Ultimate Guide to Multi-Cloud AI Consistency
Ensuring AI behaves the same across multiple cloud providers is critical for reliable results, cost control, and maintaining user trust. The challenge? AI models often show variations in performance, accuracy, and resource usage due to differences in hardware and configurations across platforms like AWS, Azure, and Google Cloud. This guide breaks down how to address these issues effectively.
Key Takeaways:
- Why It Matters: Nearly 30% of AI deployments fail strict consistency checks, leading to unpredictable outputs and costs.
- Metrics to Track: Focus on latency, accuracy drift, and resource usage to identify inconsistencies early.
- Solutions:
- Use Kubernetes for uniform deployments across clouds.
- Implement Infrastructure as Code (IaC) to standardize configurations.
- Monitor with tools like Prometheus and detect anomalies using AI-driven solutions like Vertex AI Model Monitoring.
- Cost-Saving Tips: Spot instances and optimized scaling can cut expenses by up to 90%.
- Testing Tools: NanoGPT offers a simple, privacy-friendly way to compare outputs across AI models.
AI Explained: Understanding Multicloud GenAI Workloads
sbb-itb-903b5f2
Metrics for Measuring AI Model Consistency
Keeping tabs on the right metrics is crucial when deploying AI models across multiple clouds. It’s the difference between catching issues early or finding out only after users start complaining. Key metrics like latency, accuracy, and resource usage provide clear indicators for evaluating how consistent your models are across environments.
Performance and Latency Measurements
Latency metrics help you understand how reliably your models respond across different cloud setups. For real-time applications, it’s not just about overall response time. Specific measurements like Time to First Token (TTFT), which tracks how quickly users see the initial response, are critical. For larger models like Llama 2 70B, the industry standard is around 2,000 milliseconds. Then there’s Time Per Output Token (TPOT), which measures the speed of generating subsequent tokens, with 200 milliseconds often being the benchmark. Additionally, Time Between Tokens (TBT) indicates the rhythm of text generation, directly influencing user experience.
Pay close attention to tail latency metrics like P90, P95, and P99. These show the slowest-performing scenarios, which are more telling than averages, especially with variable cloud resources. For example, in 2025, Microsoft Office 365 researchers Shashwat Jaiswal and Kunal Jain managed over 10 million daily LLM requests across Azure regions. By using forecast-aware auto-scaling and optimized routing, they cut GPU-hour usage by 25% and reduced resource waste by 80%, potentially saving up to $2.5 million per month while meeting latency goals.
Accuracy and Drift Detection
Fast responses are meaningless if the results aren’t accurate. Accuracy drift - where model performance degrades over time - can differ across cloud environments. Data Drift happens when the input data changes, such as when AWS deployments receive different user queries compared to Google Cloud. Concept Drift is trickier, involving subtle shifts in the relationship between inputs and outputs, even if the inputs appear unchanged.
Early detection is key, and statistical tests can help. The Population Stability Index (PSI) compares current production data to baseline training data, with alerts often triggered at a distance score of 0.3. For continuous distributions, the Kolmogorov-Smirnov test is effective, while Jensen-Shannon divergence measures probability distribution similarities across clouds. When testing models across diverse backends - like CPUs, GPUs, and compiled runtimes - only 72.0% of runs pass strict verification tests, meaning nearly 30% of deployments risk inconsistency without proper oversight.
"Model drift is not a technology problem; it is a change in the context of data that can be effectively managed by implementing effective analysis of the data they are trained on." - James Croft, Microsoft
Resource Usage and Scalability
Accuracy metrics show how well your model performs, but resource usage metrics ensure it scales efficiently. These metrics tie directly into cost management and operational predictability. For example, tracking GPU and TPU utilization can prevent scenarios where hardware sits idle in one cloud while being overworked in another. Metrics like Queries Per Second (QPS) and token throughput reveal whether different cloud deployments can handle similar workloads effectively.
Hardware differences between providers can also cause inconsistencies. For instance, newer platforms from Mac and Huawei support 17% fewer operators than NVIDIA, and heterogeneous accelerators can produce output discrepancies exceeding 5% due to operational variations.
To get the full picture, monitor these metrics together rather than in isolation. A model might perform well on one cloud but require twice the resources to do so. Centralized dashboards that aggregate data from all providers can help you identify patterns and anomalies quickly. Automated alerts can flag when metrics exceed acceptable thresholds, but before jumping to retrain your model, verify whether the issue stems from data quality problems in your ingestion pipeline.
Standardization with Kubernetes and Infrastructure as Code
Multi-Cloud AI Consistency Checklist: Essential Components and Tools
After identifying the key metrics for your AI deployments, the next challenge is ensuring consistent behavior across platforms like AWS, Azure, and Google Cloud. This is where Kubernetes and Infrastructure as Code (IaC) come into play, offering a reliable foundation no matter which provider you're using.
Deploying with Kubernetes
Kubernetes provides a unified API and workflow across all major cloud providers. Instead of juggling multiple deployment systems, your team can rely on a single set of configurations that work everywhere. By using containerization, model runtimes are isolated from hardware differences, ensuring that an inference service operates the same way on an AWS GPU node as it does on a Google Cloud TPU.
With multi-cloud strategies becoming a common approach to avoid vendor lock-in, tools like Karmada allow centralized management across clusters. This means you can run training workloads on GPU-rich clusters while placing inference tasks closer to users, optimizing for resource availability and cost. To enhance this further, the CNCF Kubernetes AI Conformance Program, launched in 2026, ensures that AI applications developed on one conformant platform will function seamlessly on others, minimizing unexpected issues.
"Kubernetes has emerged as the de facto standardization layer for workload portability, providing consistent APIs and abstractions across different cloud environments." - AI Wiki Team
For managing GPUs, the NVIDIA GPU Operator simplifies the process by automatically installing drivers and making GPUs schedulable across various cloud providers. This eliminates the need for manual configurations that often lead to inconsistencies. Additionally, service mesh tools like Istio or Consul enable secure communication between services hosted on different clouds. For instance, a prediction service in Azure can securely access a feature store in AWS.
This standardized deployment approach ensures that infrastructure across clouds is consistent and repeatable.
Infrastructure as Code for Consistency
Infrastructure as Code (IaC) addresses hardware and configuration inconsistencies by offering a consistent blueprint for cloud deployments. Tools like Terraform let you define your infrastructure in code, ensuring identical deployments across clouds using the same configuration. This keeps development, staging, and production environments aligned, with only environment-specific variables needing adjustment.
IaC’s modular design is especially useful for AI workflows. With Terraform modules, you can encapsulate best practices for AI components - like model registries or feature stores - and reuse them across platforms like AWS, Azure, and Google Cloud. These modules handle cloud-specific details (e.g., S3 vs. Azure Blob Storage) while presenting a uniform interface to your team, cutting down on errors and speeding up deployments.
Cloud-native tools like Crossplane enhance this further by using Kubernetes controllers to continuously reconcile infrastructure states. By combining modular deployments with GitOps workflows through tools like ArgoCD or FluxCD, you can treat infrastructure and AI configurations as a single source of truth stored in Git. This ensures that production environments remain synchronized.
"The most important step toward a scalable ML serving architecture is to treat the model artifact as a first-class citizen, with its own lifecycle, independent of the application code." - Karl Weinmeister, Director, Developer Relations, Google Cloud
For faster startups, you can mount model storage buckets into Kubernetes pods using the Cloud Storage FUSE CSI driver. Additionally, Hyperdisk ML supports READ_ONLY_MANY access, enabling a single volume to connect to up to 2,500 GKE nodes simultaneously for high-throughput inference.
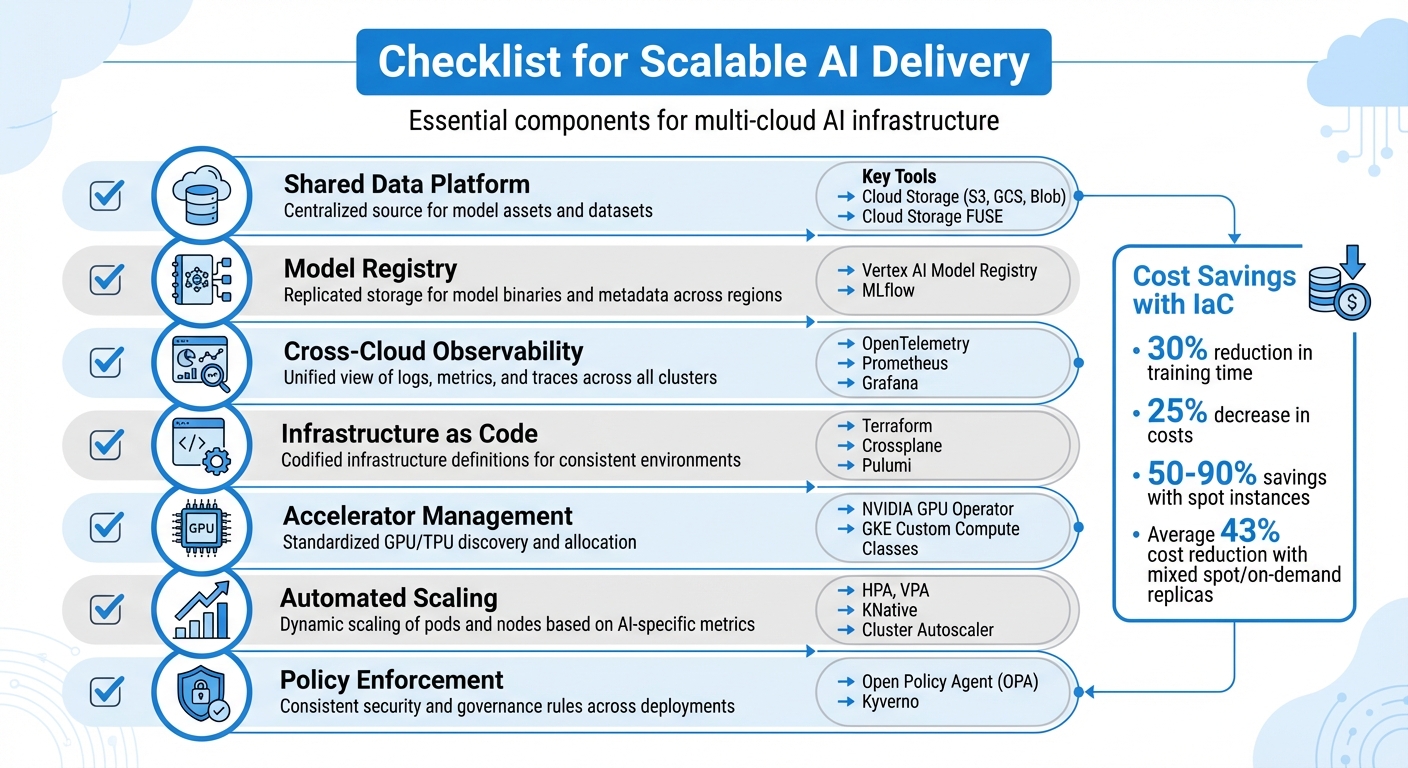
Checklist for Scalable AI Delivery
To ensure your multi-cloud AI infrastructure scales effectively, make sure these core components are in place:
| Component | Description | Key Tools/Technologies |
|---|---|---|
| Shared Data Platform | Centralized source for model assets and datasets. | Cloud Storage (S3, GCS, Blob), Cloud Storage FUSE |
| Model Registry | Replicated storage for model binaries and metadata across regions. | Vertex AI Model Registry, MLflow |
| Cross-Cloud Observability | Unified view of logs, metrics, and traces across all clusters. | OpenTelemetry, Prometheus, Grafana |
| Infrastructure as Code | Codified infrastructure definitions for consistent environments. | Terraform, Crossplane, Pulumi |
| Accelerator Management | Standardized GPU/TPU discovery and allocation. | NVIDIA GPU Operator, GKE Custom Compute Classes |
| Automated Scaling | Dynamic scaling of pods and nodes based on AI-specific metrics. | HPA, VPA, KNative, Cluster Autoscaler |
| Policy Enforcement | Consistent security and governance rules across deployments. | Open Policy Agent (OPA), Kyverno |
Using IaC for AI training environments can lead to a 30% reduction in training time and a 25% decrease in costs. Leveraging spot instances and preemptible VMs can cut expenses by 50% to 90% compared to on-demand pricing. Research on systems like SkyServe demonstrates that serving models through a mix of spot and on-demand replicas reduces costs by an average of 43%.
Policy Enforcement and Governance
Once your infrastructure is standardized, the next challenge is ensuring consistent security, compliance, and access controls across all cloud platforms. Disconnected policies often lead to security vulnerabilities and compliance issues.
Setting Policies for Multi-Cloud Environments
Each cloud provider has its own approach to identity and access management, which complicates centralized control. For instance, AWS relies on IAM Roles, Azure uses Managed Identities, and Google Cloud employs Service Accounts. This fragmentation leads to "governance debt", a problem faced by 92% of large enterprises running multi-cloud governance programs.
A practical solution is to adopt a centralized Identity Provider like Okta or Azure AD, federated across all cloud environments. This setup allows users to authenticate once and receive temporary credentials, avoiding reliance on long-term keys. For access control, establish clear guidelines - such as requiring all databases to be encrypted - and implement a universal policy engine like Open Policy Agent (OPA) to translate these rules into cloud-specific configurations.
"Policy-as-Code (PaC) is the cornerstone of effective multi-cloud governance." - policyascode.dev
Standardizing compliance across providers involves aligning controls with various native services. For example, achieving SOC 2 compliance requires coordinating tools like AWS Security Hub, Azure Policy, and Google Security Command Center. A Cloud Center of Excellence (CCoE) can oversee this framework, ensuring uniformity. Multi-cloud environments typically contain an average of 351 exploitable attack paths due to their complexity. Moreover, fragmented policies contribute to 32% of wasted cloud spending.
This unified approach sets the stage for comparing access control systems across providers.
Comparing Policy Systems
Managing access control across multiple clouds requires understanding their key features:
| Feature | AWS IAM | Azure RBAC |
|---|---|---|
| Primary Logic | User/Group/Role-based with JSON policies | Role-based access assigned at specific scopes |
| Multi-Cloud Compatibility | Native to AWS; federation needed for external use | Extended to other clouds/on-prem via Azure Arc |
| Consistency Challenges | Account-level silos; complex policy evaluation logic | Subscription-based hierarchy; rigid role definitions |
| Mitigation Strategies | Use Service Control Policies (SCPs) in AWS Organizations | Use Azure Policy and Management Groups for inheritance |
Instead of creating provider-specific rules for each platform, policy abstraction can simplify management. For example, define a single "storage" policy that applies uniformly to AWS S3, Azure Blobs, and Google Cloud Storage buckets using OPA's Rego language. This approach minimizes errors and ensures consistent security standards for AI model storage, no matter the deployment location.
These comparisons highlight the importance of abstraction for managing policies across providers.
Automating Policy Enforcement
Given the complexity of policy systems, automating compliance is essential for scalability.
Manual policy checks are impractical in multi-cloud setups. Automation tools can identify violations before they reach production. For instance, integrating GitHub Actions with Conftest enables teams to validate Infrastructure as Code definitions against OPA policies during the build process.
Continuous drift detection is another key strategy. This process identifies manual changes in cloud consoles that could violate compliance, addressing risks that were previously mitigated by Infrastructure-as-Code definitions.
Cloud Infrastructure Entitlement Management (CIEM) tools further streamline policy enforcement. These tools apply the principle of least privilege by analyzing usage data and adjusting permissions accordingly. Start with zero permissions for new roles and grant access only as needed based on observed behavior. Pair this with a universal tagging strategy - like mandatory "owner" and "cost-center" tags - to simplify cost allocation and resource ownership across cloud platforms.
Tools and Techniques for Multi-Cloud Consistency
Centralized Monitoring and Observability
Keeping track of AI model performance across multiple cloud environments requires a unified approach to monitoring. One standout tool is OpenTelemetry (OTel), which has become a go-to standard for collecting logs, metrics, and traces into a single system using the OpenTelemetry Protocol (OTLP).
"Across the observability vendor landscape, OpenTelemetry (OTel) has become the de-facto standard." – AWS Observability Best Practices
What makes OTel so effective is its adaptability. It allows organizations to switch observability platforms without the hassle of re-instrumenting their applications, offering what experts call "two-way doors". Another tool, BindPlane by observIQ, simplifies monitoring by consolidating data from on-premises virtual machines and multiple cloud providers into a central repository - without extra licensing fees beyond standard cloud observability costs.
For robust monitoring, it's crucial to cover the entire AI stack. This includes components like GPUs, vector databases, and Model Context Protocol (MCP) servers, ensuring that your infrastructure remains consistent no matter where your workloads reside.
Next, let’s look at how AI-driven anomaly detection takes monitoring to the next level.
AI-Driven Anomaly Detection
Manually monitoring AI models often isn’t enough, especially when subtle issues like model drift or degradation arise. This is where AI-powered anomaly detection tools shine. For instance, Vertex AI Model Monitoring identifies training-serving skew and prediction drift by comparing production inputs to baseline data. When anomalies are detected, it can trigger automated retraining to address the issue.
Microsoft Foundry also offers a robust solution. It uses built-in evaluators to measure generative AI quality (like coherence and groundedness) and safety (such as toxicity and protection of sensitive content). These evaluators integrate seamlessly with Azure Monitor, providing real-time dashboards and automated quality checks within CI/CD pipelines.
Another tool, Confident AI (powered by DeepEval), focuses on real-time scoring of production traffic through "online evals." It also enables unit testing of AI applications within CI/CD workflows, helping teams catch issues before deployment. As of early 2026, it performs over 20 million daily evaluations and has seen 3 million monthly downloads.
These advanced tools shift monitoring from a reactive process - fixing problems after they occur - to a proactive one, ensuring consistent model behavior across diverse environments.
Now, let’s explore how NanoGPT adds another layer of consistency for AI models.
Using NanoGPT for AI Model Consistency

To enhance consistency across multiple clouds, NanoGPT offers a practical solution for testing and quality assurance. Designed for teams managing text and image generation workflows, NanoGPT provides access to popular AI models like ChatGPT, Deepseek, Gemini, Flux Pro, Dall-E, and Stable Diffusion. Its pay-as-you-go model - starting at just $0.10 with no subscriptions or hidden fees - makes it an affordable option for teams focused on multi-cloud deployments.
NanoGPT also addresses a major concern in multi-cloud setups: data privacy. By storing data locally on users' devices rather than centralized servers, it helps meet data residency and compliance requirements. Teams can use the service without creating an account, though account-linked balances allow for persistent usage across sessions. This flexibility supports experimentation, enabling developers to compare outputs from various models and ensure consistent results in production.
Together, these tools and techniques create a comprehensive framework for maintaining consistency in multi-cloud environments, from monitoring and anomaly detection to hands-on testing with NanoGPT.
Conclusion: Achieving Multi-Cloud AI Consistency
Steps to Achieve Consistency
Ensuring consistent AI performance across multiple clouds requires a structured approach. Start by using Docker containerization and Kubernetes to standardize deployments. Tools like Infrastructure as Code (e.g., Terraform, Crossplane) can help eliminate configuration drift, while Kubernetes ensures workload portability across platforms.
Next, implement centralized monitoring systems such as Prometheus and Grafana. These tools allow you to track key metrics like inference latency, cost per prediction, and model drift across all cloud environments. To verify consistency, apply a three-tier process that examines tensor-level similarity, activation alignment, and task-level performance metrics.
For cost management, consider using spot instances strategically. Research led by Ziming Mao introduced the "SpotHedge" policy, which cut operational costs by 43% on average while significantly improving latency (P50, P90, and P99) by over two times compared to traditional methods. Finally, simplify routing and fallback logic by using AI gateways like LiteLLM, which provide a single OpenAI-compatible endpoint across multiple providers.
These practices lay a solid groundwork for building reliable and efficient multi-cloud AI systems.
Future Trends in Multi-Cloud AI
Looking ahead, advancements like AI-driven orchestration for dynamic workload routing, edge computing integration via 5G, lightweight Kubernetes distributions, and unified data planes for faster pipeline development are on the horizon. Additionally, conversational infrastructure promises to make multi-cloud management more accessible and efficient.
Final Thoughts
Achieving consistency in multi-cloud AI environments requires treating models as products, complete with defined ownership, roadmaps, and service-level objectives. The strategies outlined - such as Kubernetes standardization and automated drift detection - form the backbone of robust, cost-effective AI systems.
For testing and quality assurance across clouds, tools like NanoGPT offer a practical solution. Starting at just $0.10 with a pay-as-you-go model, NanoGPT supports comparisons between outputs from ChatGPT, Deepseek, Gemini, Flux Pro, Dall-E, and Stable Diffusion. With local data storage for privacy compliance, it’s an excellent resource to ensure consistency before production deployment.
Whether you’re optimizing spot instance usage or implementing centralized observability, the key is to start small, measure results rigorously, and scale successful strategies. These steps empower teams to achieve consistent, scalable AI performance across diverse cloud environments.
FAQs
What causes the same model to produce different outputs across clouds?
Variations in results across different cloud platforms often arise due to non-determinism in large language models (LLMs), even when deterministic settings are applied. Several factors contribute to this, such as differences in hardware, system libraries, software configurations, and runtime environments. On top of that, stochastic processes like sampling methods or floating-point calculations can heighten these inconsistencies. Grasping these elements is essential for reducing deployment noise and maintaining reliable AI performance in multi-cloud environments.
Which consistency metrics should I set SLOs for first in multi-cloud inference?
Start by defining Service Level Objectives (SLOs) for key metrics like model accuracy, output consistency, and drift detection. These benchmarks are crucial for ensuring your AI operates reliably and remains stable, especially when deployed across multi-cloud environments.
How can I test output consistency across providers without exposing sensitive data?
You can ensure output consistency in a secure way by using simulation and environment replication techniques. One effective approach is to create virtual or containerized environments that closely resemble the target platforms. This setup lets you simulate interactions and identify any discrepancies in behavior - all without exposing sensitive data.
Another useful method is automated testing with synthetic or anonymized data. This allows you to evaluate how the model performs across different providers while keeping sensitive information safe. Together, these techniques provide a reliable way to test AI output consistency without compromising data security.