against Recovery Time Objective (RTO) and Recovery Point Objective (RPO) targets, and confirm restored data is usable. Tools like checksums, integrity checks, and screenshot verification can automate parts of this process.
- Iterate and improve. After every test, conduct a retrospective to document successes, failures, and areas for improvement. Update your runbooks promptly, refine your procedures, and retest to confirm fixes are effective.
"Your disaster recovery (DR) plan is only as strong as your last test."
- Kari Rivas, Senior Product Marketing Manager, Backblaze
Next Steps
To enhance your disaster recovery readiness, take these steps right away:
- Create a testing schedule. Commit to quarterly tabletop exercises, bi-annual parallel tests, and at least one annual full-scale drill. Adjust the frequency based on your organization’s risk profile and how often your IT environment changes.
- Involve the entire organization. Recovery isn’t just an IT task. Include representatives from legal, finance, and management to ensure everyone knows their role. Test against a variety of scenarios - ransomware attacks, hardware failures, and network outages - to prepare for diverse threats.
- Keep your plan dynamic. Store your disaster recovery plan in a secure, cloud-based system that remains accessible even if your primary infrastructure fails. Update it after every test, infrastructure change, or staffing adjustment. Retest immediately following significant updates to confirm the plan still works. Remember, the goal isn’t perfection right away - it’s building a recovery process that improves with each iteration.
FAQs
How often should I test my disaster recovery plan to ensure it works effectively?
Regular testing of your disaster recovery plan is crucial to make sure it works when it really counts - during an actual emergency. While the exact timing depends on your organization’s needs, a solid approach is to test it at least annually. It’s also smart to run a test after any significant updates to your systems, infrastructure, or business processes.
Testing regularly helps uncover weaknesses, confirm that data recovery processes are reliable, and ensure your team knows exactly how to respond. This proactive approach can reduce downtime and safeguard your critical data when disaster strikes.
What is the difference between simulation testing and full interruption testing in disaster recovery?
The key distinction between simulation testing and full interruption testing lies in their impact and intent.
Simulation testing involves creating a controlled environment where recovery procedures are practiced without disrupting live systems. This method carries minimal risk and allows teams to assess readiness in a safe and manageable setting.
In contrast, full interruption testing involves deliberately shutting down or causing system failures to replicate a real disaster scenario. While this approach is more disruptive, it offers a deeper evaluation of the recovery plan under real-world conditions.
Simulation tests are usually carried out more frequently due to their lower risk, whereas full interruption tests are less common because of their potential to disrupt operations. Both approaches play crucial roles in building a dependable disaster recovery strategy, each addressing different aspects of preparedness and system resilience.
What steps can I take to protect my backups from ransomware?
To safeguard your backups from ransomware attacks, stick to proven strategies like using backup systems designed to resist ransomware and storing your backups offline or in secure, isolated locations. It's also crucial to routinely test your recovery process to ensure that your data can be restored completely and without errors.
Another key step is automating backup validation to confirm that your backups are intact and free from any corruption. Don’t forget to implement encryption and robust access controls to block unauthorized access to your backup systems.