Ultimate Guide to AI Infrastructure Costs
AI infrastructure costs are now one of the biggest expenses for companies working with artificial intelligence. Here's what you need to know:
- GPU compute makes up 40–60% of AI budgets, with costs often wasted on idle resources or inefficient setups.
- In 2025, enterprise AI budgets averaged $85,521 per month, a 36% increase from the previous year.
- Startups often spend 80% of their funding on compute resources, with cloud APIs costing 10–30x more than owning hardware.
- For large-scale usage, self-hosted infrastructure becomes cheaper. For example, an 8-GPU cluster costs $335,000 upfront but reduces long-term costs compared to cloud rentals.
- Cloud computing offers flexibility but can be expensive. Spot instances can save up to 90%, but they come with risks like sudden termination.
- Data storage and networking add significant costs, especially for large datasets and cross-region transfers.
Quick Takeaways:
- Hardware: GPUs like NVIDIA H100 cost $30,000–$40,000 each, with clusters exceeding $350,000.
- Cloud vs. Self-Hosted: APIs are better for low-volume or unpredictable workloads, while self-hosting saves money for high-volume tasks.
- Cost-Saving Tips: Use spot instances, pre-trained models, and efficient data pipelines to cut expenses.
AI costs can spiral quickly without careful planning. Whether you’re a startup or an enterprise, understanding these expenses helps you make smarter decisions.
Open vs. Closed Source: The Ultimate ROI Analysis | The 2026 Guide to LLM Infrastructure Costs
sbb-itb-903b5f2
AI Infrastructure Cost Components
Breaking down the cost of AI infrastructure reveals three main areas that influence your overall spending. Each category comes with its own pricing structure and opportunities to manage expenses effectively.
Hardware Expenses
Hardware is one of the largest cost drivers in AI infrastructure, with GPUs leading the charge. For example, an NVIDIA H100 GPU now costs around $40,000, a significant jump from $25,000 in 2022. Building an 8-GPU on-premises cluster, complete with components like chassis, CPU, RAM, and storage, can set you back between $350,000 and $400,000. Notably, 40% of a GPU's cost is tied to high-bandwidth memory.
Networking infrastructure adds another layer of expense, especially for distributed training setups. A 128-GPU cluster using InfiniBand fabric costs roughly $800,000. Power consumption is another key factor. Each H100 GPU uses up to 700 watts, and cooling requirements can add 40% to 70% to the direct power costs.
The economics of hardware ownership improve with higher utilization rates. If GPU usage exceeds 33%, on-premises hardware often delivers better value than cloud-based rentals. For instance, a 16-GPU setup with 65% utilization costs about $2.72 per GPU-hour on-premises, compared to $2.99 per GPU-hour on specialized cloud platforms. These figures highlight how critical it is to optimize utilization to get the most out of your investment.
Cloud Computing and Processing Costs
Cloud compute costs vary depending on the pricing model. On-demand pricing is straightforward - you pay by the hour or second. For NVIDIA H100 instances, this means $6.88 per hour on major cloud providers or $2.99 per hour with specialized vendors. For consistent workloads, commitment-based plans can slash costs by up to 72% with 1-year or 3-year contracts.
For those willing to take on some risk, spot instances offer discounts of 60% to 90% compared to on-demand rates. However, these come with the possibility of termination on short notice (as little as 2 minutes), making them ideal for fault-tolerant tasks like parameter tuning but less suitable for production inference. To minimize losses, automated checkpointing every hour is a smart move.
While the H100 GPU costs 2.3 times more per hour than the A100, its ability to complete training workloads 3 times faster results in a 23% overall cost saving for pre-training projects. Additionally, per-second billing with a 60-second minimum ensures you don't pay for unused time.
Data Storage and Network Costs
Storage and networking are other critical components of AI infrastructure costs. Storage expenses stem from training datasets (which can reach petabyte levels), model artifacts (like weights and logs), and inference data for compliance purposes. Standard cloud storage services, such as AWS S3 or Google Cloud Storage, charge between $0.02 and $0.023 per GB per month. To save, you can use automated lifecycle policies to move less frequently accessed data to cheaper cold storage tiers.
Networking costs can also add up quickly. Data egress fees range from $0.08 to $0.12 per GB, while cross-region transfers typically cost around $0.01 per GB. Distributed training generates significant east-west traffic between servers for gradient synchronization, which can be expensive without high-performance interconnects.
AWS offers 100 GB of free data transfer out each month, with tiered pricing that lowers costs as usage exceeds 10 TB, 40 TB, and 100 TB. Keeping datasets within a single region, unless multi-region redundancy is necessary, is one way to avoid extra cross-region fees.
API Services vs. Self-Hosted Infrastructure
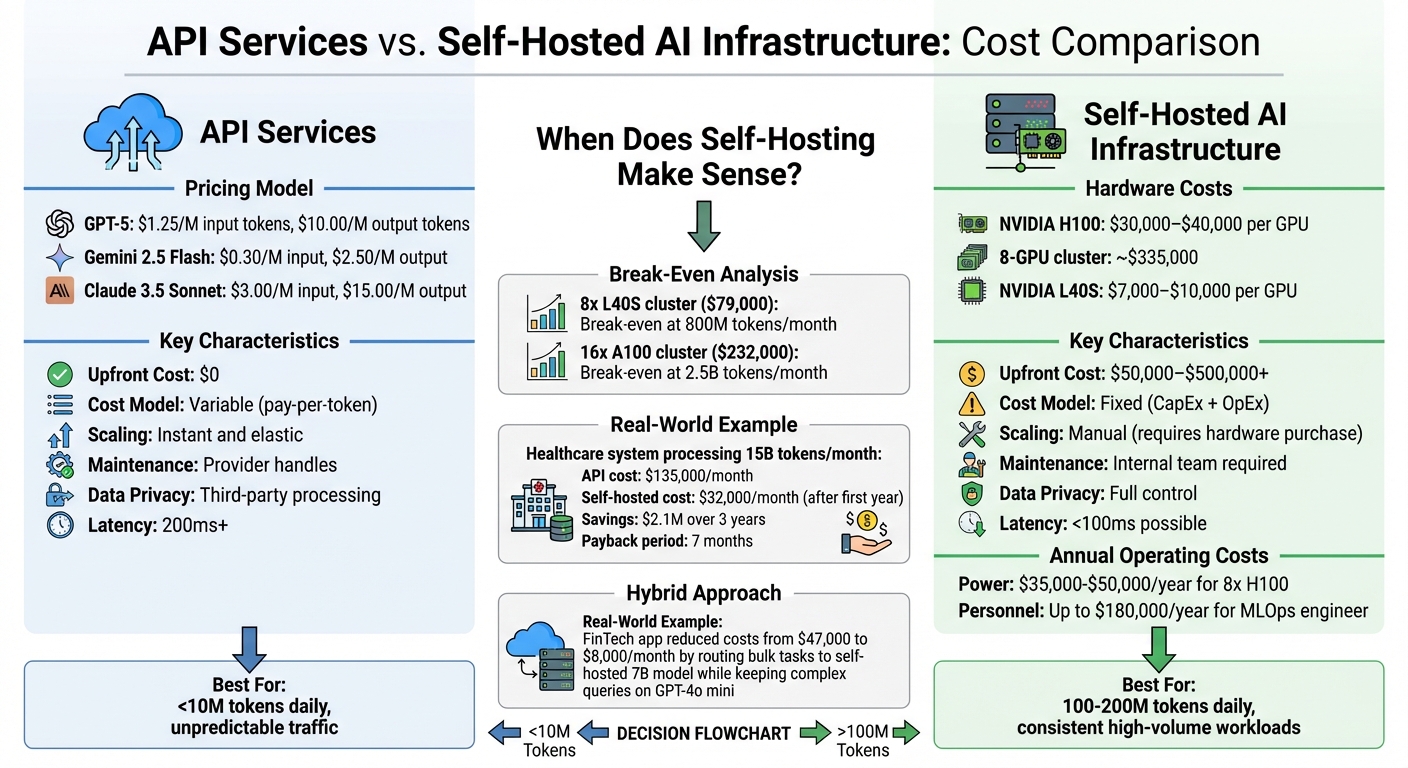
API Services vs Self-Hosted AI Infrastructure Cost Comparison
When deciding between API services and self-hosted setups, it’s all about weighing volume, control, and cost management. APIs operate on a pay-per-token model, while self-hosting requires a hefty upfront investment in hardware but offers fixed costs regardless of usage.
Here’s how the numbers stack up.
API Service Pricing
API services charge based on the number of tokens processed. Interestingly, output tokens are priced 3–4 times higher than input tokens. For example, as of early 2026:
- GPT-5: $1.25 per million input tokens and $10.00 per million output tokens
- Gemini 2.5 Flash: $0.30 for input and $2.50 for output
- Claude 3.5 Sonnet: Premium pricing of $3.00 for input and $15.00 for output
These services are ideal for organizations processing under 10 million tokens daily or experiencing unpredictable traffic patterns. With APIs, there’s no upfront cost, scaling is instantaneous during traffic surges, and the provider handles maintenance, security, and updates. However, costs scale directly with usage - double the token volume, and your bill doubles too.
Now, let’s flip the script with self-hosted setups.
Self-Hosted Setup Costs
Self-hosting shifts the cost structure entirely. The upfront investment is significant. For instance:
- NVIDIA H100 GPUs: $30,000 to $40,000 per unit
- 8-GPU cluster: Around $335,000, including networking and chassis
- NVIDIA L40S GPUs: $7,000 to $10,000, a more budget-friendly option for inference workloads
Beyond hardware, operational expenses add another layer. Annual costs for power, cooling, and maintenance contracts typically range from 20–35% of hardware costs. For example, an 8x H100 server consumes over 3kW of power, translating to $35,000–$50,000 annually in electricity. Then there’s the human factor - dedicated MLOps engineers can cost up to $180,000 per year.
"Personnel cost is the most underestimated factor in self-hosting AI." - Prashant Dudami, AI/ML Architect
Cost Comparison: API vs. Self-Hosted
The choice between API services and self-hosting often hinges on your token volume. For example:
- An 8x L40S cluster ($79,000) breaks even at around 800 million tokens per month.
- A 16x A100 cluster ($232,000) needs roughly 2.5 billion tokens monthly to justify the investment.
Self-hosting becomes a cost-effective option when processing 100–200 million tokens daily. A real-world example? In May 2025, a large healthcare system handling 15 billion tokens monthly switched from HIPAA-compliant cloud APIs to an on-premise cluster with 24x NVIDIA A100 GPUs. Their initial investment of $420,000 (hardware and infrastructure) and annual operating costs of $380,000 slashed their monthly equivalent cost from $135,000 to $32,000 after the first year. This resulted in $2.1 million in savings over three years with a payback period of just seven months.
| Factor | API Services | Self-Hosted Infrastructure |
|---|---|---|
| Upfront Cost | Zero | $50,000 - $500,000+ |
| Cost Model | Variable (pay-per-token) | Fixed (CapEx + OpEx) |
| Scaling | Instant and elastic | Manual (requires hardware purchase) |
| Maintenance | Handled by provider | Internal team required |
| Data Privacy | Third-party processing | Full control and sovereignty |
| Latency | Network dependent (200ms+) | Ultra-low (<100ms possible) |
Interestingly, many organizations adopt a hybrid approach. For instance, in August 2025, a FinTech trading app managing 600,000 daily messages reduced its AI costs from $47,000 to $8,000 per month. They achieved this by routing bulk tasks to a self-hosted 7B model on spot H100 instances while keeping complex queries on GPT-4o mini. The transition took just 10 days and paid off in a little over four months.
How to Reduce AI Infrastructure Costs
Even the best setups can become costly, but smart adjustments can help maintain performance while trimming expenses. Strategies like refining compute usage, choosing the right models, and streamlining data flow can make a big difference.
Using Spot Instances and Reserved Pricing
Spot instances can slash costs by up to 90% compared to on-demand pricing. These are ideal for tasks that can handle interruptions, like batch processing, model training, or data preprocessing. However, cloud providers can reclaim these instances with just a two-minute warning, so it's essential to checkpoint progress every 15–30 minutes.
For workloads that run continuously, reserved pricing offers savings of 50–72% on a 1- or 3-year commitment. Tools like SageMaker AI Savings Plans can further reduce expenses by up to 64%. Many organizations combine these approaches - using reserved pricing for their baseline needs and spot instances to handle traffic spikes. Configuring workloads to support multiple instance types helps adapt to fluctuating spot prices.
"With over 60% of all cloud costs attributable to compute, focusing on compute infrastructure spend should be of the utmost priority."
- Li-Or Amir, Spot.io
Another way to cut costs is by leveraging pre-trained models.
Working with Pre-Trained and Open-Source Models
Building custom models from scratch can be expensive, with significant data and GPU costs. Pre-trained and open-source models, however, eliminate many of these upfront expenses. Open-source large language models (LLMs) can handle around 80% of proprietary model use cases at a fraction of the cost - 86% lower, to be exact. In fact, 60% of decision-makers have reported reduced implementation costs when using these models.
For example, AT&T switched from a GPT-4 workflow to a multi-model setup to classify 40 million calls annually across 80+ categories. By routing simpler tasks to smaller models, they reduced processing time from 15 hours to under 5 hours and cut costs to 35% of the GPT-4 workflow, all while maintaining 91% accuracy.
If domain-specific customization is necessary, parameter-efficient fine-tuning methods like LoRA or QLoRA are excellent options. These techniques cost between $200 and $2,000, compared to over $10,000 for full fine-tuning. A mid-sized financial services firm, for instance, transitioned from GPT-4 to a self-hosted Llama 3.3 70B model running on four NVIDIA A100-80GB GPUs. This move reduced their monthly costs by 73% (from $45,000 to $12,000) and improved response times by 51%, achieving a payback period of just 4.5 months.
"Open source, the power is in the control. It's like you're guaranteed to run this exact model with this exact set of training data with this exact outcome."
- Matt Colyer, Director of Product Management for Sidekick, Shopify
Efficient data handling is another key area where costs can be reduced.
Building Efficient Data Pipelines
Poorly designed data pipelines can waste up to 40% of GPU cycles. By co-locating data and compute resources, you can avoid costly egress fees, which range from $0.08 to $0.12 per GB, and eliminate cross-region transfer charges.
Using tiered storage is another way to save. Automatically moving older datasets and logs to cold storage can cut storage costs by 50–80%. For instance, AWS S3 Intelligent-Tiering shifts data to cheaper storage tiers based on usage patterns.
Additionally, setting auto-stop policies on notebooks - such as those in SageMaker or Vertex AI - can prevent unnecessary expenses. Shutting down idle notebooks after two hours of inactivity can save $200–$500 per month per instance. Choosing the right hardware for the task is also crucial. For lighter tasks, using an NVIDIA T4 instead of an H100 can prevent wasting up to 32% of cloud spend.
"Deploying a language model on an H100 when a T4 would suffice is like renting a stadium to host a poker night."
- Senior Machine Learning Engineer
Finally, select an inference strategy that matches your traffic needs. Serverless inference is great for sporadic traffic, while batch inference works well for processing large datasets offline.
Pay-As-You-Go Pricing for AI Access
For teams that only need AI occasionally, pay-as-you-go pricing is a game-changer. It eliminates the need for fixed monthly fees or hefty upfront investments. Instead of committing to a subscription (which can range from $20 to $200 per month) or spending $300,000–$500,000 on an on-premise GPU cluster, you simply pay based on usage - measured in tokens. NanoGPT demonstrates this approach with its straightforward token-based pricing model.
How NanoGPT Works
NanoGPT provides access to multiple AI models - like ChatGPT, Gemini, Claude, and DeepSeek - all through one platform, eliminating the hassle of juggling subscriptions. Costs are calculated using input tokens (your prompts) and output tokens (the AI's responses), with roughly 3 words equaling 4 tokens.
Here’s a breakdown of NanoGPT’s token-based pricing:
- ChatGPT 4o: $5.00 per 1 million input tokens and $14.99 per 1 million output tokens.
- DeepSeek R1: $0.40 per 1 million input tokens and $1.70 per 1 million output tokens.
You can also switch between models effortlessly, tailoring your choice to the complexity of your tasks. Plus, there are no minimum fees per query or hidden charges for deposits, making it perfect for occasional users or those running experiments.
Privacy and Cost Savings
NanoGPT doesn’t just offer competitive pricing - it also prioritizes privacy and reduces costs by storing data directly on your device. This local storage approach eliminates cloud-related expenses, like data transfer fees. For added security, NanoGPT includes TEE (Trusted Execution Environment) model variants, which safeguard data during processing by isolating it within a secure section of the main processor.
This setup combines the flexibility of pay-as-you-go pricing with enhanced data protection - without the hefty costs of maintaining on-premise infrastructure. By avoiding the need for specialized MLOps staff, which can cost $75,000–$300,000 annually, NanoGPT offers a practical and efficient alternative.
Conclusion
Main Points
Managing the costs of AI infrastructure is all about making smarter, more efficient choices. Techniques like quantization and optimizing GPU usage can lead to significant savings. It's worth noting that inference now makes up 65% of AI compute spending, which means streamlining model deployment in production environments is more important than ever.
Real-world examples highlight how these strategies work. For instance, Spotify slashed its daily transcription costs by 75%, dropping from $18,000 to $4,500, by using INT8 quantization and continuous batching. Similarly, Roblox managed to cut its costs by 90% while handling 100 billion tokens daily by adopting 2-bit quantization and speculative decoding. These success stories show how focusing on efficiency can deliver better results than simply relying on raw computational power.
These lessons provide a clear path toward actionable strategies for managing AI costs.
Action Steps for Cost Management
To apply these cost-saving strategies, consider the following steps to optimize your AI infrastructure spending:
- Audit your current setup: Identify and eliminate idle resources that could be consuming up to 32% of your cloud budget.
- Implement real-time cost monitoring: Use anomaly alerts to prevent runaway expenses.
- Leverage spot instances for training workloads: These can offer discounts of 60–90%. Pair them with periodic checkpointing to manage interruptions effectively.
For workloads that vary or occur occasionally, consider pay-as-you-go pricing. NanoGPT's token-based model, combined with local data storage, is a great example of how this approach can eliminate unnecessary fixed fees and avoid upfront infrastructure costs that could exceed $2 million.
Finally, define your performance needs before allocating resources. Tony Rigoni from Ampere Computing puts it well:
The focus is shifting from building the biggest models to running them efficiently.
Over-provisioning for tasks like human-speed interactions can dramatically increase costs without providing meaningful benefits. Instead, align your infrastructure with actual performance demands to avoid unnecessary expenses.
FAQs
What should I consider when deciding between cloud-based and self-hosted AI infrastructure?
When deciding between cloud-based and self-hosted AI infrastructure, several factors come into play.
First, let's talk about cost. Cloud-based solutions usually have lower upfront expenses, thanks to their pay-as-you-go pricing model. This makes them a smart choice for smaller projects or workloads that fluctuate. On the other hand, self-hosted options demand a hefty initial investment in hardware but can bring down costs per inference when operating at scale.
Next, consider control and scalability. With cloud providers, updates, scaling, and security are handled for you, which cuts down on operational headaches. However, this convenience might come at the expense of customization and data privacy. If you go the self-hosted route, you'll have greater control over your system's security and compliance, but you'll also need dedicated resources to manage maintenance and scaling.
Finally, think about your usage patterns. If your traffic is unpredictable or comes in bursts, cloud solutions are better equipped to handle that variability. Meanwhile, self-hosted setups shine when dealing with steady, high-volume workloads, offering greater cost efficiency over time.
Choosing the right option boils down to evaluating your budget, operational capabilities, and long-term goals for your AI deployment.
What are the best ways for startups to manage AI infrastructure costs while scaling?
Startups can keep AI infrastructure costs under control by adopting smart strategies that balance performance with expenses. For instance, using smaller or fine-tuned models for simpler tasks can cut costs without sacrificing efficiency. Another effective tactic is caching frequently used queries, which helps lower API usage as your operations expand.
A hybrid cloud setup is another cost-saving option. By combining on-premises infrastructure with cloud resources, you can shift workloads based on what’s most cost-effective. This flexibility becomes especially useful as cloud expenses tend to increase with scale. On top of that, using cost-management tools and adopting FinOps practices - such as tracking usage, setting budgets, and automating resource scaling - can help you maintain tighter financial control.
By prioritizing efficient resource use, exploring affordable infrastructure options, and actively monitoring expenses, startups can grow their AI capabilities without breaking the bank or stifling innovation.
How can I lower data storage and networking costs in AI projects?
Reducing data storage and networking costs in AI projects requires some smart planning and practical strategies. One effective approach is to streamline data management. Techniques like tiered storage - where data is stored in different tiers based on usage - and data deduplication - removing redundant copies of data - can help you store only what’s necessary. This cuts down on wasted storage and keeps costs in check.
When it comes to networking, high data transfer fees can quickly add up. You can save money by minimizing how often data is moved between regions or cloud environments. Leveraging cloud features like auto-scaling, spot instances, and resource sharing can also help. These tools ensure you’re not paying for idle resources or over-provisioning beyond what you actually need.
Another way to save is through model optimization techniques. Methods like pruning (removing unnecessary parts of a model) and quantization (reducing the precision of model weights) can shrink the storage and compute needs of your AI models. These adjustments let you maintain strong performance while significantly lowering costs in your AI workflows.