
Scaling AI Validation Across Data Centers
Unified blueprint to validate models, data, and infrastructure across regions with shared metrics, gates, chaos tests, and ownership.
Updates, guides, and insights from the NanoGPT team
Showing
Unified blueprint to validate models, data, and infrastructure across regions with shared metrics, gates, chaos tests, and ownership.

Real-time AI apps only succeed when streaming speed, tight prompts, regional deployment, and governance are built together.
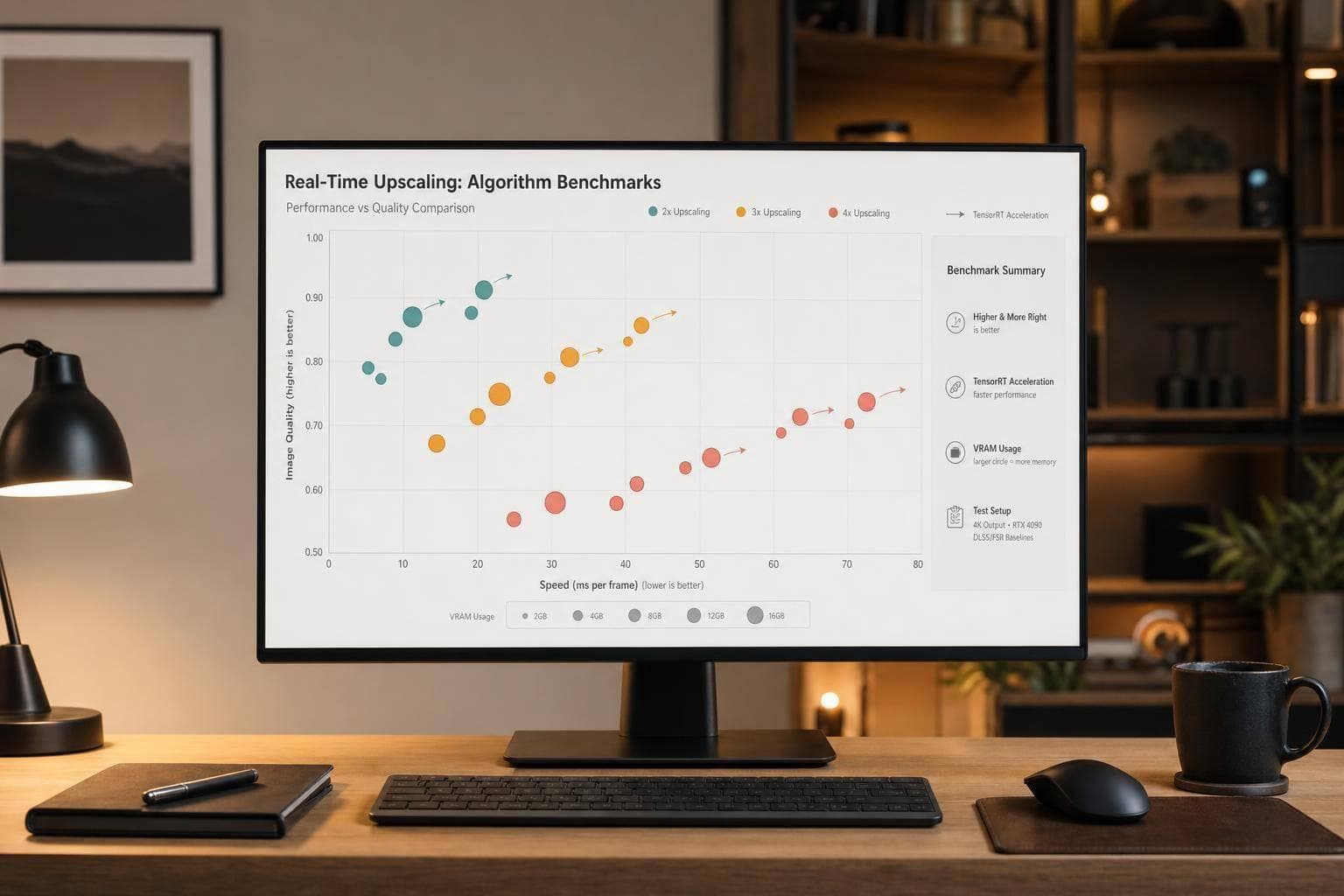
Compare upscaling models by speed vs. quality: latency, PSNR/SSIM/LPIPS, VRAM needs, and TensorRT speedups for 2x–4x.

Federated image training forces trade-offs between privacy, image quality, and system cost; algorithm choice determines the balance.

Nanoodle lets you share NanoGPT workflows that users can open, sign in to, and run with their own NanoGPT balance.

Workload-based AI server refresh: training 1–3 yrs, inference 3–7 yrs. Replace when utilization, failure risk, power, or support justify it.

Sofya is now available on NanoGPT as a web search provider and as the Sofya Research model, bringing page-content search, URL fetching, AI extraction, and multi-source research into one workflow.

Match sparse formats (COO/CSR/CSC) to solver and hardware to cut memory, speed SpMV-heavy solvers, and simplify assembly.

Choose dataset types, separate transforms, tune DataLoader settings, and save metadata to avoid GPU stalls and ensure reproducible runs.

Cloud looks cheap on day one, but local storage often wins for long-term multi‑TB AI retention — lower costs, faster access, more privacy.