
OAuth vs OpenID Connect in AI Platforms
Compare OAuth 2.0 and OpenID Connect for AI platforms: OAuth handles authorization; OIDC provides authentication for secure agents and APIs.
Updates, guides, and insights from the NanoGPT team
Showing
Compare OAuth 2.0 and OpenID Connect for AI platforms: OAuth handles authorization; OIDC provides authentication for secure agents and APIs.

Best practices for session tokens: short-lived access tokens, refresh rotation, CAE, and meeting NIST/PCI compliance.

Overview of major OOD benchmarks, failure modes, and methods to improve robustness across vision, time-series, and sensor models.

One AI fuels creative lesson design; the other streamlines research and Google Workspace workflows.

AI detects scratches, inpaints missing areas, restores color and sharpness, and delivers fast, low-cost photo restoration.

Five async techniques—gather, as_completed, semaphores, async RLHF, and batch inference—to cut AI latency and scale LLM workloads.

Guide to adversarial regularization: min-max training, FGSM vs PGD, implementation tips, trade-offs, and best practices for robust models.

Compare CPUs, GPUs, TPUs, NPUs and FPGAs to choose the best hardware for AI training, inference, cost, and energy efficiency.

How self-, cross-, and joint-attention power Stable Diffusion, plus efficiency trade-offs and advances for high-res image generation.
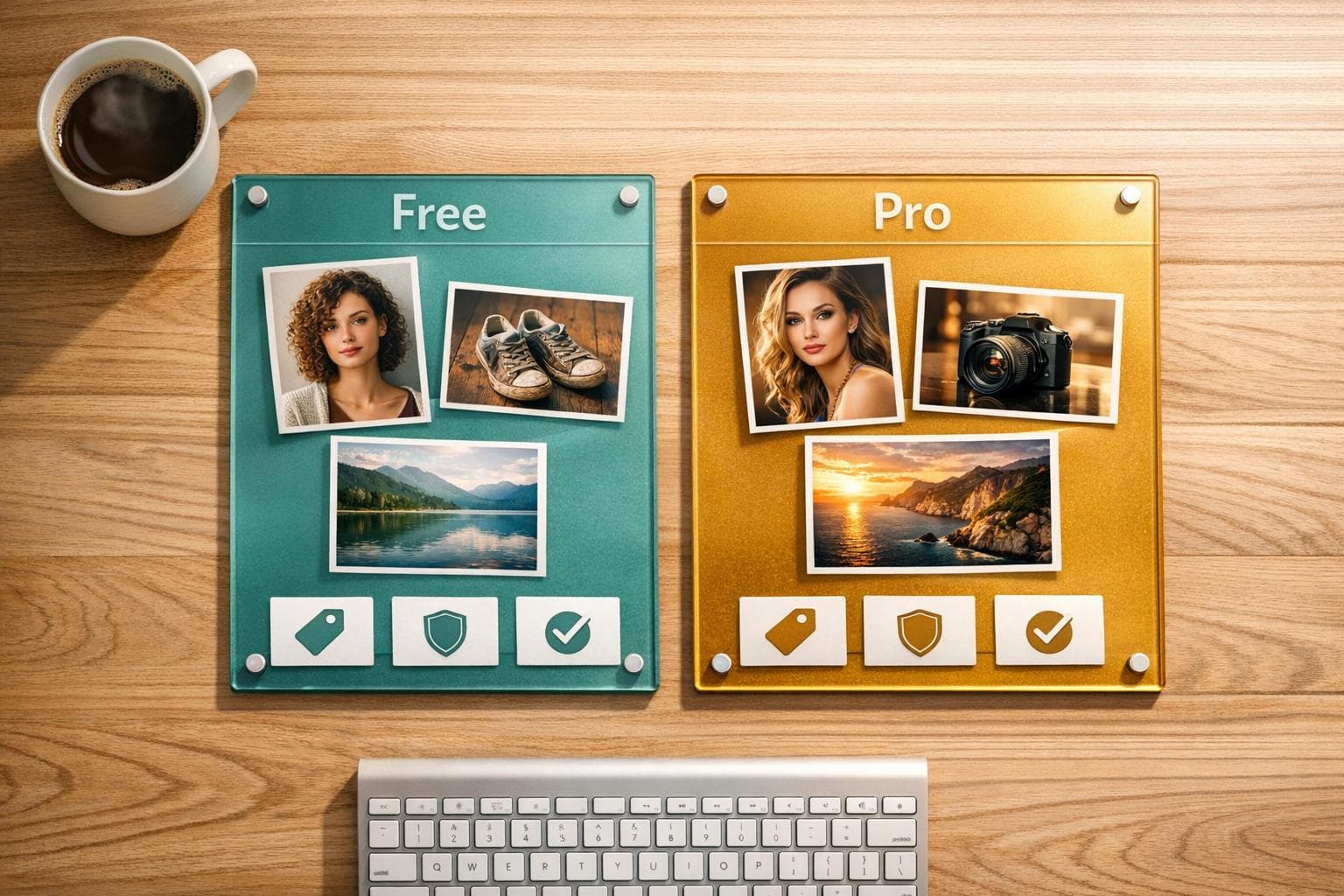
Compare top free and paid AI image generators in 2026 — features, pricing, privacy, and best use cases.