Containerized AI Deployment: Best Practices
Deploying AI at the edge is challenging due to resource constraints, connectivity issues, and diverse hardware. Containers simplify this by packaging AI models and dependencies into portable, consistent units. They enable faster rollouts, better reliability, and improved privacy by processing data locally. Here’s what you need to know:
- Why Containers Matter: They ensure portability, modularity, and scalability across devices like NVIDIA Jetson and cloud-edge platforms.
- Best Practices:
- Use lightweight, AI-optimized base images (e.g.,
python:slimor NVIDIA’scuda:runtime). - Pin dependency versions to avoid environment drift.
- Leverage multi-stage builds to reduce image size and improve security.
- Use lightweight, AI-optimized base images (e.g.,
- Resource Management:
- Set precise CPU/GPU/memory limits to prevent crashes.
- Optimize GPU utilization with quantization and caching techniques.
- Design for offline operation with bundled models and fallback systems.
- Deployment Tips:
- Use OCI-compliant images for consistent performance.
- Automate updates with CI/CD pipelines and tools like ArgoCD.
- Employ rolling or canary deployments for safe updates.
- Security and Observability:
- Harden containers with non-root execution and read-only filesystems.
- Add health checks and monitor GPU metrics to ensure stability.
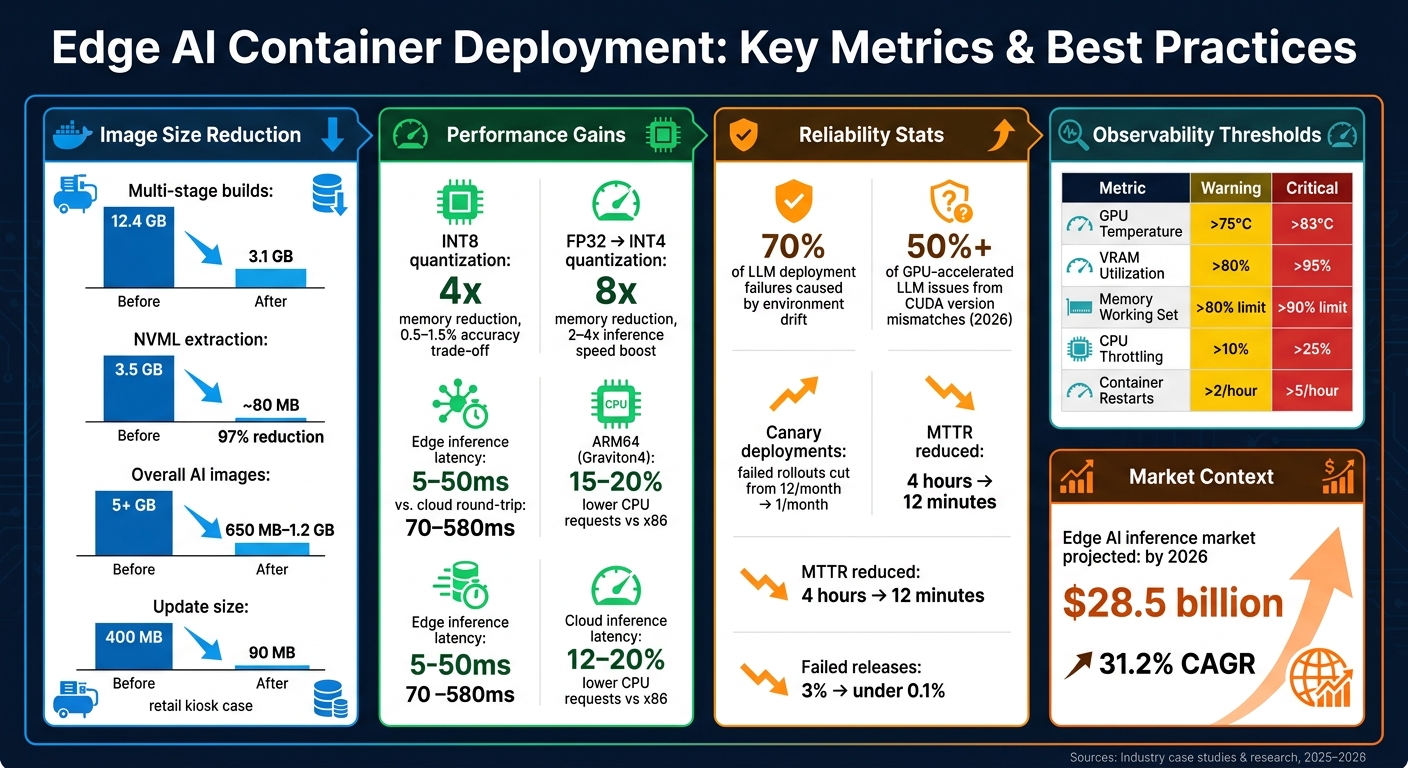
Edge AI Container Optimization: Key Metrics & Best Practices at a Glance
Getting started with Edge AI: Step by step from containerization to deployment | Ask the Expert
sbb-itb-903b5f2
Container Image Design Best Practices
Keeping container images lean is critical, especially for edge devices where every megabyte counts. A bloated image can lead to slower deployments, longer cold starts, and increased security risks. The design choices you make early on directly impact how well your AI workload performs in the field. Here are some practical tips to fine-tune container image design for edge AI workloads.
Use Minimal, AI-Optimized Base Images
Choosing the right base image is a foundational step in containerized AI deployment, particularly for resource-constrained edge devices. The base image sets the minimum size of your final container.
- For CPU-only inference, the
python:slimimage is a great choice. It’s smaller than the full Python image but still supports most AI libraries. - For GPU-accelerated workloads, opt for NVIDIA’s
cuda:runtimeimage instead of thedevelvariant. Thedevelimage includes compilers and headers that are unnecessary at runtime, adding extra weight to your container.
One critical detail: the CUDA version inside your container must match the NVIDIA driver on the host machine. While newer drivers can support older CUDA runtimes, the reverse isn’t true. As of 2026, over half of GPU-accelerated LLM deployment issues were linked to mismatched CUDA toolkits and host drivers. To avoid headaches, always consult NVIDIA’s compatibility matrix before settling on a CUDA version.
"GPU container images are the softest target in your infrastructure." - Pavan Madduri, Senior Cloud Platform Engineer, W.W. Grainger, Inc.
For added security in production, consider using Distroless images. These images strip away unnecessary utilities, reducing the attack surface. Combine them with multi-stage builds to simplify debugging while maintaining a secure runtime environment.
Pin Dependency Versions for Consistency
Consistency is crucial when deploying at the edge. Pinning all dependencies ensures that your runtime environment behaves predictably. A staggering 70% of LLM deployment failures stem from environment drift between development and production. The solution? Pin everything.
- Pin your base image by its SHA256 digest instead of using version tags. For instance,
python:3.11-slim@sha256:abc123...is immutable, whereaspython:3.11-slimcan be silently updated.
"A tag like node:22-alpine can be republished at any time; a digest like node:22-alpine@sha256:abc123... is immutable. This is the difference between your pipeline producing the same artifact tomorrow as it did today and producing something subtly different." - Shadab Khan, Security Engineer, Safeguard
- For Python dependencies, tools like
pip-toolsoruvcan generate lockfiles that freeze the entire dependency tree, not just top-level packages. Usepip install --require-hashesto verify the integrity of these dependencies at install time. - Automate updates with tools like Renovate Bot or Dependabot. This approach lets you control when updates occur, avoiding surprises from upstream changes.
Use Multi-Stage Builds
Multi-stage builds are a game-changer for reducing container image size. This method involves using a build stage to compile your application and then copying only the necessary artifacts into a minimal runtime image. This eliminates the need for compilers, headers, and other build tools in the final image.
A real-world example: In May 2026, Nika Lukava at Veltrix reduced a PyTorch training image from 12.4 GB to 3.1 GB by switching to a CUDA runtime base and leveraging multi-stage builds with the uv package manager. This optimization cut uncached build times from 9 minutes to 5 minutes, with cached builds dropping to just 35 seconds. In another case, Pavan Madduri used a multi-stage build to extract only the required NVML libraries from an NVIDIA base image, shrinking it from 3.5 GB to ~80 MB - a 97% reduction in size and attack surface.
To maximize the benefits of multi-stage builds:
- Place frequently changing instructions, like application code, at the end of the Dockerfile. This keeps stable dependency layers cached.
- Use a
.dockerignorefile to exclude unnecessary files like.git,__pycache__, and local datasets from the build context. - Always switch to a non-root user in the final stage to minimize the risk of container escape vulnerabilities.
These practices not only streamline your container images but also enhance security and performance, making them ideal for edge AI deployments.
Resource Management on Edge Devices
Edge devices operate without the luxury of scalable cloud resources. Missteps in configuration can lead to resource exhaustion, memory crashes, or unpredictable delays - issues that are far tougher to troubleshoot in the field compared to a controlled data center. Below, we'll cover key strategies for resource allocation, GPU tuning, and maintaining connectivity for successful edge AI deployment.
Set Resource Requests and Limits
When deploying AI on edge devices, setting precise resource limits is critical for stability. For AI containers, ensure resource requests match the limits. This assigns the Pod a Guaranteed Quality of Service (QoS) class, shielding it from eviction during memory shortages and preventing overcommitment of CPU cores by the scheduler. Different resources have unique enforcement mechanisms, so it's important to understand how they behave when limits are reached:
| Resource Type | Enforcement Mechanism | Best Practice for Edge AI |
|---|---|---|
| CPU | Throttling (cgroups) | Pin statically; request equals limit |
| Memory | OOM Kill | Profile peak usage; add 5–10% buffer |
| GPU | Device Plugin | Use whole integers; request equals limit |
| Storage | Eviction | Set ephemeral-storage limits for logs/images |
Key considerations: GPU limits must use whole integers, such as nvidia.com/gpu: 1. Fractional values aren't supported by standard plugins and will result in FailedScheduling errors. For memory, don’t just focus on the model size - a 50 MB model can easily consume over 200 MB during runtime due to intermediate activations. Always profile your workload under realistic conditions before finalizing limits.
On ARM64 processors, like AWS Graviton4, you can often reduce CPU requests by 15–20% compared to x86 systems, thanks to their higher efficiency per clock cycle. For nodes with NVLink, configure the kubelet with --cpu-manager-policy=static and --topology-manager-policy=single-numa-node to align CPU allocation with the GPU’s NUMA node, which can significantly reduce latency spikes.
Optimize GPU Utilization
Optimizing GPU usage is essential for efficient edge AI. Quantizing models from FP32 to INT4 can reduce memory usage by 8x and boost inference speed by 2–4x. This can make the difference between a model running smoothly on a device or not fitting at all.
Take this example: In May 2026, the Reachy Mini Jetson Assistant project successfully deployed a multimodal AI pipeline on a Jetson Orin Nano with just 8 GB of unified memory. By disabling the graphical interface (freeing 0.7 GB of DRAM) and applying 4-bit quantization (reducing the vision-language model size from 6.6 GB to 2.2 GB), they kept memory usage to 4.5 GB - well within the device's limits and avoided out-of-memory errors.
Additional tips for GPU optimization:
- Enable TensorRT engine caching (
trt_engine_cache_enable) to prevent lengthy recompilations during restarts. - Run a warm-up inference pass during deployment to stabilize latency before handling live traffic.
- For headless applications, disable the graphical desktop entirely on NVIDIA Jetson devices to recover as much as 865 MB of DRAM.
"Unlike cloud environments, edge devices operate under strict memory limits, with CPU and GPU sharing constrained resources." - Anshuman Bhat, Principal Product Manager, NVIDIA
These GPU strategies work hand-in-hand with methods for addressing connectivity challenges, which we’ll discuss next.
Design for Intermittent Connectivity
Edge devices need to function reliably even when disconnected from the cloud. Design containerized AI workloads with an offline-first approach, treating cloud connectivity as an occasional bonus rather than a necessity.
Here’s how to prepare:
- Bundle all required components (ONNX or TensorRT models, tokenizers, preprocessing pipelines, and configurations) into a single, versioned image.
- For retrieval-augmented generation (RAG) applications, embed lightweight vector stores like FAISS or Hnswlib directly on the device to eliminate reliance on cloud lookups.
- Use differential patching for updates, downloading only what’s changed instead of replacing entire models. Ensure update processes can resume after interruptions without corrupting the running model.
- For air-gapped environments, support updates via encrypted physical media (e.g., USB or SSD), with cryptographic signature checks during loading.
"An offline-first architecture inverts this assumption. The edge device is designed to operate autonomously as its primary mode, with cloud connectivity treated as an occasional enhancement." - SysArt Consulting
To enhance reliability, build a fallback hierarchy into your system. For example:
- Use a full-capability model on the GPU as the primary option.
- Keep a smaller, quantized version ready to run on the CPU as a backup.
- Include a rule-based system as a last resort.
Include metadata in API responses to indicate which fallback tier was used, enabling downstream systems to adapt as needed.
Orchestrating and Deploying AI Containers
Once you've nailed down resource management, the next step is deploying containers reliably across edge devices. Orchestrating at the edge isn’t the same as doing it in the cloud - it needs a more streamlined approach and the right tools to make it work. These strategies build on the container and resource management practices we’ve already covered.
Use OCI-Compliant Images
When building container images, following Open Container Initiative (OCI) standards ensures your containers perform consistently across diverse edge platforms, whether it’s an NVIDIA Jetson, Raspberry Pi, or industrial gateway. OCI compliance doesn’t just guarantee reliability - it also reduces container sizes drastically, from 50–500 MB to just 1–10 MB. That’s a game-changer, especially for edge nodes connected via cellular or satellite links.
"OCI artifacts fundamentally change the economics of GitOps at the edge... bandwidth requirements drop by an order of magnitude while security improves." - Nawaz Dhandala, Senior Engineer
For orchestration, lightweight Kubernetes distributions like K3s, k0s, or MicroK8s are a perfect fit for hardware with limited resources. For instance, K3s is a single binary under 100 MB that includes all essential Kubernetes components, making it ideal for devices with constrained RAM. Pair this with a GitOps workflow using tools like Flux CD or ArgoCD to ensure edge clusters stay in sync with a central repository, even after being offline for extended periods.
Use Rolling and Canary Deployments
Once you’ve ensured OCI compliance, you’ll want to roll out updates carefully to avoid disruptions. Canary deployments are a smart way to start - send a small percentage of traffic to the new model, validate its performance, and only roll it out fleet-wide once it’s proven reliable. Shadow deployments are another option, running the new model alongside the current one to process live traffic without affecting users, allowing risk-free testing.
Here’s a real-world example: In 2026, a warehouse logistics company managing 2,000 kiosks adopted a GitOps-driven canary deployment strategy for their OCR models. By caching previous versions for quick rollbacks and automating triggers based on performance metrics, they cut failed rollouts from 12 per month to just 1 and reduced their mean time to recover (MTTR) from 4 hours to just 12 minutes.
For AI workloads, it’s important to set terminationGracePeriodSeconds to at least 60–120 seconds. This ensures that active processes finish before pods shut down during updates. Tools like Argo Rollouts or Flagger can automate performance analysis and trigger rollbacks if error rates or latency exceed acceptable limits.
Automate Build and Deployment Pipelines
When managing hundreds - or even thousands - of edge nodes, manual deployment just isn’t practical. A fully automated CI/CD pipeline can handle the building, scanning, signing, and deployment of AI workloads, catching issues before they hit production.
One key strategy is separating model artifacts from runtime container images. Store large model weights in shared storage (like NFS, S3, or a local SSD cache) and mount them at runtime. This keeps images lightweight and reduces update sizes. For example, in 2026, a retail kiosk team managing 1,200 Raspberry Pi 5 devices used this approach to shrink their average update size from 400 MB to 90 MB. They also cut failed releases from 3% to under 0.1%. Their pipeline even caught a quantization regression that could have increased latency by 2.5× before it reached production.
Adding automated security gates to your pipeline is another must. Tools like Docker Scout can scan for vulnerabilities (CVEs) and block risky images, while automated signing ensures the integrity of your builds.
"The zero-trust pipeline adds ~2 minutes to your CI build. The alternative is finding out about a critical CVE from your security team after it's been running in production for three weeks." - Pavan Madduri, Senior Cloud Platform Engineer
Reliability, Observability, and Security
Ensuring reliable and secure container orchestration at the edge is critical, especially when handling AI workloads. Let’s break it down into health checks, security hardening, and observability.
Set Up Health Checks
Kubernetes provides three types of probes: Startup, Liveness, and Readiness. Each serves a specific role in monitoring container health. For AI workloads, the Startup probe is particularly important. Be sure to set its timeout to align with the 30–60 second load time typical for AI models. This prevents the Liveness probe from mistakenly terminating the container during startup.
- Use shallow checks (e.g., basic HTTP 200 or TCP accept) for routing traffic through load balancers.
- Reserve deep checks (e.g., database or dependency connectivity) for internal alerts only. This avoids unnecessary service outages caused by minor dependency hiccups.
If you're using Triton Inference Server, take advantage of its /v2/health/ready endpoint for Readiness probes instead of relying on generic HTTP checks. Additionally, for Alpine-based images, explicitly configure health checks to use 127.0.0.1 rather than "localhost." This avoids IPv6 resolution issues that could cause intermittent failures.
"A health check answers one question: 'should this instance receive traffic right now?' Get it wrong and you cause more outages than you prevent." - HLD Handbook
Once health checks confirm readiness, focus on securing your containers to guard against potential threats.
Harden Edge Security
Edge nodes face unique challenges, including physical vulnerabilities. Strengthen container security with these baseline measures:
- Enforce non-root execution for all containers.
- Set
allowPrivilegeEscalation: falseto block privilege escalation. - Drop all unnecessary Linux capabilities using
cap_drop: [ALL]. - Configure the root filesystem as read-only.
To ensure only verified images are deployed, cryptographically sign images with Cosign and enforce signature checks at the admission controller level using tools like Kyverno or OPA Gatekeeper. The importance of these steps was highlighted during the "NVIDIAScape" vulnerability (CVE-2025-23266) in July 2025, which exploited a simple three-line Dockerfile and affected 37% of cloud GPU environments running older versions of the NVIDIA Container Toolkit.
For multi-tenant GPU workloads, consider using NVIDIA Multi-Instance GPU (MIG) to enforce hardware-level memory isolation, reducing the risk of cross-workload interference.
"The convergence of Kubernetes and AI creates a perfect storm. GPU nodes present unique vulnerabilities." - perfecXion Research Team
With security measures in place, the next step is to ensure your containers are observable for real-time monitoring and troubleshooting.
Add Observability Instrumentation
Observability is key to maintaining performance and identifying potential issues. Focus on these four critical metrics: tokens per second, GPU temperature, VRAM usage, and request latency. To capture GPU-specific metrics efficiently, deploy the NVIDIA DCGM Exporter as a sidecar. This lightweight tool consumes minimal resources (300 MB memory and 0.5% GPU usage). Monitoring these metrics can prevent issues like thermal throttling, which can slash AI throughput by 40–60% if left unchecked.
- Track
memory_working_set_bytesto monitor actual memory usage against limits. This is the metric Kubernetes uses to make Out-Of-Memory (OOM) kill decisions. - Set Prometheus scrape intervals to 15 seconds. Scraping too frequently (e.g., every second) can overload the DCGM exporter and create noisy data.
- Use Fluent Bit to enrich container logs with Kubernetes metadata before forwarding them to centralized systems like OpenSearch or Loki.
Here’s a quick reference table for key metrics and thresholds:
| Metric | Warning | Critical | Action |
|---|---|---|---|
| GPU Temperature | > 75°C | > 83°C (consumer) / > 88°C (workstation) | Check cooling; throttling likely |
| VRAM Utilization | > 80% | > 95% | Reduce batch size or context length |
| Memory Working Set | > 80% of limit | > 90% of limit | Fix memory leaks or increase limits |
| CPU Throttling % | > 10% | > 25% | Increase CPU limits or optimize code |
| Container Restart Count | > 2/hour | > 5/hour | Check logs for crash root cause |
Together, health checks, security hardening, and observability create a strong foundation for reliable and secure edge deployments. By keeping a close eye on these metrics and implementing best practices, you can minimize risks and ensure smooth operations.
Managing AI Models and Data in Containers
Efficiently managing AI models and data is just as important as securing and monitoring containers. It helps reduce image size and protects sensitive information.
Store Model Artifacts Outside the Container
Don't embed model weights directly in the container image. Instead, store them externally - think services like S3 or GCS. This way, updating code won't force you to rebuild the entire image.
"Decouple: Code changes frequently. Weights change rarely. Keep them separate." - Aditya Somani
A smart move is using a Kubernetes initContainer to pull model artifacts into a shared volume before the main container runs. Teams have seen dramatic improvements here: CI build times dropping from over 40 minutes to just 3, and model cold-start times shrinking from 4 minutes to under 10 seconds when leveraging local NVMe caching. For production environments, mount these volumes as read-only to ensure data remains unaltered.
For large models like Falcon-40B, you can package weights as OCI artifacts using the ModelCar pattern. This approach involves placing model files in a /models folder inside a dedicated container without runtime code. It can cut build times from nearly 2 hours to just minutes. Also, use Zstd compression instead of gzip. While downloading data only accounts for about 30% of container pull time, decompression is the real bottleneck - and Zstd is much faster.
Once you've set up external storage, the next step is choosing the right model format for compatibility across different hardware.
Use Portable Model Formats
After separating model weights, selecting a portable format ensures better performance across various platforms. The format you choose impacts how well your model runs on specific hardware.
| Format | Ideal For | Key Advantage |
|---|---|---|
| ONNX | Mixed GPU/NPU/CPU environments | High interoperability; graph optimization |
| GGUF | LLMs on CPU-only or Raspberry Pi devices | Efficient quantization for low-RAM hardware |
| TFLite | Mobile and embedded sensors | Lightweight; broad mobile support |
| TorchScript | PyTorch-native production stacks | High performance within the PyTorch ecosystem |
For CPU-heavy edge devices, GGUF is an excellent option. For instance, a quantized 3B model running on a Raspberry Pi 5 with an AI HAT can generate 3–8 tokens per second. On the other hand, ONNX or TorchScript is better suited for GPU-equipped edge racks. A utilities company demonstrated this in 2025 by deploying Raspberry Pi devices with a 3B quantized GGUF model for offline inspections, cutting field engineer report times by 45%.
Protect Sensitive Data
With model storage and formats sorted, securing sensitive data becomes the next priority. Avoid embedding API keys, credentials, or user data directly in the container image. Instead, rely on an Agent Vault or a credential proxy to handle outbound requests, ensuring that real API keys never touch the container's environment, files, or memory. For filesystem access, use strict allowlists and block sensitive directories like .ssh, .aws, and .env. You can take extra precautions by mounting /dev/null over sensitive files, so they're inaccessible even if mistakenly included in a mount.
For scenarios where data privacy is critical - such as proprietary sensor logs or user inputs - an offline-first design is a smart approach. For example, NanoGPT prioritizes user privacy by storing data locally on devices rather than sending it to external servers. A well-designed edge container should operate without any internet access after the initial build, keeping all data confined to the local machine. For even greater security, hardware-level isolation using Trusted Execution Environments (TEEs) like AMD SEV-SNP or Intel TDX can encrypt data in memory during processing, adding another layer of protection.
Conclusion
Deploying Edge AI is fundamentally an operations challenge. As Rogue AI, an independent AI systems engineer, aptly explained: "Getting a model to run where real traffic hits - reproducible, observable, locked down, restart-safe - is a security and operations problem before it is an AI one." Every step in the deployment process, from multi-stage builds to health checks and signed image verification, is designed to ensure reliable performance when it’s needed most.
The numbers back up these practices. Multi-stage builds can reduce AI image sizes from over 5 GB to approximately 650 MB–1.2 GB. INT8 quantization slashes memory usage by 4x, typically with only a 0.5–1.5% accuracy trade-off. Running inference on local accelerators at the edge achieves speeds of 5–50ms, compared to the 70–580ms required for a cloud round-trip. These optimizations can mean the difference between a responsive system and one that struggles under real-world conditions.
Processing data locally also brings privacy and compliance benefits, making adherence to regulations like GDPR more straightforward while reducing the risk of data breaches. Combine that with distroless images, non-root containers, and signed image verification, and you’ve built a deployment that’s secure from the ground up.
The market trends further emphasize the importance of these strategies. The edge AI inference market is projected to hit $28.5 billion by 2026, with a compound annual growth rate of 31.2%. Organizations that approach edge deployment with the precision of disciplined engineering are better equipped to scale reliably across dozens, hundreds, or even thousands of nodes. By following these best practices, your edge deployments can achieve the scalability and reliability needed to thrive.
FAQs
How do I avoid CUDA and NVIDIA driver mismatches in containers?
To avoid compatibility issues, make sure the host driver is updated and matches your container's CUDA version. Instead of installing drivers within the container, use the NVIDIA Container Toolkit to bind-mount the host’s driver. When running your container, set the runtime appropriately, like using --runtime=nvidia. For custom images, you can enforce version checks by using the NVIDIA_REQUIRE_CUDA environment variable. This ensures the container won’t run if the host driver doesn’t meet the required specifications.
What’s the best way to ship AI models for offline edge devices?
To deploy AI models on offline edge devices, you’ll need to create secure, portable artifact bundles that can be transferred using physical media like USB drives or optical disks. Here’s how you can do it:
- Sign and verify models: Use checksums like SHA-256 to sign the models and verify their authenticity.
- Package dependencies: Include all necessary files and dependencies in a single bundle to simplify deployment.
- Ensure integrity: Perform verification steps to confirm the bundle hasn’t been tampered with before deploying it locally.
These steps make it possible to securely and reliably deploy AI models even in air-gapped environments, ensuring the process is tamper-proof.
Which metrics should I monitor first for GPU inference stability?
Monitoring GPU utilization (DCGM_FI_DEV_GPU_UTIL) and GPU memory usage (DCGM_FI_DEV_FB_USED) is crucial. These metrics offer valuable insights into how well your resources are performing and can help identify bottlenecks. Keeping an eye on them ensures your GPU inference remains stable, especially in containerized setups.